在大家的算法工作中,会训练各种各样的模型。导致大家模型实际应用效果不够好的原因有很多,一些常见的原因主要是模型结构不合理 、损失函数不合理 、超参数设置不合理,但除了这些原因,我想最核心的一个原因是数据的质量本身。
相信每一个自动驾驶行业的开发者对此都是会深有体会的,Lyft 团队在CVPR的presentation上就发出了“High quality labeled data is the key”的感慨。这也是本篇文章想要着重强调的主题。

下面通过一个实验来让大家直观感受一下“标注质量对模型训练性能的影响”
实验主题:不同质量标注对模型性能影响的对比实验
实验框架:
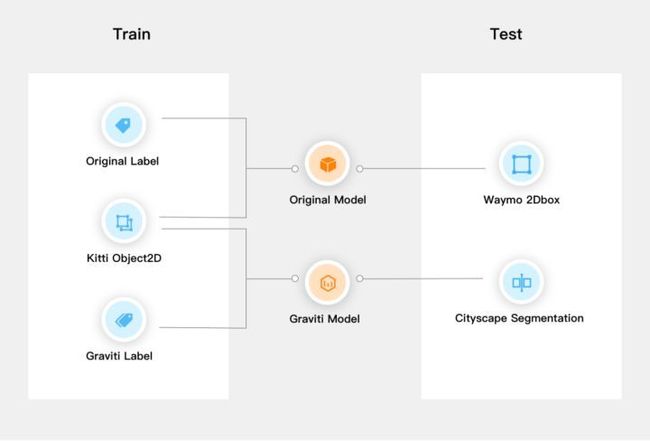
图中左侧是训练的过程,右侧是测试的过程
训练的部分逻辑:
首先是将KITTI数据集的图片搭配原生Original label可以得到一个Original KITTI dataset,相应地再将图片搭配Graviti label可以得到一个Graviti KITTI dataset;然后分别使用这两个数据集各自训练一个2D目标检测的模型,这里使用的是经典的faster-rcnn模型,得到的模型分别叫做Original model和Graviti model。
测试部分的逻辑:
使用了两个标注比较精准的第三方数据集;Waymo和Cityscape---来对两个模型分别进行测试。
数据处理:
先介绍一下本实验使用到的训练集和测试集:
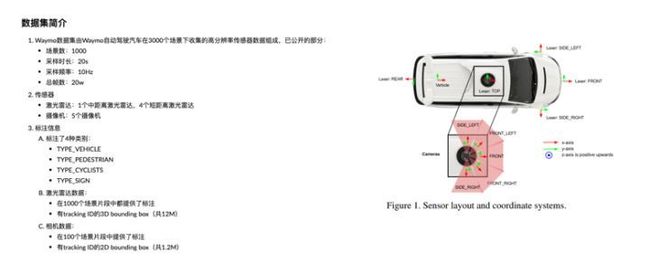
(1)Waymo 数据集是由Waymo公司的自动驾驶汽车采集的多传感器自动驾驶数据集 它的相机数据是连续采集的,其中一百个场景提供了2D框标注。
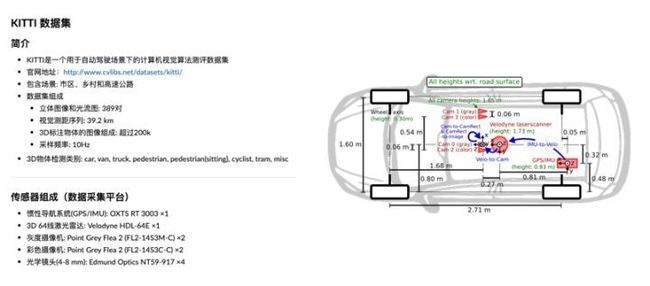
(2)KITTI 数据集,是由卡尔斯鲁厄理工学院和丰田工业大学芝加哥分校联合发布的一个用于自动驾驶场景的视觉算法测评数据集。它包括“2D框标注和3D点云数据”以及其他的子数据集,在实验中主要使用KITTI的2D框标注数据。
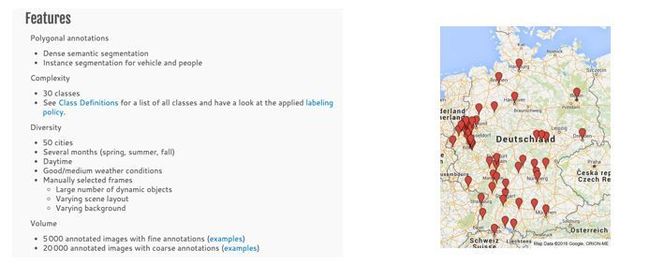
(3)CItyscape 数据集是由Citydcape团队发布的一个致力于城市街景的语义理解的数据集 ,它覆盖了德国50个城市的街景信息 ,数据集中提供了五千张精标的“语义分割和实例分割综合标注”。
下面我们来看一下具体的结果
(1)这是Waymo的测试集的2D框标注可视化结果,我们可以看到它的标注框是非常贴合目标的。

(2)这是训练集 KITTI object2D 的一个训练sample ,那么和前一张图相同,红色的框是KITTI数据集原生的label,蓝色的框是Graviti的标注,可以看到所有的蓝框都要比红框的标注更为准确.

