聚类Clustering方法定位船舶站点
背景
现有船舶的航线中采样的数据库,采样的总时长为3个月,仅采样航速静止(小于1节)的数据,关键有效数据主要有经纬度/实时吃水量。
思路
基于站点附近轮船有停靠且航行速度慢,故取样点多的基础认识,计划使用聚类方法定位LNG站点位置,并基于船舶吃水量的变化判断站点的属性:进口/出口/停泊。
Step 1: 数据预处理
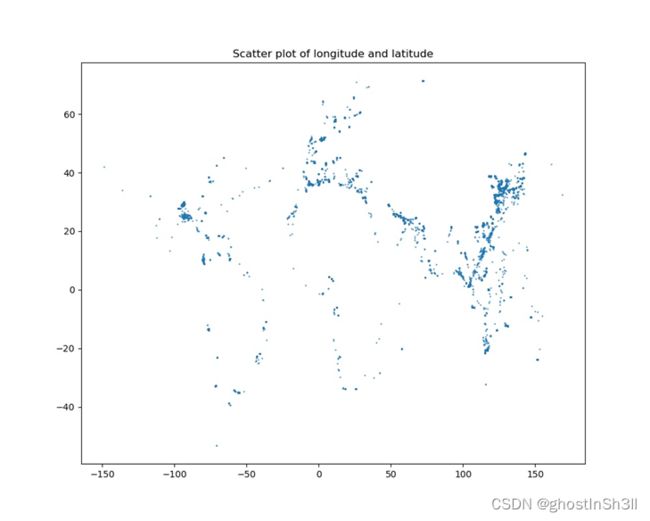
基于原始数据文件中的关键数据,分别对应经度(long)、纬度(lati)、吃水量(draft)。数据中相邻若干行两两之间若基于经纬度计算得到的距离小于5千米,则将这些数据视为同一个坐标点,位置信息存在取样误差,位置信息(经度、维度)取均值得到;若相邻行计算距离大于5km,则两个数据视为不同的有效坐标点。至此,位置信息处理完毕,后续基于吃水量变化情况判断船只行为。如果吃水量变大,则船只货物增多,标记为1,表示进站;反之如果吃水量减小,则船只货物减少,标记为-1,表示出站;若吃水量不变,则船只货物不变,标记为0,即船只正常航行或停泊。本段具体代码如下所示,
for i in range(len(df)):
cur_pt = [df.loc[i, attr] for attr in attr_list]
# 5000m / 5km
if haversine_distance(cur_pt,temp_pt) < 5: # not include into data, the position of adjacent line (in df) is so close, that regard it as the same position
avg_pt[0] += cur_pt[0]
avg_pt[1] += cur_pt[1]
if cur_pt[2] != 0: # draft != 0
draft_valid.append(cur_pt[2])
temp_pt = cur_pt
count += 1
else: # include into data
if count != 0:
data['long'].append(avg_pt[0] / count)
data['lati'].append(avg_pt[1] / count)
if len(draft_valid)>0:
dif = draft_valid[-1]-draft_valid[0]
if(dif>1):
data['behavior'].append(1) # more carriage, 1
elif(dif<-1):
data['behavior'].append(-1) # less carriage, -1
else:
data['behavior'].append(0) # carriage unchanged
else:
data['behavior'].append(0)
count = 0
avg_pt = [0,0]
temp_pt = cur_pt
draft_valid = []可视化结果如下所示,
Step 2: 聚类算法
在得到航迹中不同坐标的行为之后,计划采用聚类方法计算LNG站点位置。下面简要介绍各个算法的细节以及参数设置。
算法1:DBSCAN
