序:随着人工智能的崛起,被誉为最适合人工智能编程语言 - python也越来越普及,使用范围广泛,而且容易上手,值得我们学习使用,提高办公效率,掌握编程语言技能;
目录
python概况
python与c语言的差异分析
疑问及解决
总结输出
课程笔记
一、数据结构:
二、方法:
三、可迭代对象(iterable)
四、变量作用域
五、列表推导式(简约表达)
六、函数
七、类与对象
八、正则表达式
九、数据库(MySQL基本操作)
十、爬虫
十一、网络编程
十二、python与web
十三、python图形用户界面( 类似QT的开发流程,调用组件包 )
十四、python库:模块、开源库、标准库
十五、进阶Tensorflow(机器学习库):图像识别库
十六、python IDE工具 - pycharm常用功能:
十七、python就业方向
python概况

python与c语言的差异分析
学习一门新语言,如果有学习其它编程语言经验,将大大提高学习效率(编程思想是一致的);
此处只做大体差异分析,差异分析能有助学习者更好地过渡另一门编程语言,本人熟练C语言,上手python相对容易:
1、
C语言是编译性语言,源代码不能直接运行,需要一个编译器先编译成可执行文件才能运行;
python是解释性语言,可以不用编译直接运行。
2、
C 是弱类型、静态类型检查的(C语言的数据类型很严格,并且还有最具有特征的C指针类型,是C语言的重难点)
Python 是强类型、动态类型检查的(习惯了C语言,python的数据类型就变得十分简单易用)
3、
Python 是面向对象语言,
C 是面向过程语言
4、
编译性语言的移植性通常较差,在linux上编译好的程序不能在windows上运行;
解释性语言移植性较好,可以跨平台运行。
5、
编译性语言因为要事先编译好,所以运行性能较高;
解释性语言的性能相对来说要低一点。
6、
编译性语言更靠近系统底层,一般要自己做内存管理,对计算机基础知识要求要高一点,新手上手的难度大一点。
解释性一般都屏蔽了系统底层,对于不是计算机科班的人来说,上手难度低一点,比较容易使用。
7、
编译性语言的安装和系统环境配置较为繁琐,新手要花很长时间才能搞定。
解释性语言在安装上要简单很多。
8、
因为编译性语言更靠近系统底层,所以一般能写代码直接驱动摄像头等硬件。
解释性语言不能直接驱动硬件,比如Python驱动硬件就是c语言写的(CPython是这样)。
9、
编译性语言编译好后,完全反编译破解出源代码的难度较大。
解释性语言是直接能看到源代码的,对于一些需要交付项目,又不想交付源代码来说,比较麻烦。
疑问及解决
1、import 、from import 区别:
a、import(浅拷贝)、from import(深拷贝);
b、import 避免模块重名; from import:调用方便;
总结输出
*任何语言都必须慎用标志位(全局)!导致程序混乱且容易出问题;
*python在windows、Linux实现有差异:a)windows不支持分叉 b)不支持poll c)编码问题;
*精通任何程序设计语言最好的办法就是实践-测试它的限制,探索它的威力;
*c \ c++ \ java相对python来说,运行速度快几个数量级;
*python中内存管理是自动的,如果对象不再使用,会自动释放;
1、环境搭建:
a、安装python x版本解释器,每个版本的特性不一样,是python运行的基础;
b、安装pycharm,图形化集成IDE软件,作为python编程的中间桥梁,可拓展工具多;
2、python使用:
a、windows cmd命令窗口执行python
b、linux下,文件开头 #!/bin/env pytho
3、python两大特性:
a、python是解释性语言,运行一行解释一行,运行速度慢,底层是C语言(python是封装起来的C);
b、只要有解释器的平台,就能运行python,称为胶水语言;
4、方法与函数:
a、方法依赖与对象,而函数是独立实现的;
b、方法是作为变量构成对象的一部分;
5、类与对象的相关概念:
a、每个对象都有自己的状态(state)->拥有自己一个专属的储存空间:由它的特性描述(名称)->相当于变量名;
b、类的一些特性(方法):__bases__ __class__ __dict__
6、属性(attribute):
