python爬虫把数据保存到csv、mysql中
啧,放假几天游戏玩腻了,啥都不想干,突然想起来python这玩意,无聊就来玩玩
目录
先是保存csv里面
然后保存到mysql里
目标:起点
主要是拿到这几个数据
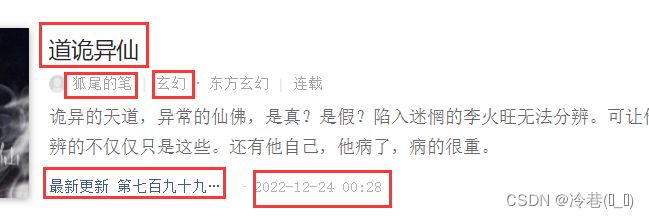
分析下网页
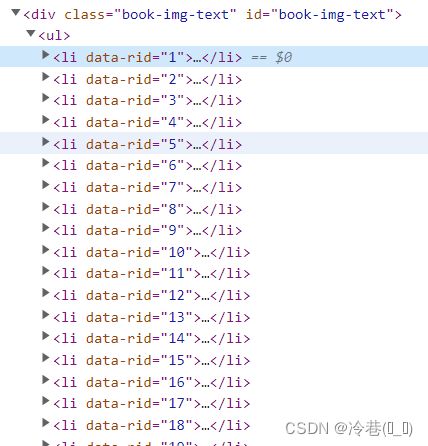
一个li对应一本小说,打开li看里面的东西
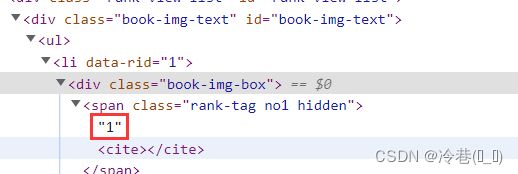
首先是排名
xpath来一下
//div[@class="book-img-text"]/ul/li//div[1]/span/text()名字在第二个div里面

接着是作者
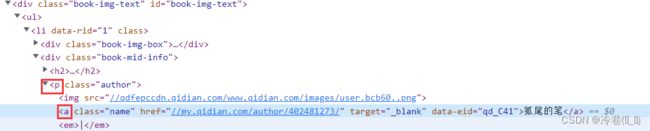
类型

最后是章节和更新时间
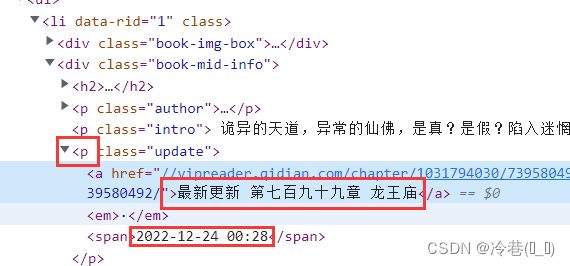
直接上代码
导入库
import pymysql
import requests
import parsel
import csvpymysql是连接mysql
requests是请求库
parsel是解析库
csv是保存到csv文件里面
看一下网址,拿一下请求头,然后直接请求
url = 'https://www.xxxx.com/rank/readindex/page1/' #网址在评论区
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
resp = requests.get(url=url, headers=headers)
resp.encoding = resp.apparent_encoding
print(resp.text)接着解析上面的几个数据
selector = parsel.Selector(resp.text)
li_list = selector.xpath('//div[@class="book-img-text"]/ul/li')
for li in li_list:
pai_ming = li.xpath('./div[1]/span/text()').get()
title = li.xpath('./div[2]/h2/a/text()').get()
man = li.xpath('./div[2]/p[1]/a[1]/text()').get()
lei_xing = li.xpath('./div[2]/p[1]/a[2]/text()').get()
zui_xin = li.xpath('./div[2]/p[3]/a/text()').get()
zui_xin_shi_jian = li.xpath('./div[2]/p[3]/span/text()').get()
print(pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian)
li_list是直接定位到所有标签,用for来拿到li里面的数据,最后再打印

