Numpy系列(五):函数库之2随机数及概率分布
Numpy系列目录
文章目录
- 一、 简介
- 二、 思维导图
- 三、 Numpy随机数及概率分布
-
- 1. 随机数
-
- 1.1 api版本说明
- 1.2 简单随机数
- 1.3 设置随机种子生成相同随机数
- 1.4 排列组合
- 2. 随机抽样
-
- 2.1 离散概率分布
-
- 2.1.1 常见离散分布简介
- 2.1.2 伯努利分布
- 2.1.3 二项分布
- 2.1.4 几何分布
- 2.1.5 泊松分布
- 2.2 连续概率分布
-
- 2.2.1 均匀分布
- 2.2.2 指数分布
- 2.2.3 正态分布
- 2.2.4 对数正态分布
- 2.2.5 伽玛分布
- 2.2.6 瑞利分布
- 2.2.7 韦伯分布
- 2.2.8 贝塔分布
- 2.2.9 狄利克雷分布
- 2.2.10 拉普拉斯分布
- 2.3 三大抽样分布
-
- 2.3.1 卡方分布
- 2.3.2 F分布
- 2.3.3 t分布
- 2.4 其他
一、 简介
Numpy内置了random伪随机数模块,用于生成随机数。伪随机是用确定性的算法计算出
随机数序列的算法,并不真正的随机,一般统计意义上看我们仍然可以视为真随机数。
random模块有两种不同的API:
- RandomState是旧版本的方式,为了兼容性,新版本仍可以用
- Generator是新版本推荐的方式。
两种方法大部分函数是相同的。
默认情况下,Generator使用PCG64提供的位,该位具有比RandomState中的传统mt19937随机数
生成器更好的统计属性。
二、 思维导图
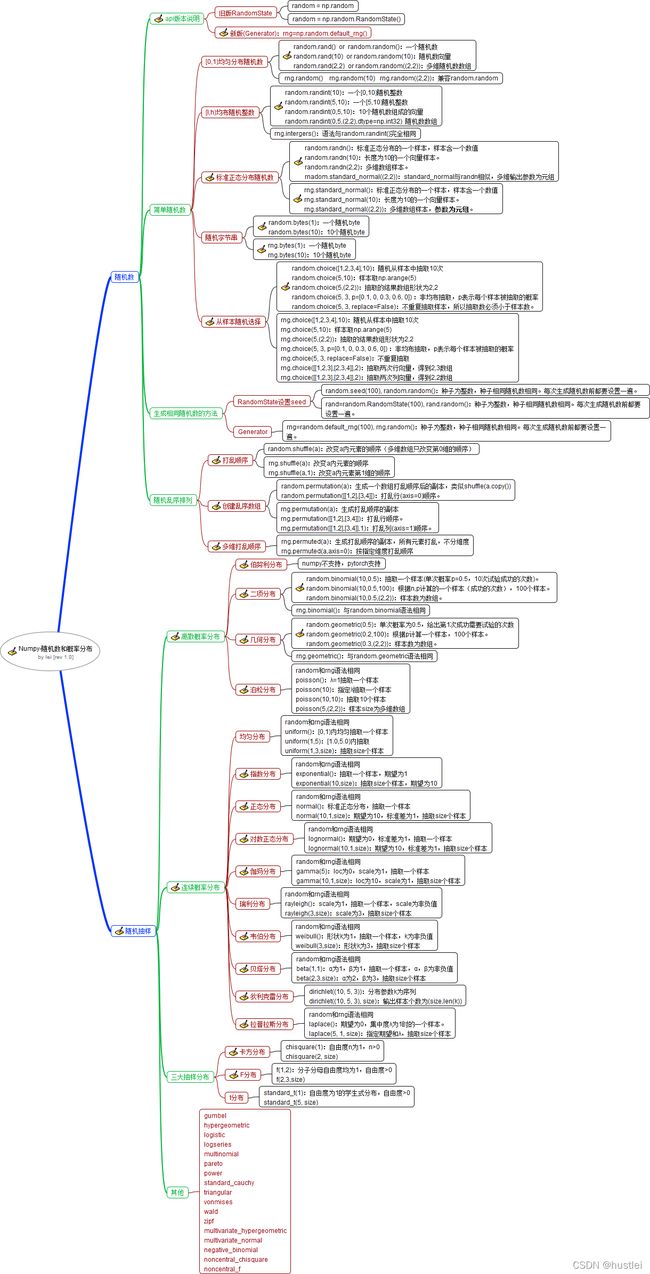
三、 Numpy随机数及概率分布
1. 随机数
1.1 api版本说明
新版本推荐使用新版的Generator,老版本只能用RandomState。
两种方式对应的方法大部分是相同的,但是也有小部分不一样。
在使用中需要注意,比如rand, randn等方法是RandomState独有的,而integers方法是Generator独有的。
使用方法
旧版RandomState使用方法:
- 直接从np.random模块调用随机数方法,如np.random.random()
- 创建RandomState后,通过RandomState调用随机数方法
- random = np.random.RandomState()
- 用random.random()的方式调用
新版(Generator)使用方法
- 创建Generator对象:
rng=np.random.default_rng() - 通过Generator对象调用方法:
rng.random()
避免不支持新版本api的兼容写法
try:
rng_integers = rng.integers
except AttributeError:
rng_integers = rng.randint
a = rng_integers(1000)
1.2 简单随机数
1.2.1 [0,1)均匀分布随机数
- random.random(size=1):size为整数或元组,表示生成随机数填充size形状数组。
- random.random():生成一个随机数
- random.random(10):生成一个随机数向量
- random.random((2,2)):生成多维随机数。注意size参数是元组。
- random.rand():与random.random相似。rand接受多个参数,random多个参数必须组成元组。
- random.rand()
- random.rand(10)
- random.rand(10,10):与random.random((10,10))相同
- rng.random(size=1):用法同random.random()。但是可以设置dtype参数,random.random不行。
- rng.random():生成一个随机数
- rng.random(10):生成一个随机数向量
- rng.random((2,2)):生成多维随机数
注意rng没有rand()方法。
1.2.2 [low,high)均布随机整数
- random.randint(low, high=None, size=None):生成
[low, high)的随机整数,填充size形状数组- 基本用法
