每日学术速递6.7
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.The ObjectFolder Benchmark: Multisensory Learning with Neural and Real Objects(CVPR 2023)

标题:ObjectFolder 基准测试:使用神经和真实对象进行多感官学习
作者:Ruohan Gao, Yiming Dou, Hao Li, Tanmay Agarwal, Jeannette Bohg, Yunzhu Li, Li Fei-Fei, Jiajun Wu
文章链接:https://arxiv.org/abs/2306.00956
项目代码:https://objectfolder.stanford.edu/
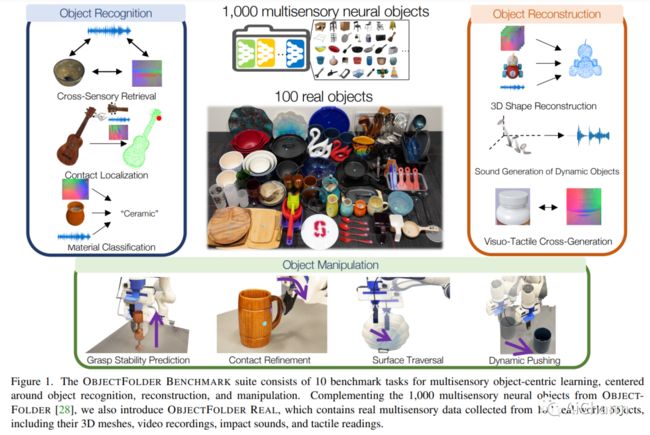


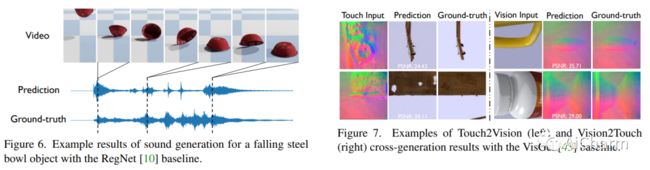
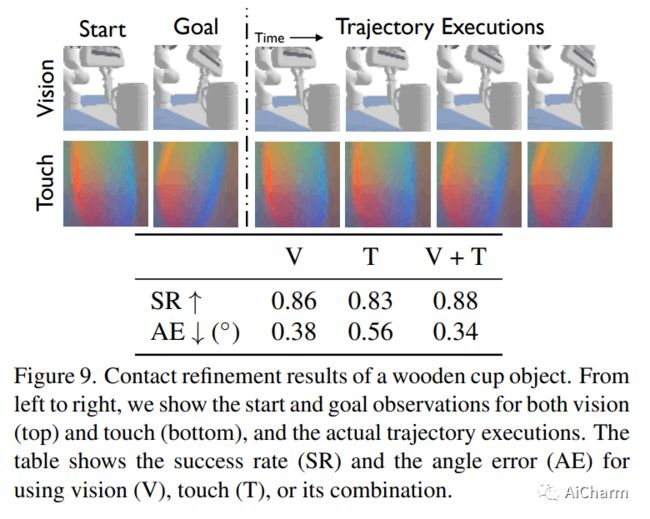
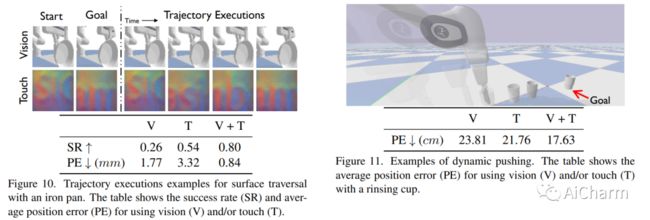
摘要:
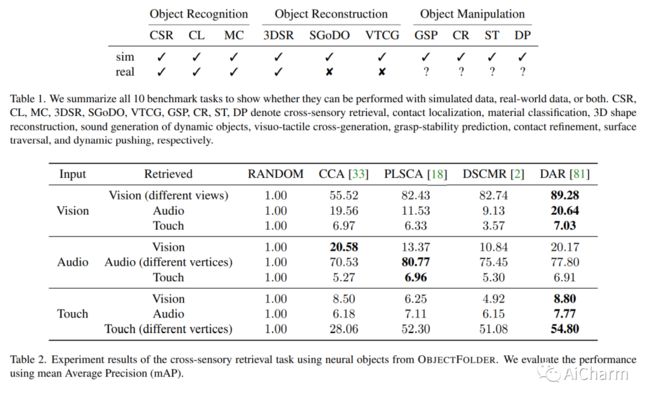
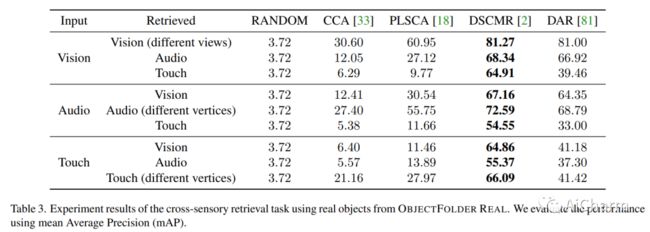
我们介绍了 ObjectFolder Benchmark,这是一个包含 10 个任务的基准套件,用于以对象为中心的多感官学习,以对象识别、重建和视觉、声音和触觉操作为中心。我们还介绍了 ObjectFolder Real 数据集,包括对 100 个真实世界家庭物体的多感官测量,建立在一个新设计的管道之上,用于收集真实世界物体的 3D 网格、视频、撞击声音和触觉读数。我们对来自 ObjectFolder 的 1,000 个多感官神经对象和来自 ObjectFolder Real 的真实多感官数据进行了系统的基准测试。我们的结果证明了多感官感知的重要性,并揭示了视觉、听觉和触觉在不同的以对象为中心的学习任务中的各自作用。通过公开发布我们的数据集和基准套件,我们希望能够促进和推动计算机视觉、机器人等领域以多感官对象为中心的学习的新研究。
2.StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners

