python监控网站学习笔记2——网页中文乱码
一 查询网页编码方式
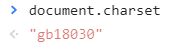
右键——检查——console——输入:document.charset——回车
二 requests的编码方式
爬取的所有网页无论何种编码格式,都转化为utf-8格式进行存储,与源代码编码格式不同所以出现乱码.unicode是一种二进制编码。
1.编码方式为“utf-8”的网页也可能会乱码,那么可以也试试下面的一些函数(对不住,没学过计算机网络,只能先试出来再说了TAT
2.一些乱码解决方式
(1)教务网: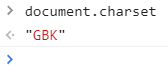 编码方式为GBK
编码方式为GBK
a.xxx.encoding = "utf-8"
含义:
将编码直接转为utf-8
结果:
 加一句这个不行,乱码
加一句这个不行,乱码
所有utf-8和gbk编码都得通过unicode编码进行转译,即utf-8和gbk编码之间不能直接转换。
b.rsp=rsp.text.encode('iso-8859-1').decode('gbk')
含义:
encode('iso-8859-1') 是将gbk编码,编码成unicode编码
decode(‘gbk’) 是从unicode编码解码成gbk字符串
结果:
 和前面那个一样的?
和前面那个一样的?
先解码,再编码
c.rsp=rsp.text.decode('gbk').encode('utf-8')
含义:
先将其GBK解码,然后再UTF-8编码
报错:
Traceback (most recent call last):
File "d:\Programming\python\netScratch\grab_JWW.py", line 11, in
rsp=rsp.text.decode('gbk').encode('utf-8')
AttributeError: 'str' object has no attribute 'decode' d.rsp=rsp.text.decode('utf-8').encode('gbk')
含义:
先对其UTF-8解码,然后再GBK编码
报错:
Traceback (most recent call last):
File "d:\Programming\python\netScratch\grab_JWW.py", line 11, in
rsp=rsp.text.decode('utf-8').encode('gbk')
AttributeError: 'str' object has no attribute 'decode' 报错原因:
浅显地理解字面意思,就是说字符串不能直接编码吗?那就换顺序吧
先编码,再解码
e.rsp=rsp.text.encode('utf-8').decode('gbk')
结果:
 不行,也是乱码
不行,也是乱码
f.rsp=rsp.text.encode('gbk').decode('utf-8')
含义:
先对其gbk编码,再utf-8解码
报错:
Traceback (most recent call last):
File "d:\Programming\python\netScratch\grab_JWW.py", line 11, in
rsp=rsp.text.encode('gbk').decode('utf-8')
UnicodeEncodeError: 'gbk' codec can't encode character '\xbd' in position 590: illegal multibyte sequence 这个意思是说明只能用GBK来解码?
换编码方式
g.rsp=rsp.text.encode('gb18030').decode('gbk')
报错:
Traceback (most recent call last):
File "d:\Programming\python\netScratch\grab_JWW.py", line 14, in
rsp=rsp.text.encode('gb18030').decode('gbk')
UnicodeDecodeError: 'gbk' codec can't decode byte 0x81 in position 590: illegal multibyte sequence 恶魔么么好像还是说编码方式不对?
h.rsp=rsp.text.encode('GB2312').decode('gbk')
报错:
Traceback (most recent call last):
File "d:\Programming\python\netScratch\grab_JWW.py", line 15, in
rsp=rsp.text.encode('GB2312').decode('gbk')
UnicodeEncodeError: 'gb2312' codec can't encode character '\xbd' in position 590: illegal multibyte sequence 怎么这次的报错有点不一样?这个是编不了,前面是解不了,用gbk或者utf-8又编又解也不行,这网页上藏的是啥子妖魔鬼怪哦
查了#微软默认gbk#这个话题,太深奥了,大懵逼。我的理解只能停留在这句话是个真命题这里了5555
WOQU刚刚点开网页源代码一看,教务网原来是gb2312???![]()
网络世界太复杂,我要回农村。。。。。
好吧,刚刚复制粘贴了别人的代码,到我的电脑上来爬下来的就真的全是乱码= =|||||||||
也许和系统的编码方式真的有关系呢?先改了再说
将系统的编码方式改为utf-8的步骤:
开始——更改国家或地区,点进去
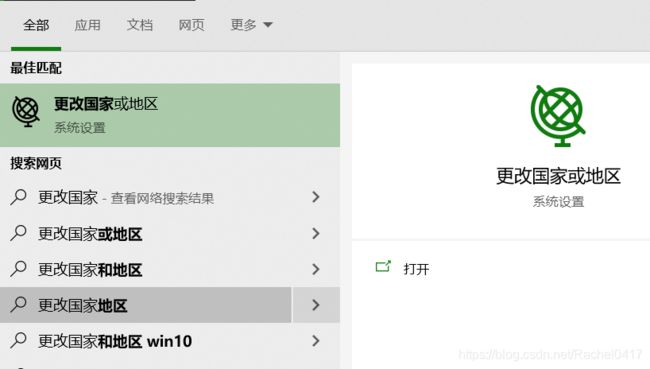
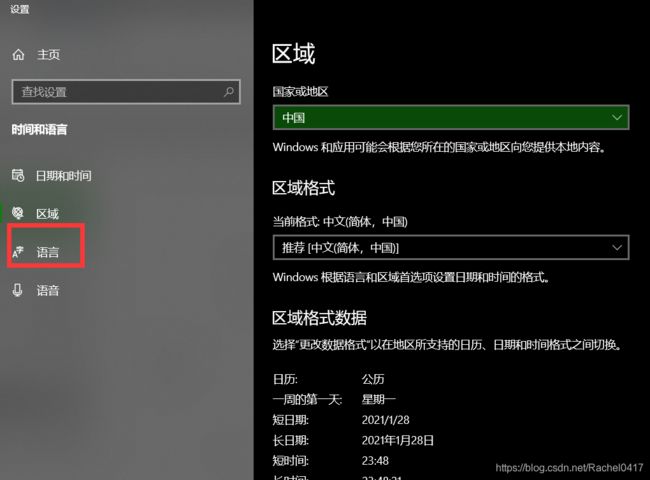


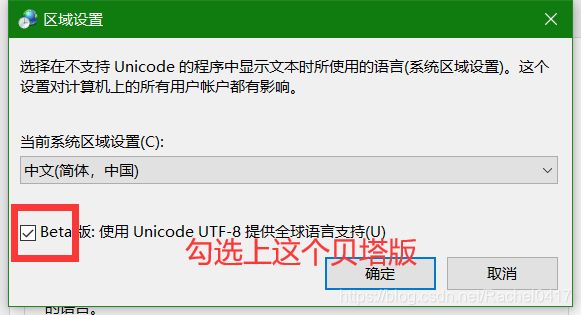
然后等待重启后新生的电脑就可以了!
