GLM 大加强,清华团队推出 GLM 联网加强版 WebGLM!
作者 | 小戏、ZenMoore
大模型生成答案不可靠?一种很直接的思路就是结合传统的搜索引擎的“知识”来对大模型进行一次检索增强。
其实早在 InstructGPT 面世以前,OpenAI 就发布了可以用作搜索结果聚合的模型 WebGPT,WebGPT 基于 GPT-3 试图模仿人类的“搜索行为”以使用搜索引擎获得聚合的搜索答案,从而在比如开放域长问答上收获了非常不错的结果。
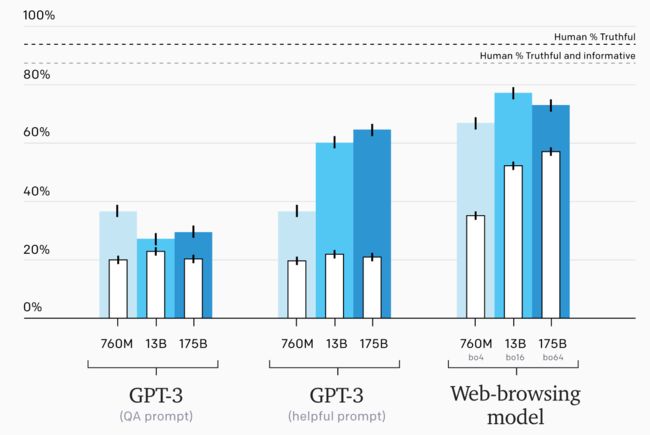
借鉴 WebGPT 结合搜索引擎能力的思路,清华大学唐杰老师团队为目前国内开源大模型的佼佼者 ChatGLM 接上了网线,推出了 ChatGLM 的联网加强版 WebGLM,作为一个基于 GLM-10B 的联网增强版问答系统,WebGLM 可以更加精确高效的完成问答与检索的任务,甚至在实验中可以以 10B 的参数量性能逼近 175B 的 WebGPT 的表现:

目前,WebGLM 公布了代码地址如下,想体验的朋友可以戳链接到达~
论文题目:
WebGLM: Towards An Efficient Web-Enhanced Question
Answering System with Human Preferences
论文链接:
https://arxiv.org/pdf/2306.07906.pdf
项目主页:
https://github.com/THUDM/WebGLM
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
一个官方的使用介绍如下图所示:
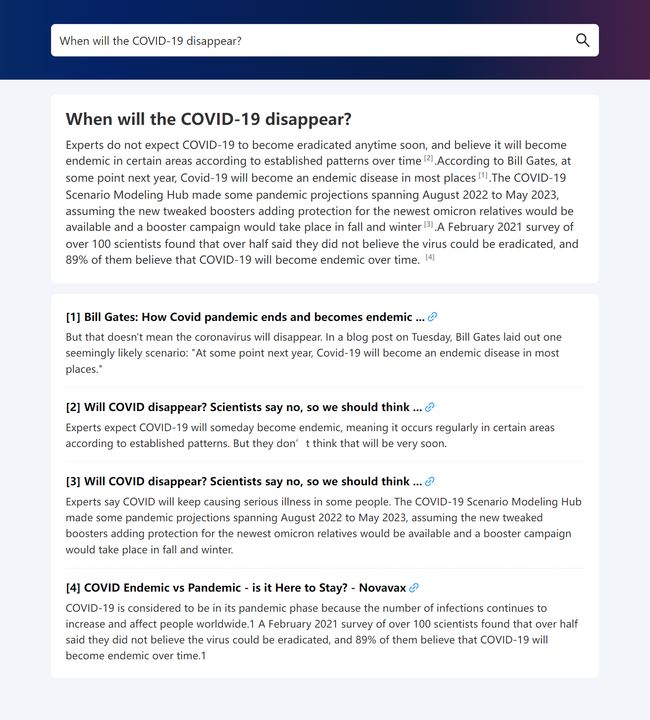
譬如,如果询问疫情何时结束,WebGLM 会“引经据典”的援引不同的网页链接对问题进行回答,可以看到回复还是相当专业,并且也都列出了真实的参考链接,大大增强了模型回复的可信度。