标题:StableRep:来自文本到图像模型的合成图像使强大的视觉表示学习者
作者:Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, Dilip Krishnan
文章链接:https://arxiv.org/abs/2306.00984




摘要:
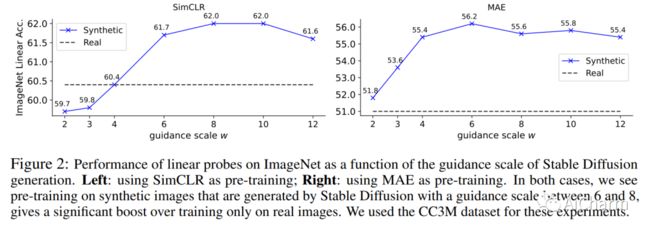
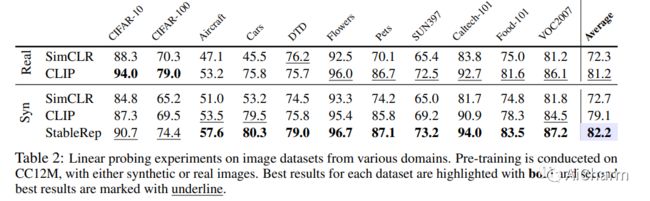
我们研究了使用由文本到图像模型生成的合成图像来学习视觉表示的潜力。鉴于此类模型在生成高质量图像方面的出色性能,这是一个自然而然的问题。我们特别考虑了 Stable Diffusion,它是领先的开源文本到图像模型之一。我们表明(1)当生成模型配置了适当的无分类器指导尺度时,在合成图像上训练自监督方法可以匹配或击败真实图像对应物;(2) 通过将同一文本提示生成的多个图像相互视为正例,我们开发了一种多正例对比学习方法,我们称之为 StableRep。仅使用合成图像,StableRep 学习的表示在大规模数据集上超过了 SimCLR 和 CLIP 使用同一组文本提示和相应的真实图像学习的表示的性能。当我们进一步添加语言监督时,使用 20M 合成图像训练的 StableRep 比使用 50M 真实图像训练的 CLIP 获得更好的准确性。
3.NeRO: Neural Geometry and BRDF Reconstruction of Reflective Objects from Multiview Images(SIGGRAPH 2023)

标题:ImageReward:学习和评估人类对文本到图像生成的偏好
作者:Yuan Liu, Peng Wang, Cheng Lin, Xiaoxiao Long, Jiepeng Wang, Lingjie Liu, Taku Komura, Wenping Wang
文章链接:https://arxiv.org/abs/2305.17398
项目代码:https://github.com/liuyuan-pal/NeRO