random.randint(10):生成一个[0,10)的随机整数random.randint(5,10):生成一个[5,10)的随机整数random.randint(0,5,10):10个随机数组成的向量random.randint(0,5,(2,2),dtype=np.int32) 随机数数组
- 特别用法
np.random.randint(1, [3, 5, 10]):生成一个3个元素的向量,元素范围分别为[1,3),[1,5),[1,10)np.random.randint([1, 5, 7], 10):生成一个3个元素的向量,元素范围分别为[1,10),[5,10),[7,10)np.random.randint([1, 3, 5, 7], [[10], [20]]):生成一个2行4列的数组,low分别为1,3,5,7,high分别为10,20
- 基本用法
- rng.integers(low, high=None, size=None, endpoint=False):语法与random.randint相同
random.randint和rgn.integers都可以设置dtype参数。
1.2.3 标准正态分布随机数
期望为0,标准差为1的正态分布称为标准正态分布。
- random.standard_normal(size=1):生成size个标准正态分布随机数
random.standard_normal():生成一个标准正态分布随机数,即标准正态分布的一个样本random.standard_normal(10):生成一个向量random.standard_normal((10,2)):生成多维数组
- random.randn():与random.standard_normal相似,但是接受多个参数,size不需要用元组形式。
- random.randn()
- random.randn(10)
- random.randn(10, 2)
- rng.standard_normal(size=1):用法同random.standard_normal
rng.standard_normal可以指定dtype,random.standard_normal和random.randn不行。
1.2.4 随机字节串
- random.bytes
random.bytes(1):一个随机byte。不支持默认长度。random.bytes(10):10个随机byte。不支持多维。
- rng.bytes
rng.bytes(1):一个随机byte。不支持默认长度。rng.bytes(10):10个随机byte。不支持多维。
1.2.5 从样本随机选择
- random.choice:从样本随机抽取数值组成新的数组,样本只能是一维数组
random.choice([1,2,3,4], size):随机从样本中抽取size个值,size可以为整数,也可以为元组。random.choice([1,2,3,4], size, replace=False):不能重复抽取样本,所以抽取数必须小于样本数。本例中size不能大于4random.choice(5,size):样本取np.arange(5)random.choice(5,size, p=[0.1, 0, 0.3, 0.6, 0]):非均布抽取,p表示每个样本被抽取的概率
- rng.choice(sample, size):
- 支持random.choice的所有功能,并且支持多维样本。
rng.choice([[1,2,3],[2,3,4]],2):抽取两次列向量,得到2,2数组
1.3 设置随机种子生成相同随机数
通过设置随机种子可以使得生成的随机数可重复,即两次生成随机数相同。
1.3.1 RandomState设置种子
- 方法一:
np.random.seed(n)
>>> random.seed(2020)
>>> random.random()
0.9862768288615988
>>> random.seed(2020)
>>> random.random()
0.9862768288615988
- 种子为正整数
- 种子相同随机数相同
- 每次生成随机数前都要设置一遍。
- 方法二:
rand = np.random.RandomState(n)
>>> rand = random.RandomState(2020)
>>> rand.random()
0.9862768288615988
>>> rand.random()
0.8733919458206546
>>> rand = random.RandomState(2020)
>>> rand.random()
0.9862768288615988