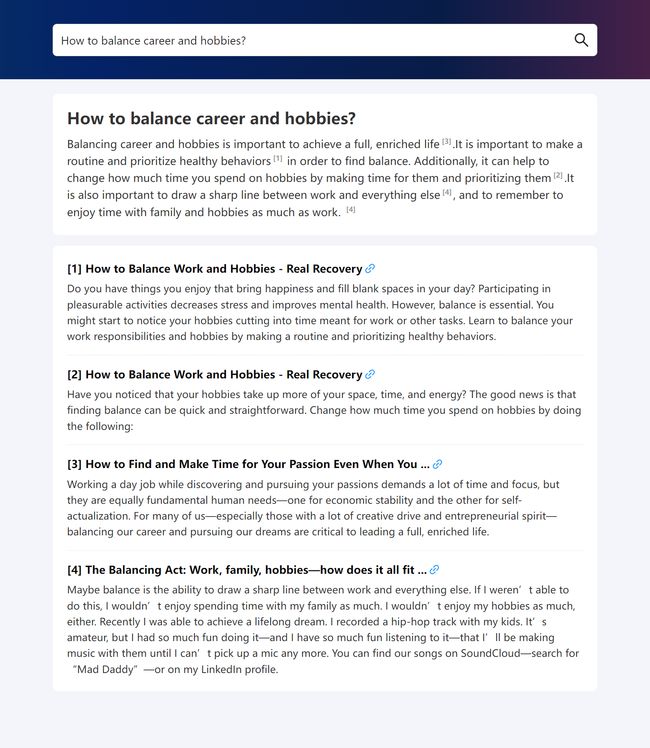
而再看一个例子,关于更“软”一点的问题“如何平衡工作与生活”,WebGLM 也可以很好的处理。
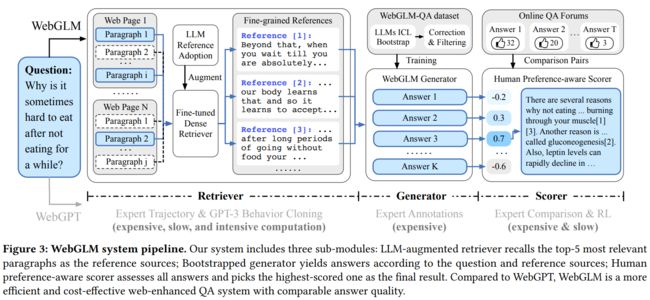
对标 WebGPT,一个网络增强的问题系统一般涉及三个组件,分别是 Retriever,Generator 与 Scorer。Retriever 主要使用大模型来作为一个增强的检索器,在整个 WebGLM 中,检索器的使用分为了两个阶段:
- 粗粒度搜索:整体分为搜索、获取与提取三个阶段,搜索通过使用用户输入的问题,使用 Google API 获取主要候选网页的 URL,获取阶段根据得到的 URL 并行爬取相应的 HTML 的内容,在提取阶段基于 HTML2TEXT 得到页面的文本内容分为段落列表。
- 细粒度搜索:在粗粒度搜索中,仍然有可能会有大量内容与搜索问题无关,因此 WebGLM 综合预训练的 Contriever 检索器与 ChatGLM 对粗粒度搜索的内容进行“提纯”。
在整个过程中,时间主要消耗在获取网页的步骤中,因此 WebGLM 通过使用并行异步的技术大幅加快了页面的加载时间。

而 Generator 部分主要负责从检索器得到的参考页面中生成出高质量的问题答案,这也是作为基于 Web 增强的 GLM 的核心功能。在 WebGPT 中,OpenAI 聘请了一组全职的专家构造包含问题、答案以及有效参考链接的三元组数据集,而在 WebGLM 中,作者团队使用大模型的上下文学习能力构造了一个包含四万五千条过滤数据与八万三千条未过滤数据的问答数据集 WebGLM-QA。
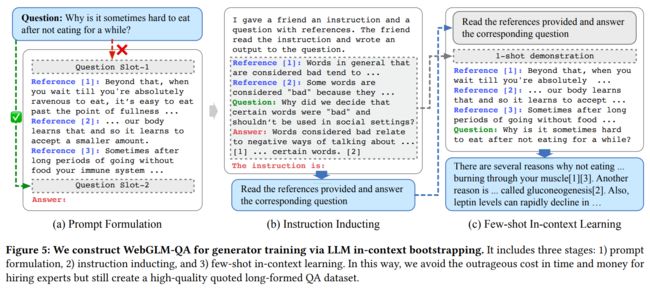