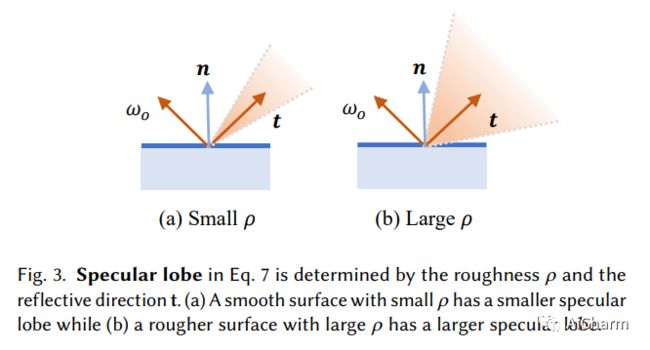
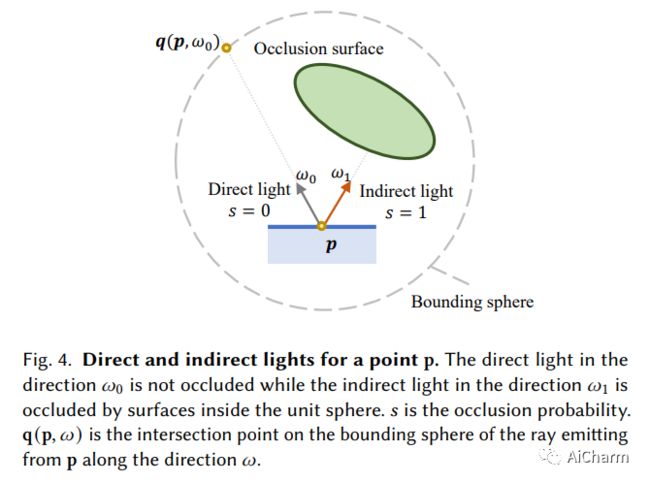
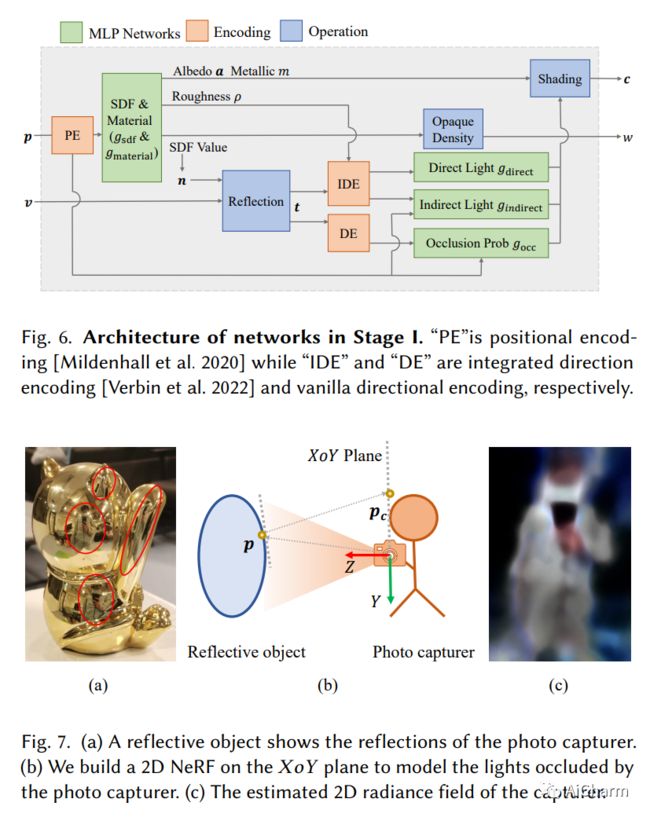
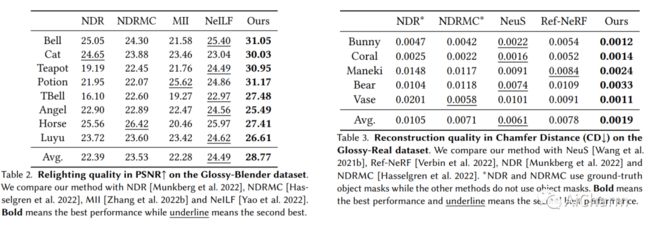
摘要:
我们提出了一种称为 NeRO 的基于神经渲染的方法,用于从在未知环境中捕获的多视图图像重建反射物体的几何形状和 BRDF。反射物体的多视图重建极具挑战性,因为镜面反射依赖于视图,因此违反了多视图一致性,而多视图一致性是大多数多视图重建方法的基石。最近的神经渲染技术可以对环境光和物体表面之间的相互作用进行建模,以适应视点相关的反射,从而使从多视点图像重建反射物体成为可能。然而,在神经渲染中准确地建模环境光是很棘手的,尤其是当几何形状未知时。大多数现有的可以对环境光进行建模的神经渲染方法仅考虑直射光并依靠对象遮罩来重建镜面反射较弱的对象。因此,这些方法无法重建反射物体,尤其是当物体掩模不可用且物体被间接光照亮时。我们提出了一个两步走的方法来解决这个问题。首先,通过应用分裂和近似和集成方向编码来近似直射光和间接光的阴影效果,我们能够在没有任何物体遮罩的情况下准确地重建反射物体的几何形状。然后,在物体几何形状固定的情况下,我们使用更精确的采样来恢复环境光和物体的 BRDF。大量实验表明,我们的方法能够在不知道环境光和物体遮罩的情况下,仅从摆好的 RGB 图像中准确地重建反射物体的几何形状和 BRDF。
更多Ai资讯:公主号AiCharm