Java解析String类的使用及String a = b + “c“面试题
1.概述
String:字符串,使用一对""引起来表示。
1.String声明为final的,不可被继承
2.String实现了Serializable接口:表示字符串是支持序列化的。
实现了Comparable接口:表示String可以比较大小
3.String内部定义了final char[] value用于存储字符串数据
4.通过字面量的方式(区别于new给一个字符串赋值,此时的字符串值声明在字符串常量池中)。
5.字符串常量池中是不会存储相同内容(使用String类的equals()比较,返回true)的字符串的。
2.String的不可变性
2.1 说明
1.当对字符串重新赋值时,jvm需要重写指定内存区域赋值,不能使用原有的value进行赋值。因为原有的value是final的
2.当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
3.当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
2.2 代码举例
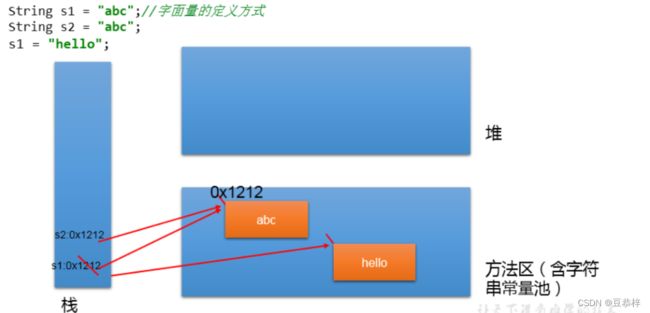
String s1 = "abc";//字面量的定义方式
String s2 = "abc";
s1 = "hello";
System.out.println(s1 == s2);//比较s1和s2的地址值
System.out.println(s1);//hello
System.out.println(s2);//abc
System.out.println("*****************");
String s3 = "abc";
s3 += "def";
System.out.println(s3);//abcdef
System.out.println(s2);
System.out.println("*****************");
String s4 = "abc";
String s5 = s4.replace('a', 'm');
System.out.println(s4);//abc
System.out.println(s5);//mbc
2.3 图示
3.String实例化的不同方式
3.1 方式说明
方式一:通过字面量定义的方式
方式二:通过new + 构造器的方式
3.2 代码举例
//通过字面量定义的方式:此时的s1和s2的数据javaEE声明在方法区中的字符串常量池中。
String s1 = "javaEE";
String s2 = "javaEE";
//通过new + 构造器的方式:此时的s3和s4保存的地址值,是数据在堆空间中开辟空间以后对应的地址值。
String s3 = new String("javaEE");
String s4 = new String("javaEE");
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s1 == s4);//false
System.out.println(s3 == s4);//false
3.3 面试题
String s = new String(“abc”);方式创建对象,在内存中创建了几个对象?
两个:一个是堆空间中new结构,另一个是char[]对应的常量池中的数据:“abc”
3.4 图示 new的方式 :字符串的值还是在常量池中,只不过在堆中创建的空间内存指向常量池。


 注意:这里p1和p2的地址不同,但是p1和p2的name都指向了常量池中的Tom。
注意:这里p1和p2的地址不同,但是p1和p2的name都指向了常量池中的Tom。
4. 字符串拼接方式赋值的对比
4.1 说明
- 1.常量与常量的拼接结果在常量池。且常量池中不会存在相同内容的常量。
- 2.只要其中一个是变量,结果就在堆中。
- 3.如果拼接的结果调用intern()方法,返回值就在常量池中。详细看JVM的intern用法
所有的字符串常量(类似于: “a” + “b”)的拼接,jvm都会把它优化,直接变成ab常量,所以中途不会创建"a", "b"两个对象。
public class TestStringVariableAndConstants {
public static void main(String[] args) {
String a = "abc";
String b = "ab";
String c = "c";
String q = b+c;
String z = b+"c";
System.out.println(a==q);//false
System.out.println(a==z);//false
String d = "def";
String e = "d"+"ef";
System.out.println(d==e);//true
}
}
java中的==对于引用类型比较的是地址。
1.当+号一边存在字符串变量时,则先回寻找字符串常量池中是否存在已经拼接好的字符串。
如果不存在,则会在里面创建一个新的
然后在堆中创建一个指向这个常量的对象。 如下图:
2.当+号两边都是字符串常量时,则先寻找字符串常量池中是否存在已经拼接好的字符串。
如果不存在,则会在里面创建一个新的字符串 不会在堆中创建新的对象

4.2 代码举例
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//false
System.out.println(s5 == s6);//false
System.out.println(s5 == s7);//false
System.out.println(s6 == s7);//false
String s8 = s6.intern();// s8指向常量池 中S6指向的常量
System.out.println(s3 == s8);//true 和s3指向一个地址 都是 javaEEhadoop
****************************
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop";
System.out.println(s1 == s3);//false
特殊:
final字符串进行拼串后是否相等
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = "hello";
String c = b + 2;
String d = "hello";
String e = d + 2;
// 等同于 new StringBuilder().append(d).append(2).toString();在堆中开辟地址了 上面图中有讲到
System.out.println((a == c));// true
System.out.println((a == e));// false
}
}
我们分析字节码可以看到,使用final定义的字符串在使用 ‘+’ 进行拼接字符串时,会到字符串常量池中加载;
没有使用 final 定义的字符串在使用 ‘+’ 进行拼接字符串时,会先创建 StringBuilder 类,
然后通过调用类中 append 方法进行添加字符串,最后通过 toString 方法转为字符串,而 toString 方法是直接在堆中创建 String 对象。
5.常用方法:
int length():返回字符串的长度: return value.length
char charAt(int index): 返回某索引处的字符return value[index]
boolean isEmpty():判断是否是空字符串:return value.length == 0
String toLowerCase():使用默认语言环境,将 String 中的所字符转换为小写
String toUpperCase():使用默认语言环境,将 String 中的所字符转换为大写
String trim():返回字符串的副本,忽略前导空白和尾部空白
boolean equals(Object obj):比较字符串的内容是否相同
boolean equalsIgnoreCase(String anotherString):与equals方法类似,忽略大小写