DBSCAN定义的簇可以是任意形状,每个簇由一组彼此接近的核心样本组成。簇之外是一组与核心样本接近的非核心样本。定义核心样本的方式是数据集中一个样本的eps距离范围内,存在min_samples 个其他样本。任何不是核心样本并且和任意一个核心样本距离都大于eps 的样本将被视为异常值。min_samples取值越高或eps取值越低都表示形成簇的密度越高。
times = []
for i in range(10): # Simulate for 10 times, and calculate the average run time
start_time = time.time()
# Model Training
clustering_dbscan = DBSCAN(eps=0.05, min_samples=3).fit(coord)
run_time = time.time() - start_time # Unit: s
times.append(run_time)
dic = results_process(clustering_dbscan, data, "DBSCAN", results_folder)
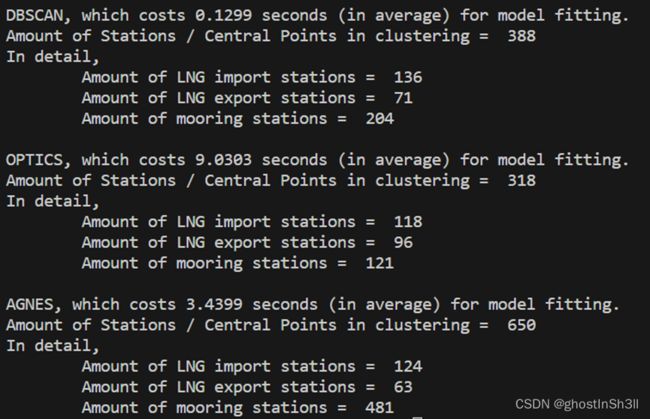
print("\nDBSCAN, which costs {:.4f} seconds (in average) for model fitting.".format(sum(times)/len(times)))
print("Amount of Stations / Central Points in clustering = ", len(set(clustering_dbscan.labels_)) - (1 if -1 in clustering_dbscan.labels_ else 0))
print("In detail,")
print("\tAmount of LNG import stations = ", len(dic["import"]))
print("\tAmount of LNG export stations = ", len(dic["export"]))
print("\tAmount of mooring stations = ", len(dic["mooring"]))算法2:OPTICS
OPTICS算法是DBSCAN算法的推广,基本思路一致,主要变化是将eps从取值放宽至某个范围。因为OPTICS的eps为一个范围,所以计算拟合数据的时间远超DBSCAN算法。
算法3:AGNES
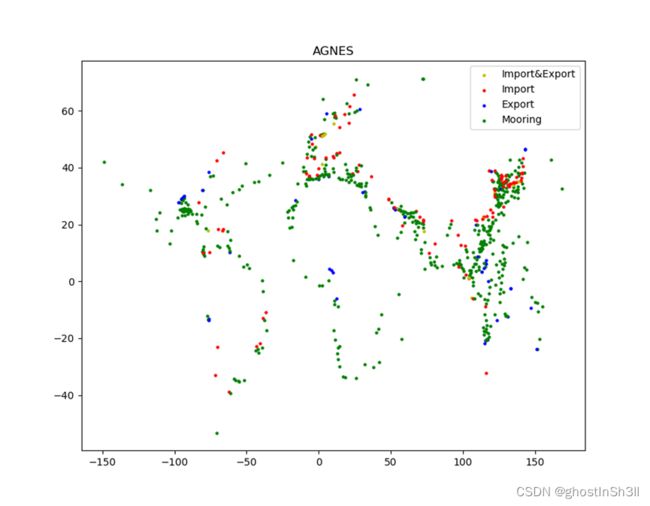
AGNES属于层次聚类方法,采用自底向上的策略,最初将每个对象作为一个簇,然后簇根据准则逐步合并,两个簇间的距离由两个簇中距离最短的数据点的相似度确定,合并过程不断反复进行直到所有对象满足簇数目n_clusters。结合本例实际,n_clusters设为650,探索不同数目的LNG站点分布,并兼顾模型性能。
聚类定位LNG站点的实验结果如下所示, 包含DBSCAN、OPTICS、AGNES三种聚类算法拟合数据效率、LNG站点的各项统计数据
基于AGNES聚类算法得到的LNG站点的可视化结果和json存档文件(部分)如下所示,

后续工作
后续可以基于现有库定位站点的所属国家或地区。