a、泛指一类,某个容器的子项,函数的子项,类的子项等;
课程笔记
一、数据结构:
1、容器:a、序列(可变列表与不可变元组);b、映射(字典) ;c、集合(set);
2、字典与序列不同,它没有索引,非顺序排列;
二、方法:
1、一些内建类型具有很多使用的方法,比如列表(sort reverse)
三、可迭代对象(iterable)
1、for i in [list tuple dict set str] 依次在其中拿到数据使用;
四、变量作用域
1、全局变量/局部变量 -> 全局命名空间/局部命名空间
2、name = ['yang] ne=name //name、name1指向同一个列表
3、name = ['yang'] ne=name[:] //name与ne指向不同的列表
4、全局变量定义:global
五、列表推导式(简约表达)
print([x + '+' + y for x in boys for y in tmpdict[x[0]]])
六、函数
1、函数的定义,函数参数的灵活性较C而言,十分简洁;
2、储存子封闭作用域的行为叫做封包;
3、外部作用域的变量使用:nonlocal来修改值;(类似C语言的指针修改值方式);
七、类与对象
*可以看作数据以及由一系列可以存取/操作这些数据的方法所组成的集合;
1、多态(polymorphism):根据对象(或类)类型不同而表现出不同部分;多态是python语言实现灵活性的核心;
a)方法:'abc'.count('a') 、 [1, 2, a].count('a');无论对象是什么,都能引用方法count进行操作;
b)函数:
c)运算符的多态: + 处理数值和字符串体现出不同行为;
2、封装(encapsulation):
3、继承(inheritance):
八、正则表达式
1、正则表达式是可以以某种模式( 十分丰富)匹配文本片段,从而达到搜索、替换、分段等功能;
2 、特殊字符:
(.) 匹配任意单个字符 .* 匹配任意字符串
( ) 子模式
| 管道符号
[ ]字符集
* ? + 可选项和重复子模式
3、起始与结束匹配:
脱字符:'^pattern'
美元符号:'pattern$'
九、数据库(MySQL基本操作)
1、数据库的使用场景:1) 自动地支持并发访问 2)使用多个数据字段或属性进行复杂的搜索 3)数据量大,需要有效管理;
2、同类的数据库: 商业数据库(Oracle Mircrosoft SQL Server)、SQLite
a、python内置的数据库模块sqlite3;
b、python数据库两层概念: 服务器(SQLite、Oracle源码引擎) <-> 客户端(python模块:pySQLite \ sqlite3)
c、python标准数据库接口:Python DB-API;
d、操作数据库的一般流程:打开( connect 连接数据库 )->创建游标对象( cusor( ) )->使用游标对象的execute()方法执行SAL命令,将数据返回给该对象->提交( commit )或回滚数( rollback )->关闭( close )游标对象与连接对象;
3、游标对象的一些方法:1)callproc 2)execute( many ) 3)fetchone( many/all ) 4)nextset 5)setinputsizes( sizes ) ;
4、SQL语句:1) 2) 3) 4) 5) 6)
十、爬虫
1、爬虫的基本流程:输入种子URL->将其包含的所有网页链接加入到待抓取的URL任务队列->读取URL、DNS解析、网页下载->网页解析->提取有用信息到数据库等储存介质;
2、基本的网页知识:
a)cookie:保存在本地(客户端)的数据集,用于保存用户登录信息,和保存当前用户状态;
十一、网络编程
1、网络地址:( IP地址[大网地址] + 端口号[设备中的服务通道,>1024] )
2、python是一个强大的网络编程工具,python非常擅长于处理字节流的各种模式,容易处理各种网络协议格式;
3、Twisted框架是一个丰富成熟,用于编写网络应用程序的框架;
4、网络套接字的一般操作流程:
a)服务器套接字:bind -> listen->accept( 每一个连接都有对应一个accept处理,通常在一个while循环中实现 )