同样每次生成随机数前都要设置一遍。
1.3.2 Generator设置种子
创建Generator对象时设置种子:rng = np.random.default_rng(2020)
>>> rng = np.random.default_rng(2020)
>>> rng.random()
0.46830754332228663
>>> rng = np.random.default_rng(2020)
>>> rng.random()
0.46830754332228663
1.4 排列组合
1.4.1 打乱顺序
打乱数组本身的顺序
random.shuffle(a):改变a内元素的顺序(多维数组只改变第0维的顺序)rng.shuffle(a):改变a内元素的顺序(多维数组只改变第0维的顺序)rng.shuffle(a,1):改变a内元素第1维的顺序。多维数组指定改变顺序的维度,random.shuffle不支持。
1.4.2 创建乱序数组
得到排序后的副本
random.permutation(a):生成一个数组打乱顺序后的副本,类似shuffle(a.copy())。多维数组按第0维打乱顺序rng.permutation(a):生成打乱顺序的副本,多维数组打乱第0维顺序。rng.permutation(a,1):打乱列(axis=1)顺序。
1.4.3 多维数组所有元素打乱顺序
得到排序后的副本
rng.permuted(a):所有元素打乱,不分维度rng.permuted(a,axis=0):按指定维度打乱顺序,同rng.permutation(a,0)
random没有此方法。
2. 随机抽样
随机抽样,即按照特定分布随机生成若干个样本
随机抽取符合特定分布的序列,抽取的序列内的随机数符合指定的分布。即获得一个符合指定分布的样本。
2.1 离散概率分布
2.1.1 常见离散分布简介
- 贝努利分布:投硬币,正面反面概率分别为p,1-p
- 二项分布:如果把贝努利实验连续做n次,出现正面的次数服从的分布。
- 二项分布的极限:泊松分布。给定时间内时间发生次数的分布。
- 负二项分布:在贝努利实验中,如果想让正面出现n次,需要做的实验次数的分布。
- 负二项分布的极限:gamma分布。问如果指定事件出现N次,需要等待的时间。
- 二项分布与负二项分布的关系:二项分布是在固定实验次数情况下,问结果分布。负二项分布是在固定结果情况下问实验次数分布。一个是在固定投入问产出,一个是在固定产出下问投入。
- 几何分布:n重贝努利实验,正面第一次出现时的实验次数。
- 几何分布(帕斯卡分布r=1的特例)帕斯卡分布(负二项分布的正整数形式)
- 几何分布与负二项分布的关系:负二项分布是N个几何分布的和。相当于做N次几何分布,事件正好发生N次。各几何分布的实验次数之和就是负二项分布的总次数。
- 指数分布:几何分布的极限。事件第一次发生等待的时间。
- 指数分布与gamma分布的关系:N次指数分布时间之和就是gamma分布中事件发生N次等待总时间。
2.1.2 伯努利分布
又名两点分布。一件事情/一次实验,只有0,1两种结果。
变量只有0,1两个值。变量的概率:1的概率为p,0的概率为1-p。
典型的伯努利分布,单次抛硬币的建模,随机变量X只能取{0, 1}。
多次抛硬币就是二项分布。
2.1.3 二项分布
一个样本为n次伯努利实验成功的次数。
样本足够多时,其成功次数的概率分布和二项分布公式一致。
- random.binomial(n, p, size=None)
random.binomial(10,0.5):抽取一个样本(单次概率p=0.5,10次试验成功的次数)。random.binomial(10,0.5,100):根据n,p计算的一个样本(成功的次数),生成100个样本。random.binomial(10,0.5,(2,2)):样本数为数组。
- rng.binomial(n, p, size=None):与random.binomial语法相同
- n为试验次数,n>=0
- p为单次试验成功的概率,p为
[0,1]浮点数。
n次伯努利实验成功的次数为变量的离散概率分布。
n重伯努利试验,每次伯努利试验的成功概率为p,x(x=0~n)次实验成功的概率P(x)分布为二项分布。
2.1.4 几何分布
多次伯努利试验连续失败,第x次成功,则输出x。x为几何分布的一个样本。
样本足够多时,x的概率分布与几何分布一致。
- random.geometric(p, size=None)