果然!

我也是能爬下来中文网页的人了!!!泪目!!!
这到底是什么鬼原因,,总之用的是网页源代码上的编码方式
rsp.encoding='gb2312'#这个是最后的解决方案(摔
#以下都是它的妈妈们
#修改encoding为utf-8
#rsp.encoding="utf-8" TypeError: object of type 'Response' has no len()
#rsp.encoding="iso-8859-1"TypeError: object of type 'Response' has no len()
#rsp=rsp.text.encode('utf-8').decode('gbk')中文好像外国文字
#rsp=rsp.text.encode('gbk').decode('utf-8')gbk编不了'\xbd' in position 590
#rsp=rsp.text.decode('gbk').encode('utf-8')字符串不能先解码
#rsp=rsp.text.decode('utf-8').encode('gbk')字符串不能先解码
#rsp=rsp.text.encode('iso-8859-1').decode('gbk')中文大部分是中央是?的站得整整齐齐的正方形
#rsp=rsp.text.encode('gb18030').decode('gbk')gbk解不了0x81 in position 590
#rsp=rsp.text.encode('GB2312').decode('gbk')gb2312编不了'\xbd' in position 590
#rsp=rsp.text.encode('utf-8').decode('gb2312')gb2312解不了0xe3 in position 246
#rsp=rsp.text.encode('gb2312').decode('gb2312')中文大部分是中央是?的站得整整齐齐的正方形
#rsp=rsp.text.encode('gbk').decode('gbk')gbk编不了'\xbd' in position 590
#rsp=rsp.text.encode('utf-8').decode('utf-8')gbk编不了'\xca' in position 0
#rsp=rsp.text.encode('gb18030').decode('gb18030')gbk编不了'\xca' in position 0(2)JJ
不是说“国内的站点一般是utf-8、gbk、gb2312 , 当requests的encoding是这些字符集编码后,是可以直接decode成unicode. ”的吗?
hhh果然小说网站就要用支持少数民族汉字、包含了繁体汉字和日韩汉字、更加全面的GB18030。
这次让我来大显身手吧!!!
把编码方式改为网页源代码的就好
rsp.encoding='gb18030'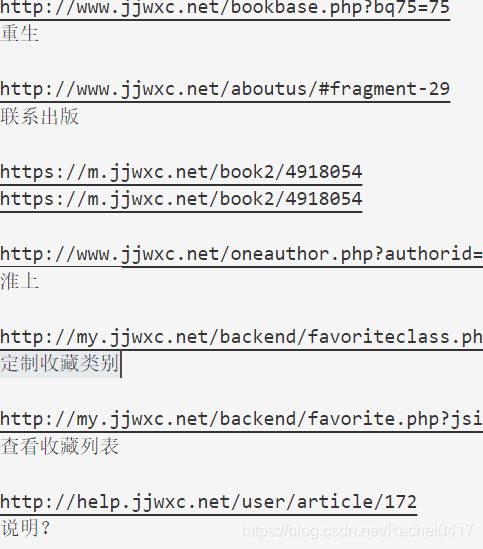
嚯嚯哈哈终于陈工了^w^
附上本次实践的完整代码:
import requests
from bs4 import BeautifulSoup
url='http://www.xxx.net/'
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
header = {'User-Agent':user_agent}
rsp=requests.get(url,headers = header)
rsp.encoding='gb18030'
html=BeautifulSoup(rsp.content,'html.parser')
#没有.content的话会报错:TypeError: object of type 'Response' has no len();rsp是requests对象,无法用BeautifulSoup解析,可以在rsp后面加上content
for link in html.find_all('a'):
#get函数用于获取a标签内容,href内容赋给info_link
info_link=link.get('href')
#get_text函数用于获取a标签中的文字,并去除空格
info_text=link.get_text(strip=True)
print(info_link)
print(info_text+'\n')关于编码的简介这篇写的比较直接:https://www.cnblogs.com/ccsx/p/8572735.html
所以说微软的默认编码方式真的是gbk(深思
那知乎上的回答们我是真没看懂
https://www.zhihu.com/question/34856351/answer/223030044
https://www.zhihu.com/question/20689098特别是这里的第一条,可能是我太浮躁了8