(3)下图是Cityscape 的一个sample,在实验中我们需要将实例的像素信息转换成2D框信息 ,如图中白框所示

实验结果:
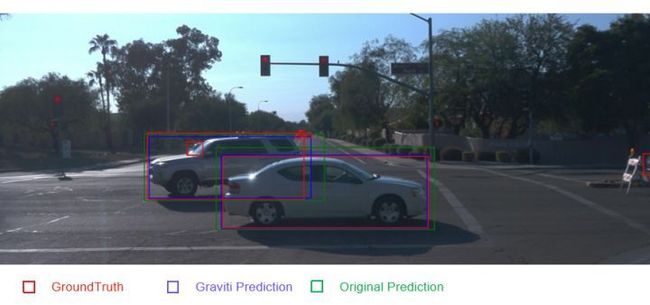
这是两个模型在Waymo数据集上的测试结果 ,图中有三种颜色的框。其中红色是 GroundTruth的预测结果 ,蓝色是Graviti model 的预测结果,绿色是 Original model的预测结果:
从图中我们可以直观的看出,标注这两辆白车的蓝框比绿框更接近红色的Groundtruth
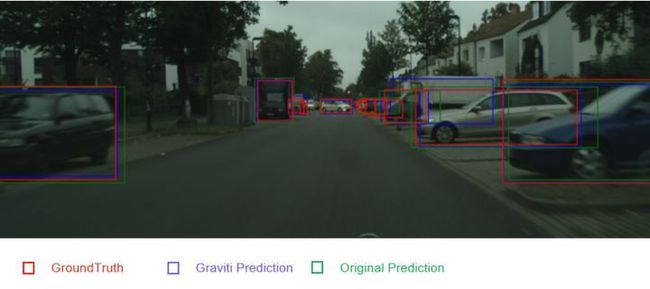
这是两个模型cityscape上的测试结果,同样红色框是Groudtruth,蓝色框是Graviti model的预测结果,绿色的是Original model 的预测结果,以图中右侧第二辆车为例,就是这辆银白色的SUV 。大家可以看到车头处的蓝框比红框更偏内,绿框比红框更为偏外。
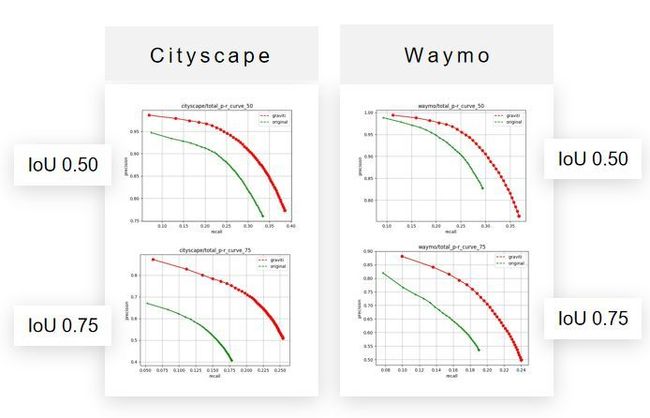
前边是可视化的测试结果,下面借助PR曲线从定量分析的角度来看一下实验的结果 :
简单介绍一下 PR曲线的含义 :
PR曲线的纵坐标是准确率precision,横坐标就是召回率recall。这两个指标结合可以较为全面的评价一个模型的预测质量。
准确率指的是“预测的2D框中有多少是正确的有效的2D框”当然对于“正确”的定义是一个柔性的概念,比如说 :“我可以认为只要预测框和Groundtruth的IoU大于0.5 ,那他就是一个正确的预测。”召回率指的是“所有Groundtruth对应的目标——有所少被正确的预测到了”。如果大家不清楚这个图表的细节 ,那么可以先这样认为 :越偏右上的曲线对应的模型的质量越好。
在这个图表中:红线曲线是Graviti model在不同数据集上的PR曲线, 绿色曲线是Original model 在不同数据集上的PR曲线。
如果横着看这四副图表 :上边两幅是我们的IoU判真阈值——设置为 0.5 时的PR曲线结果,下边两幅是IoU判真阈值设置为 0.75 时的PR曲线结果。
以左上图为例:红色曲线比绿色绿色更偏右上 ——这也意味着 :Graviti model的测试性能要比Original model的测试性能要好。
如果我们竖着看的话,左边是Cityscape数据集上的测试结果 ,右边是Waymo数据集上的测试结果。
以Cityscape数据集为例:当IoU阈值从 0.5 调整到 0.75 之后,也就是当要求提高之后,两条曲线都往左下角偏移了。
这个很好理解类似于——老师的判卷难度提高了,那自然所有考生的分数都会有一定程度的降低, 但是我们可以观察到,红色曲线和绿色曲线之间的的gap拉大了,这说明:当我提高我的IoU阈值时,Graviti model的得分下降程度要远小于 Original model 的下降程度 。
从Waymo这两张图, 也是可以得到类似的结论。