String concat(String str):将指定字符串连接到此字符串的结尾。 等价于用“+”
int compareTo(String anotherString):比较两个字符串的大小
String substring(int beginIndex):返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。
String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。
boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束
boolean startsWith(String prefix):测试此字符串是否以指定的前缀开始
boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的子字符串是否以指定前缀开始
boolean contains(CharSequence s):当且仅当此字符串包含指定的 char 值序列时,返回 true
int indexOf(String str):返回指定子字符串在此字符串中第一次出现处的索引
int indexOf(String str, int fromIndex):返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始
int lastIndexOf(String str):返回指定子字符串在此字符串中最右边出现处的索引
int lastIndexOf(String str, int fromIndex):返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索
注:indexOf和lastIndexOf方法如果未找到都是返回-1
替换:
String replace(char oldChar, char newChar):返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所 oldChar 得到的。
String replace(CharSequence target, CharSequence replacement):使用指定的字面值替换序列替换此字符串所匹配字面值目标序列的子字符串。
String replaceAll(String regex, String replacement):使用给定的 replacement 替换此字符串所匹配给定的正则表达式的子字符串。
String replaceFirst(String regex, String replacement):使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。
匹配:
boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。
切片:
String[] split(String regex):根据给定正则表达式的匹配拆分此字符串。
String[] split(String regex, int limit):根据匹配给定的正则表达式来拆分此字符串,最多不超过limit个,如果超过了,
剩下的全部都放到最后一个元素中。
6. String与其它结构的转换
6.1 与基本数据类型、包装类之间的转换
String --> 基本数据类型、包装类:调用包装类的静态方法:parseXxx(str)
基本数据类型、包装类 --> String:调用String重载的valueOf(xxx)
@Test
public void test1(){
String str1 = "123";
// int num = (int)str1;//错误的 不是子父类
int num = Integer.parseInt(str1);
String str2 = String.valueOf(num);//"123"
String str3 = num + "";
System.out.println(str1 == str3);
}
6.2 与字符数组之间的转换
String --> char[]:调用String的toCharArray()
public void getChars(int srcBegin, int srcEnd, char[] dst,
int dstBegin):提供了将指定索引范围内的字符串存放到数组中的方法
char[] --> String:调用String的构造器
String 类的构造器:String(char[]) 和 String(char[],int offset,int
length) 分别用字符数组中的全部字符和部分字符创建字符串对象。
@Test
public void test2(){
String str1 = "abc123"; //题目: a21cb3
char[] charArray = str1.toCharArray();
for (int i = 0; i < charArray.length; i++) {
System.out.println(charArray[i]);
}
char[] arr = new char[]{'h','e','l','l','o'};
String str2 = new String(arr);
System.out.println(str2);
}
6.3 与字节数组之间的转换
编码:String --> byte[]:调用String的getBytes()
public byte[] getBytes(String charsetName) :使用指定的字符集将
此 String 编码到 byte 序列,并将结果存储到新的 byte 数组。
解码:byte[] --> String:调用String的构造器
String(byte[],int offset,int length) :用指定的字节数组的一部分,
即从数组起始位置offset开始取length个字节构造一个字符串对象。
编码:字符串 -->字节 (看得懂 --->看不懂的二进制数据)
解码:编码的逆过程,字节 --> 字符串 (看不懂的二进制数据 ---> 看得懂
说明:解码时,要求解码使用的字符集必须与编码时使用的字符集一致,否则会出现乱码。
@Test
public void test3() throws UnsupportedEncodingException {
String str1 = "abc123中国";
byte[] bytes = str1.getBytes();//使用默认的字符集,进行编码。
System.out.println(Arrays.toString(bytes));
byte[] gbks = str1.getBytes("gbk");//使用gbk字符集进行编码。
System.out.println(Arrays.toString(gbks));
System.out.println("******************");
String str2 = new String(bytes);//使用默认的字符集,进行解码。
System.out.println(str2);
String str3 = new String(gbks);
System.out.println(str3);//出现乱码。原因:编码集和解码集不一致!
String str4 = new String(gbks, "gbk");
System.out.println(str4);//没出现乱码。原因:编码集和解码集一致!
}
6.4 与StringBuffer、StringBuilder之间的转换
String -->StringBuffer、StringBuilder:调用StringBuffer、StringBuilder构造器
StringBuffer、StringBuilder -->String:①调用String构造器;②StringBuffer、StringBuilder的toString()
7. JVM中字符串常量池存放位置说明:
jdk 1.6 (jdk 6.0 ,java 6.0):字符串常量池存储在方法区(永久区)
jdk 1.7:字符串常量池存储在堆空间
jdk 1.8:字符串常量池存储在方法区(元空间)