大数据大作业(课程设计)
题目:信息爬取字数统计及可视化
内容及要求:
- 配置Hadoop平台;
- 利用爬虫技术爬取任一门户网站新闻栏目一定时间段内的新闻信息,保存为一个或多个文件并上传到Hadoop平台以本人学号命名的文件夹下;
- 利用MapReduce框架编程完成字数统计;
- 利用Echarts或其他可视化平台,使用四种不同可视化效果分别展示出现频次前5、前10、前20、前50的单词可视化效果网页。
前言
本课题为信息爬取字数及可视化,首先使用Python编程爬取了凤凰网门户网站新闻栏目22/7/26—7/28三天内的新闻信息,其次,将爬取的新闻整合为一个文件,然后使用Python编程对文件进行分词处理并且可以获取词云,接下来将该文件上传至hadoop平台,利用MapReduce框架编程完成了字数统计,接着就是利用Python编程对字数统计文件中的词频由高到低进行排序,得到出现频次排名前5、前10、前20、前50的词语,最后根据排好序的词语利用Echarts平台分别完成4种可视化效果网页。
本课题中涉及到的主要技术有:MapReduce框架编程进行字数统计、Python编程使用selenium库爬取网站动态新闻、Python编程对文本分词处理、Python编程对词频排序、利用Echarts平台展示词语可视化效果网页。
开发环境:Linux系统、Hadoop平台、Echarts平台、Python环境
软件工具:Pycharm 、Anaconda 、VMware Workstation Pro
项目实现
1.1 功能1——爬取新闻
Python爬取凤凰网门户网站新闻栏目三天内的新闻信息
1.2 实现原理
通过程序,模拟浏览器向服务器定期发送请求、获取信息、分析信息并储存我们想要的内容。
1.3 主要步骤及代码
(1)主要步骤:
1、向凤凰网新闻网站发送请求
browser = webdriver.Edge()
browser.get('https://www.ifeng.com')
2、获取门户新闻栏目超链接
page_text = browser.page_source
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="root"]/div/div[6]/div[2]/div[2]/div[2]')
for li in li_list:
con = li.xpath('./p[@class="news_list_p-3EcL2Tvk "]/a/@href')3、根据获取的新闻超链接发送请求
for i in range(len(con)):
htt = "" + con[i]
browser.get(htt)
4、获取每个链接内的新闻文本
text = browser.page_source
ee = etree.HTML(text)
lis=ee.xpath('//*[@id="root"]/div/div[2]/div[2]/div/div[1]/div/div/div[1]')
for j in lis:
ls.append(j.xpath('./p/text()'))
5、保存新闻文本
fo = open('爬取新闻文件/XinWen{}.txt'.format(v), 'w', encoding='utf-8')
ans = ''
ans += str(ls)
fo.write(ans)
fo.close()
6、间隔一定时间自动爬取(时间自设)
h = 23
m = 59
v = 0
while True:
now = datetime.datetime.now()
if now.hour == h and now.minute == m:
v += 1 #生成文件名递增
h += 6 #每隔多长时间爬取一次
h %= 24
getCon(v)
print("现在时间:{}".format(now))
print("下一次爬取时间:{}时{}分".format(h,m))
# 执行完休息60秒避免重复
time.sleep(60)
# 每隔60秒检测一次,不然会漏
time.sleep(60)
(2)实现效果图:

图 1-1 爬取结果

图 1-2 爬取结果
2.1 功能2——文本分词处理
对爬取的新闻文本进行分词处理,以便下一步词频统计
2.2 实现原理
利用python的jieba库这个第三方中文分词函数库,能够将一段中文文本分割成中文词语的序列。jieba库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组。
2.3 主要步骤及代码
(1)主要步骤:
1、对新闻文本进行精确模式分词
f = open("合集.txt", "r", encoding="utf-8")
ls=jieba.lcut(f.read())
f.close()
2、定义停用词即不参与后期统计的词语
sf = "停用词/停用词.txt"
stop_words = []
with open(sf,'r',encoding='utf-8') as f:
for i in f.read().splitlines():
stop_words.append(i)
3、将分词后的文本进行正则化,只保留文本,再次分词
la = re.sub(r'[\s\[|\]0123456789,、,。’+?!”“\']',"",str(ls))
txt0 =jieba.lcut(la)
4、将正则化后的文本中包含的停用词过滤掉,之后保存到文本文件
ans = []
for x in txt0:
if x not in stop_words and len(x) > 1:
ans.append(x)
res = " ".join(ans)
with open('分词文件/a1.txt','w',encoding='utf-8') as fi:
fi.write(res)
5、针对要统计次频的文本进行词云展示(本步非必要)
wd=wordcloud.WordCloud(font_path='C:\Windows\Fonts\simkai.ttf',width=1800,height=1800,background_color='white',stopwords=['要求','甚至','此次','虽然','发现','继续','一个']).generate(res)
wd.to_file('新闻.png')
(2)效果展示:
原合集文件内容:

图 2-1 原文件内容展示
分词后效果:

图 2-2 分词后效果
生成词云效果图:
不使用蒙版—>

图 2-3 词云图(原始)
使用蒙版效果图如下(可自定义词云形状)—>

图 2-4 词云图(蒙版)
3.1 功能3——新闻词频统计
利用MapReduce框架编程对词频进行统计
3.2 实现原理
MapReduce模型核心是Map函数和Reduce函数,核心思想可以用分而治之来描述。一个大的MapReduce作业首先会被拆分为多个Map任务并行执行,当Map任务全部结束后,Reduce过程开始,并且Map生成的中间结果会以
3.3 主要步骤及代码
(1)主要步骤:
1、进行统计前,我们首先要在Linux环境下配置好hadoop平台后,在进行编程处理
详细配置过程可参考hadoop配置
2、利用MapReduce框架编程并生成可执行jar包
public class lihongbo {
public lihongbo() {}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(); // 创建一个对象,用于读取配置文件
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
// 获取命令行中除了配置文件以外的其他参数
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
// 如果参数不足两个,则输出用法提示并退出程序
Job job = Job.getInstance(conf, "word count"); // 创建一个作业对象
job.setJarByClass(lihongbo.class); // 设置作业运行时使用的 JAR 文件
job.setMapperClass(lihongbo.TokenizerMapper.class); // 设置 Mapper 类
job.setCombinerClass(lihongbo.IntSumReducer.class); // 设置 Combiner 类(可选)
job.setReducerClass(lihongbo.IntSumReducer.class); // 设置 Reducer 类
job.setOutputKeyClass(Text.class); // 设置输出键类型
job.setOutputValueClass(IntWritable.class); // 设置输出值类型
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i])); // 添加输入路径
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); // 设置输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1); // 启动作业并等待其完成,返回状态码 0 表示成功,1 表示失败
}
public static class TokenizerMapper extends Mapper {
// 定义一个 Mapper 类,继承自 Mapper
private static final IntWritable one = new IntWritable(1); // 定义一个常量 one,值为 1
private Text word = new Text(); // 定义一个文本类型变量 word
public TokenizerMapper() {
// 构造函数,没有实际操作
}
public void map(Object key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
// 实现 Mapper 类中的 map 函数,对输入数据进行处理
StringTokenizer itr = new StringTokenizer(value.toString()); // 将输入数据转化为字符串
while(itr.hasMoreTokens()) { // 如果还有单词可以读取
this.word.set(itr.nextToken()); // 获取下一个单词
context.write(this.word, one); // 输出键值对,键为单词,值为 one
}
}
}
public static class IntSumReducer extends Reducer {
// 定义一个 Reducer 类,继承自 Reducer
private IntWritable result = new IntWritable(); // 定义一个整数类型变量 result,用于保存累加结果
public IntSumReducer() {
// 构造函数,没有实际操作
}
public void reduce(Text key, Iterable values,
Reducer.Context context)
throws IOException, InterruptedException {
// 实现 Reducer 类中的 reduce 函数,对经过 Mapper 处理后的数据进行汇总
int sum = 0; // 定义一个整数变量 sum,用于保存累加结果
for(IntWritable val : values) { // 遍历键值对列表
sum += val.get(); // 累加键值对的值
}
this.result.set(sum); // 将累加的结果设置为 result 的值
context.write(key, this.result); // 输出键值对,键为单词,值为累加结果
}
}
} 3、将做好的新闻分词文件上传至hadoop平台
通过xftp将分词文本上传至Linux系统中的B20041316目录下
./bin/hdfs dfs -mkdir B20041316 #在hdfs上生成一个目录
#将文件上传至hdfs中的B20041316目录下
./bin/hdfs dfs -put ./B20041316/a1.txt B200413164、将java程序生成可执行jar包后运行
# 运行可执行jar文件进行词频统计
./bin/hadoop jar ./myapp/WordCount.jar B20041316 output
5、查看运行结果
./bin/hdfs dfs -cat output/*(2)实现效果图:

图 3-1 词频统计完成
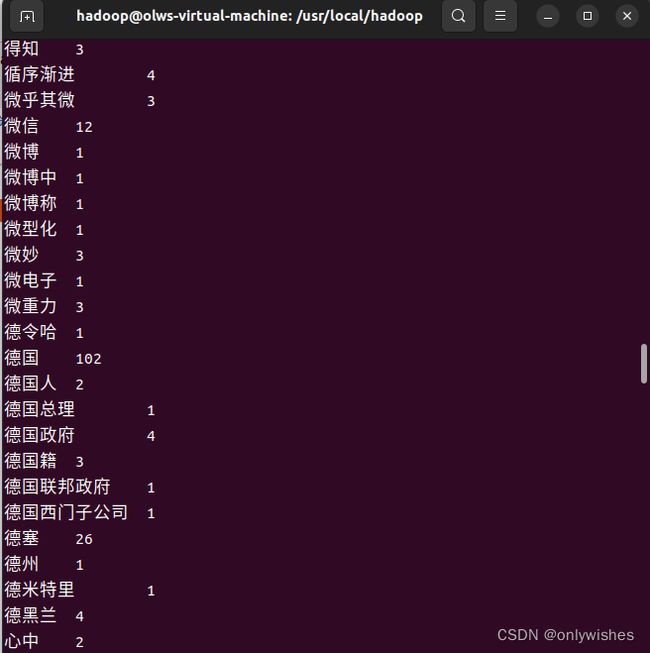
图 3-2 词频统计结果
ps:使用Python实现词频统计
with open('../分词结果/a1.txt', 'r', encoding='utf-8') as f:
lines = f.read().split()
dic = {}
for w in lines:
dic[w] = dic.get(w, 0) + 1
ls = list(dic.items())
ls.sort(key=lambda x:x[0])
f = open('../词频统计结果/out.txt', 'w', encoding='utf-8')
for i in range(len(ls)):
f.write('{} {}\n'.format(ls[i][0],ls[i][1]))
f.close()4.1 功能4——对词频进行排序
由于得到的词频是根据字词进行排序的,而不是字词出现的次数,在几千行词频中无法直接找到前50组,要进行排序,以便于进行可视化网页展示
4.2 实现原理
由于每个词频中的词是不同的,唯一的,利用python中的字典来存储词和频次,对字典中元组进行排序即可得到频次排名前5前、前10、前20、前50的词频
4.3 主要步骤及代码
(1)主要步骤:
1、使用Python将词频存入字典中
with open('outcome.txt', 'r',encoding='utf-8') as f:
lines = f.readlines()
dic = {}
for line in lines[:-1]:
lk = line.strip("\n").split("\t")
dic[lk[0]] = dic.get(lk[0],int(lk[1]))
2、对词频进行排序并输出前5、前10、前20、前50排名的词频
li = list(dic.items())
li.sort(key=lambda x:x[1],reverse=True)
print('词频前5:',li[:5])
print("-------------------------------------------------")
print('词频前10:',li[:10])
print("-------------------------------------------------")
print('词频前20:',li[:20])
print("-------------------------------------------------")
print('词频前50:',li[:50])
(2)实现效果图:

图 4-1 词频排序结果
5.1 功能5——可视化网页展示词频结果
利用Echarts根据词频排序结果分别进行4种不同的可视化效果展示。
关于Echarts,我们可以访问Echarts官方文档快速了解它
5.2 实现原理
ECharts 是一个轻量级的 javascript 图形库,纯 js 实现,MVC 封装,数据驱动,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器,底层依赖矢量图形库 ZRender,提供直观,交互丰富,可高度个性化定制的数据可视化图表。利用得到的排序结果中的数据就可以很轻松的将词频数据以图表的形式进行可视化
5.3 主要步骤及代码
(1)主要步骤:这里以前排名前5的词频为例
1、编写柱状图JavaScript代码,载入数据
2、编写折线图JavaScript代码,载入数据
3、编写饼图JavaScript代码,载入数据
4、编写南丁格尔图JavaScript代码,载入数据(用于词频前5,前10)
5、编写圆环图JavaScript代码,载入数据(用于词频前20,前50)
(2)实现效果图
柱状图:

图 5-1-1 柱状图
折线图:
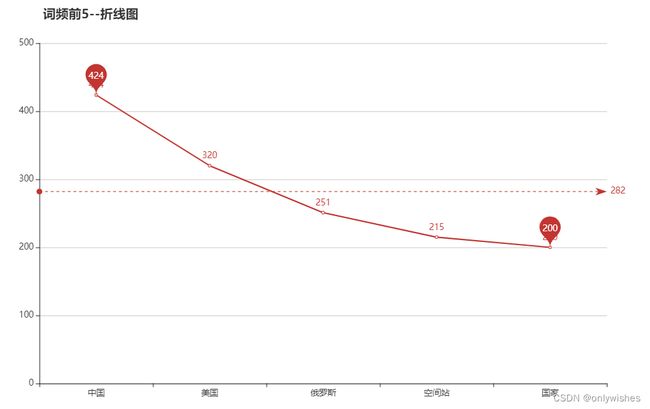
图 5-2-1 折线图
饼图:

图 5-3-1 饼图
南丁格尔图:

图 5-4-1 南丁格尔图
圆环图:
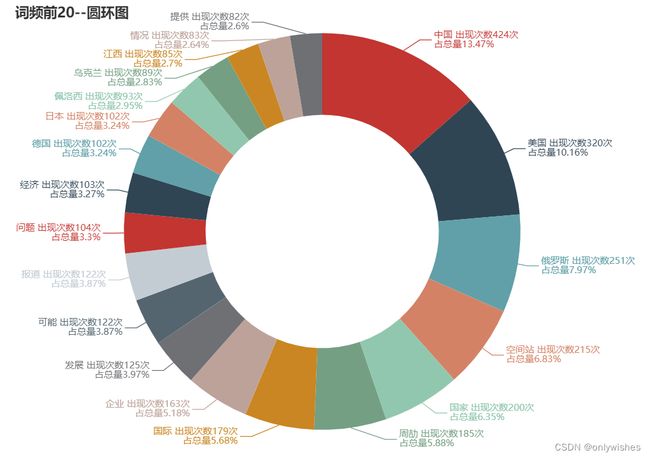
图 5-4-3 圆环图
===============================华丽的分割线================================
ps:本文附有视频简单介绍-->简单介绍
夜深沉,星光隐,时间匆匆逝去。 春去秋来,岁月如梭织, 花谢花开,往事已成风景。
又到一年7月份,岁月的流年,恍若一瞬即逝,人生短暂,需好好珍惜。