综上无论是从可视化的效果还是PR曲线,我们可以得到比较一致的实验结论,结论有两点,如下:
第一点 :标注质量会直接影响模型质量
好的标注会训练出更好的效果!
第二点:标注越精准,预测的结果越接近真值
当IoU判真阈值设置的更高时,模型依然可以得到更好的表现!
再简单总结一下这个实验中遇到的问题:
1.不同的数据集之间的格式的统一的问题
在众多著名的公开数据集当中,它们的标注格式几乎没有完全相同的两个。

实验中用到的数据集格式也是非常的多样,比如
Waymo的2D框标注呢首先它是TFrecord格式,2D框显示的是xywh的信息;
KITTI数据集的2D框标注是txt格式 ,2D框显示的是XYXY的信息;
Cityscape的2D框标注需要先手动从语义分割转到2D框的标注。

当然这也是一个行业发展的初期一个正常现象 ,就像两千年左右曾经市面上出现的各种各样的手机充电接口一样的,我们Graviti 致力于能够找到一种general的数据标注格式 ,以求能够把大家从繁忙的复杂的数据处理中解放出来,而能够更多focus在我们算法工作过程中。
2.筛选sample
数据集格式统一之后我们还需要筛选具体要用到哪些sample,比如说我们前面提到的Waymo数据集,它是连续采集的数据,但是我们没有必要把所有连续的图像都选做测试集。
所以在这个实验中只是间隔的抽取了一部分图像作为我们的测试集,比如图中3幅较为接近的场景,我们只抽取其中一幅作为测试集,所以筛选sample这一步也会花费大量时间 。

3.类别统一问题
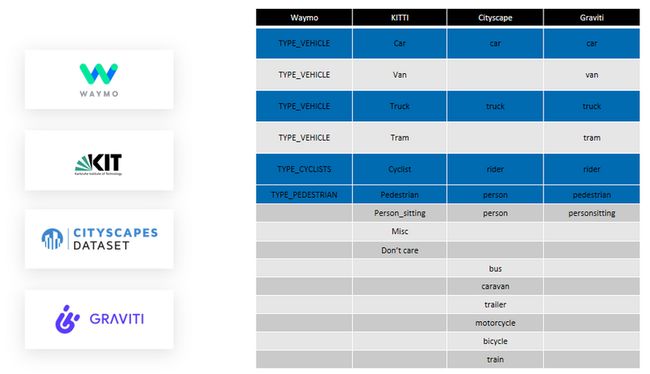
在这个实验中用到了Waymo,KITTI ,Cityscape 三个公开数据集和Graviti KITTI 标注集。
下面的表中列出了 4个数据集之间的label的分类细节,从这个图中我们可以看到 :不论是label的种类,还是label的数量,还有label的划分标准都不尽相同。比如Waymo的VEHICLE类别会包括KITTI的van和tram类别, Cityscape中的bus这一类也并并不完全等同于KITTI的van这一类。
(4)国外的数据集下载
相信大家都深有感触的一点是,很多国外的数据集下载,是需要特殊的工具才能下载, 而且网速非常感人,针对算法工程师对公开数据集使用上的一些痛点,我们也即将在8月下旬上线公开数据集的功能。会提供公开数据集索引,国内站点的下载,并且我们也会提供数据集的标注和标注的可视化,便于大家快速理解数据集标注的可视化,

如果大家对于我们的产品有兴趣可以登录官网使用:http://http://www.graviti.cn/
也可以扫码下面左侧二维码进我们的交流群,欢迎大家给我们更多的反馈,右侧是我们的官方公众号,以了解更多的动态。