数据集生成应用了大模型出色的上下文学习能力,作者称为 Bootstrapped Generator,步骤方法如上图所示。生成主要分为 Prompt Formulation、Instruction Inducting 以及 Few-shot In-Context Learning 三个阶段,在 Prompt Formulation 中,作者比较了几种 Prompt 方法确定了最优 Prompt,在 Instruction Inducting 中作者采用了 LLM 自我设计指示的方法,以生成问题答案,而在 Few-shot In-Context Learning 中,利用一次学习的方法选择一次展示进行推理,完成数据集的构建。
最后,为了与人类的目标与偏好对齐,WebGLM 又构建了 Scorer 部分,通过使用人类反馈的强化学习来为 WebGLM 生成的答案进行评分,并依据评分对模型进行微调与舍弃了部分样本。整体模型架构如下图所示:
在实验部分,通过主要对答案与参考链接进行评估。在答案评估部分,主要使用流畅性、正确性、真实性、客观性、冗余性与引证准确度六个指标进行评估,在参考链接评估部分,主要使用相关性、密度、真实性、有毒性以及社会偏差五个指标进行评估。
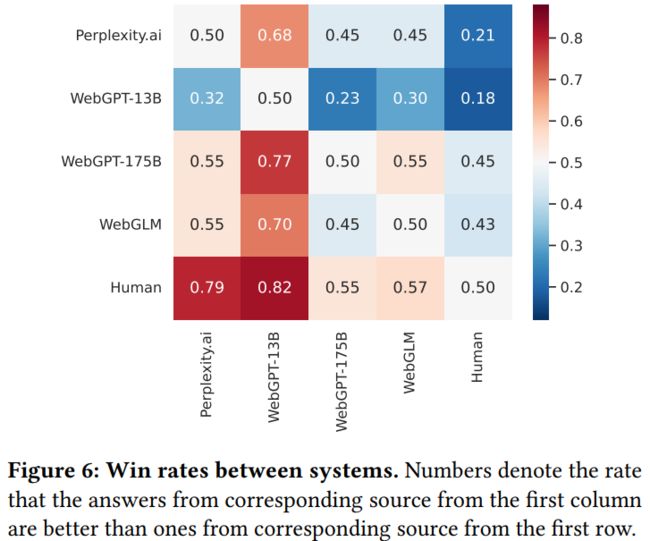
通过 15 位人类专家在 272 个问题上进行打分,可以得到:
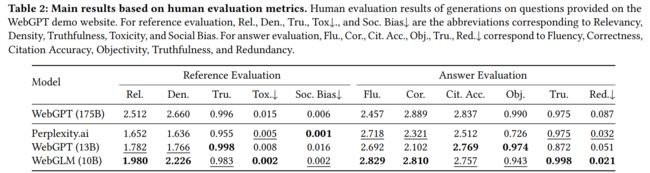
对标 WebGPT-175B,WebGLM 仅仅略显逊色,但其性能远高于 Perplexity.ai 与 WebGPT-13B,甚至在流畅性、真实性与冗余度方面均取得了最高的性能,并在正确率得分中接近了 WebGPT-175B。
此外,作者为了检验 WebGLM 答案的质量,通过将 WebGLM、WebGPT-175B、WebGPT-13B 和 Perplexity.ai 生成的答案进行打乱,再混入人类编写的答案寻找真实人类评估者对答案的质量进行评估,评估以“擂台赛”的方式进行,直接比较得到 A 答案与 B 答案的优劣,构建了一次问答生成的“图灵测试”。结果显示,WebGLM 对标人类也具有 43% 的胜率,几乎与 WebGPT-175B 的 45% 胜率打成平手。