random.geometric(0.5):单次概率为0.5,给出第1次成功需要试验的次数random.geometric(0.2,100):根据p计算一个样本,100个样本。random.geometric(0.3,(2,2)):样本数为数组。
- rng.geometric(p, size=None):与random.geometric语法相同
- p为单次伯努利试验成功的概率
在n次伯努利试验中,试验k次才得到第一次成功的机率。
详细地说,是:前k-1次皆失败,第k次成功的概率。
2.1.5 泊松分布
单位时间内随机事件发生的次数为一个样本。
random和rng语法相同
- **poisson(lam=1.0, size=None)**指定λ抽取size个样本
poisson():λ=1抽取一个样本poisson(10):指定λ=10抽取一个样本poisson(10,10):抽取10个样本poisson(5,(2,2)):样本size为多维数组
- 参数λ(λ≥0)是单位时间(或单位面积)内随机事件的平均发生次数。相当于二次分布的均值即np。
- 变量(一个样本)为单位时间内发生的次数。
当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似。
通常当n≧20,p≦0.05时,就可以用泊松公式近似得计算。
2.2 连续概率分布
2.2.1 均匀分布
random和rng语法相同
- uniform(low=0.0, high=1.0, size=None)
uniform():[0,1)内均匀抽取一个样本uniform(1,5):[1.0,5.0)内均匀抽取一个样本uniform(1,3,size):抽取size个样本
2.2.2 指数分布
指数分布的区间是[0,∞)。
random和rng语法相同
- exponential(lam=1.0, size=None)
exponential():抽取一个样本,期望为1exponential(10,size):抽取size个样本,期望为10
- λ>0是分布的一个参数,等于分布的期望。
- λ常被称为率参数,即每单位时间内发生某事件的次数。
指数分布是描述泊松过程中的事件之间的时间的概率分布。是伽马分布的一个特殊情况。
2.2.3 正态分布
random和rng语法相同
- **normal(loc=0.0, scale=1.0, size=None)**指定期望和标准差,抽取样本
- normal():标准正态分布,抽取一个样本
- normal(10,1,size):期望为10,标准差为1,抽取size个样本
- loc参数是期望,即均值
- scale参数为标准差
2.2.4 对数正态分布
对数正态分布(logarithmic normal distribution)是指一个随机变量的对数服从正态分布
random和rng语法相同
- lognormal(mean=0.0, sigma=1.0, size=None):指定对数服从的正态分布的期望和方差
- lognormal():期望(正态分布的,而不是对数正态分布)为0,标准差为1,抽取一个样本
- lognormal(10,1,size):期望为10,标准差为1,抽取size个样本
2.2.5 伽玛分布
random和rng语法相同
- gamma(shape, scale=1.0, size=None):α=shape,β=scale的gamma分布
- gamma(5):loc为0,scale为1,抽取一个样本
- gamma(10,1,size):loc为10,scale为1,抽取size个样本
- 伽玛分布一般和指数分布一起理解:指数分布解决的问题是“要等到一个随机事件发生,需要经历多久时间”
- 伽玛分布解决的问题是“要等到n个随机事件都发生,需要经历多久时间”。
- Gamma分布中的参数α称为形状参数,β称为逆尺度参数。其中α>0,β>0
- 当形状参数α=1时,,就变成了指数分布。
- 当α=n/2,β=1/2时,伽马分布就是自由度为n的卡方分布
- 伽玛分布可以看作是n个指数分布的独立随机变量的加总。负二项分布的极限。
2.2.6 瑞利分布
random和rng语法相同
- rayleigh(scale=1.0, size=None)
- rayleigh():scale为1,抽取一个样本,scale为非负值
- rayleigh(3,size):scale为3,抽取size个样本
2.2.7 韦伯分布
random和rng语法相同
- **weibull(a, size=None)**指定形状参数,生成样本
- weibull():形状k为1,抽取一个样本,k为非负值