b)客户端套接字:连接(connect) -> 处理事务 -> 完成事务 -> 断开连接;
5、http服务器通常由Linux实现,原因是Linux本身具备丰富的驱动,linux可以实现更高的并发,提高网络服务器的功能;
6、强大的urlib与urlib2模块:
7、windows不支持分叉( linux fork操作 )、poll;
8、服务端与客户端协议往同一个端口发送接受数据,客户端可以共享同一份代码, 但是每个运行的客户端的地址端口号是不同的
十二、python与web
1、XHTML是HTML最新的方言;
2、python实现http:(windows or Linux)+ apache +python(内置的数据库模块、CGI模块、网络模块等等);
3 、屏幕抓取( BeautifulSoup ):
4、CGI(服务器端技术,common gateway interface 通用网关接口):
5、*通过cgi cgitb模块进行CGI脚本编写,此模块类似数据库封装了CGI引擎
6、mod python:
7、APache网络服务器的扩展模块,使得python解释器成为Apache的一部分,使得python利用api深入Apache内核;
8、分三部分:
1)CGI处理程序:允许使用mod_python解释器运行CGI脚本
2)PSP(python server page)处理程序:允许用HTML与python代码混合编程创建可执行网页;
3)发布处理程序:允许URL调用python函数
9、网络应用程序框架(实现更复杂的系统):主流的四个:zope\Django\pylons\TurboGears
10、WEB服务位于很高层次的抽象,使用http作为底层协议,上层则是更多面向内容的协议,比如XML格式对请求和响应编码;
11、RSS(rich site summary 富站点摘要):比如显示博客的最新更新;
12、XML-RPC进行远程调用:客户端调用服务端的某个服务函数,并获取返回结果;
13、http服务器搭建简易流程:
十三、python图形用户界面( 类似QT的开发流程,调用组件包 )
1、wxpython(图形库):类似QT
2、流行的GUI库:wxpython、pyQt、PyGTK;
3、GUI的三大要素:
a)窗口;
b)布局管理器;
c)事件处理;
十四、python库:模块、开源库、标准库
*有些库已经庞大到单独出书;
1、python的标准库都是开源的;
2、通过import导入;
3、包:组织多个模块(包含_init_py的文件);
4、查看模块(标准库)的一些方法:
a、dir(库名字) : 查看对象的所有特性(模块的所有函数、类、变量);
b、(库名字).__all__ : 打印模块的公有接口
c、help(函数名) :提供日常所需的信息
d、print 函数名._doc_ :查看函数开头标注的信息
e、print 模块名.__file__ :查看模块文件所在路径
5、库官网,下载使用手册;
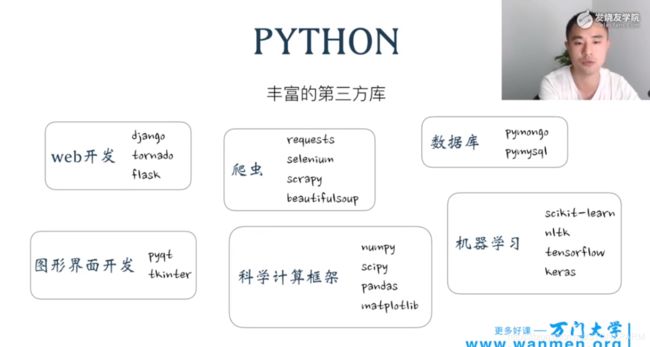
6、常用的第三方库:
十五、进阶Tensorflow(机器学习库):图像识别库
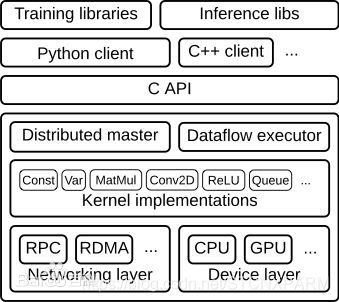
Tensorflow代码框架结构:
十六、python IDE工具 - pycharm常用功能:
十七、python就业方向

十八、python相关知识参考链接
1、Python文档使用指南: https://zhuanlan.zhihu.com/p/93083399
2、python标准库: https://www.jb51.net/books/227780.html
3、Python标准库和第三方库或者本地库的引用 https://blog.csdn.net/weixin_42168614/article/details/88173816
4、pydoc 的使用: https://www.jianshu.com/p/bf2df7e433e
5、python项目打包发布: https://blog.csdn.net/chenzhanhai/article/details/85334919
pyinstaller: http://www.pyinstaller.org/downloads.html