都拿到了,接着就是保存了
先是保存csv里面
k = pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian
with open("qi.csv",mode="a",newline="",encoding='GBK') as f:
a = csv.writer(f)
a.writerow(k)这里把数据的变量给一个新的变量,下面会方便好多,newline是换行,接着encoding用gbk,我这用pycharm打开csv文件正常,但是用电脑打开是乱码的,所以用gbk,如果电脑打开都正常的话直接用utf-8就行了,writerow是写入方法,用writerow直接传一个变量就行了,如果用writerows就要把数据的变量全给它丢进去,麻烦。
保存后用pycharm打开看看

Excel打开也没事
完事。
然后保存到mysql里
首先打开mysql,创建新的数据库来储存数据
创建数据库
create database qidianxiaoshuodb charset utf8;切换到数据库里面
use qidianxiaoshuodb;创建表
create table qidianxiaoshuodb(
排名 varchar(50),
名字 varchar(500),
作者 varchar(500),
类型 varchar(50),
最新章节 varchar(500),
更新时间 varchar(500),
)charset=utf8;回到pycharm开始连接mysql
db = pymysql.connect(host='localhost', user='root', password='xxxxxx', database='qidianxiaoshuodb', charset='utf8')
cursor = db.cursor()执行sql语句
ins = 'insert into qidianxiaoshuodb values(%s,%s,%s,%s,%s,%s)'
xiao_shuo = [pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian]
cursor.execute(ins, xiao_shuo)
db.commit()这里有多少个数据就弄几个%s
commit是提交到数据库执行
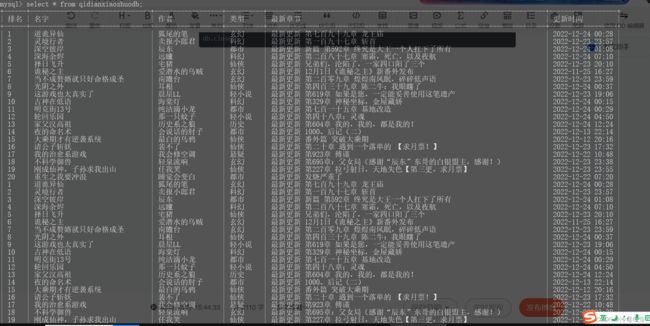
最后断开数据库连接
cursor.close()
db.close()效果如图
多来几页
for i in range(1,5):
url = f'https://www.qidian.com/rank/readindex/page{i}/'完整代码如下
import pymysql
import requests
import parsel
import csv
db = pymysql.connect(host='localhost', user='root', password='xxxxxxxx', database='qidianxiaoshuodb', charset='utf8')
cursor = db.cursor()
for i in range(1,5):
url = f'https://www..com/rank/readindex/page{i}/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
resp = requests.get(url=url, headers=headers)
resp.encoding = resp.apparent_encoding
selector = parsel.Selector(resp.text)
li_list = selector.xpath('//div[@class="book-img-text"]/ul/li')
for li in li_list:
pai_ming = li.xpath('./div[1]/span/text()').get()
title = li.xpath('./div[2]/h2/a/text()').get()
man = li.xpath('./div[2]/p[1]/a[1]/text()').get()
lei_xing = li.xpath('./div[2]/p[1]/a[2]/text()').get()
zui_xin = li.xpath('./div[2]/p[3]/a/text()').get()
zui_xin_shi_jian = li.xpath('./div[2]/p[3]/span/text()').get()
print(pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian)
k = pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian
with open("qi.csv",mode="a",newline="",encoding='GBK') as f:
a = csv.writer(f)
a.writerow(k)
ins = 'insert into qidianxiaoshuodb values(%s,%s,%s,%s,%s,%s)'
xiao_shuo = [pai_ming, title, man, lei_xing, zui_xin, zui_xin_shi_jian]
cursor.execute(ins, xiao_shuo)
db.commit()
cursor.close()
db.close()