- weibull(3,size):形状k为3,抽取size个样本
- k>0是形状参数(shape parameter)
- 如,当k=1,它是指数分布;k=2且时,是Rayleigh distribution(瑞利分布)。
2.2.8 贝塔分布
random和rng语法相同
- beta(a, b, size=None):指定α,β,生成样本
- beta(1,1):α为1,β为1,抽取一个样本,α,β为非负值
- beta(2,3,size):α为2,β为3,抽取size个样本
- α>0,β>0
一个作为伯努利分布和二项式分布的共轭先验分布的密度函数,是dirichlet分布的特例。
是指一组定义在(0,1)区间的连续概率分布。
2.2.9 狄利克雷分布
狄利克雷分布又称多元Beta分布,多项分布的共轭先验。
- dirichlet(alpha, size=None)
- dirichlet((10, 5, 3)):分布参数k为序列
- dirichlet((10, 5, 3), size):输出样本个数为(size,len(k))
参数α时一个向量,向量元素>0。输出样本shape为(size, len(α))
2.2.10 拉普拉斯分布
拉普拉斯分布可以看作是两个不同位置的指数分布背靠背拼接在一起,所以它也叫作双指数分布。
拉普拉斯分布的两个参数:
- μ:是位置参数, 中心峰值出现的位置,也是期望值。
- γ:是尺度参数, 集中的程度,拉普拉斯分布的方差时2γ**2
random和rng语法相同
- laplace(loc=0.0, scale=1.0, size=None)
- laplace():期望为0,集中度λ为1时的一个样本。
- laplace(5, 1, size):指定期望和λ,抽取size个样本
2.3 三大抽样分布
2.3.1 卡方分布
若n个相互独立的随机变量均服从标准正态分布,则这n个随机变量的平方和构成一新的随机变量,
其分布规律称为卡方分布。n为其自由度。
random和rng语法相同
- chisquare(df, size=None):指定自由度,生成size个样本
- chisquare(1):自由度n为1,n>0
- chisquare(2, size):指定自由度,生成size个样本
2.3.2 F分布
F分布是两个服从卡方分布的独立随机变量各除以其自由度后的比值的抽样分布,
是一种非对称分布,且位置不可互换。
其中两个参数都必须大于零,即dfnum(分子中的自由度)和dfden(分母中的自由度)。
- f(dfnum, dfden, size=None):根据分子自由度和分母自由度,生成size个样本
- f(1,1):分子分母自由度均为1,自由度>0
- f(2,3,size)
2.3.3 t分布
- standard_t(df, size=None):自由度为1的学生分布,生成样本
- standard_t(1):自由度为1的学生式分布,自由度>0
- standard_t(5, size)
2.4 其他
- gumbel:从Gumbel分布中抽取样本
- hypergeometric:从一个超几何分布中抽取样本
- logistic:从逻辑分布中抽取样本
- logseries:从对数系列分布中抽取样本
- multinomial:从多项分布中抽取样本
- pareto:从帕累托II或Lomax分布中抽取具有指定形状的样本
- power:从正指数a-1的幂分布中抽取[0,1]的样本
- standard_cauchy:从标准的Cauchy分布中抽取样本,模式=0
- triangular:从区间 [left, right] 的三角形分布中抽取样本
- vonmises:从冯-米塞斯分布中抽取样本
- wald:从Wald或逆高斯分布中抽取样本
- zipf:从Zipf分布中抽取样本
- multivariate_hypergeometric:从多变量超几何分布中生成变量
- multivariate_normal:从多元正态分布中随机抽取样本
- negative_binomial:从负二项分布中抽取样本
- noncentral_chisquare:从非中心的chi-square分布中抽取样本
- noncentral_f:从非中心F分布中抽取样本
Numpy系列目录
个人总结,部分内容进行了简单的处理和归纳,如有谬误,希望大家指出,持续修订更新中。
修订历史版本见:https://github.com/hustlei/AI_Learning_MindMap
未经允许请勿转载。