Android基础系列篇(一):注解的那些事儿~
前言
本系列文章主要是汇总了一下大佬们的技术文章,属于Android基础部分,作为一名合格的安卓开发工程师,咱们肯定要熟练掌握java和android,本期就来说说这些~
[非商业用途,如有侵权,请告知我,我会删除]
DD一下: 开发文档跟之前仍旧一样,需要的跟作者直接要。
注解
Annotation 中文译过来就是注解、标释的意思,在 Java 中注解是一个很重要的知识点,但经常还是有点让新手不容易理解。
我个人认为,比较糟糕的技术文档主要特征之一就是:用专业名词来介绍专业名词。 比如:
Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。Java 注解是从 Java5 开始添加到 Java 的。 这是大多数网站上对于 Java 注解,解释确实正确,但是说实在话,我第一次学习的时候,头脑一片空白。这什么跟什么啊?听了像没有听一样。因为概念太过于抽象,所以初学者实在是比较吃力才能够理解,然后随着自己开发过程中不断地强化练习,才会慢慢对它形成正确的认识。
我在写这篇文章的时候,我就在思考。如何让自己或者让读者能够比较直观地认识注解这个概念?是要去官方文档上翻译说明吗?我马上否定了这个答案。
后来,我想到了一样东西————墨水,墨水可以挥发、可以有不同的颜色,用来解释注解正好。
不过,我继续发散思维后,想到了一样东西能够更好地代替墨水,那就是印章。印章可以沾上不同的墨水或者印泥,可以定制印章的文字或者图案,如果愿意它也可以被戳到你任何想戳的物体表面。
但是,我再继续发散思维后,又想到一样东西能够更好地代替印章,那就是标签。标签是一张便利纸,标签上的内容可以自由定义。常见的如货架上的商品价格标签、图书馆中的书本编码标签、实验室中化学材料的名称类别标签等等。
并且,往抽象地说,标签并不一定是一张纸,它可以是对人和事物的属性评价。也就是说,标签具备对于抽象事物的解释。

所以,基于如此,我完成了自我的知识认知升级,我决定用标签来解释注解。
1.注解的定义
注解通过 @interface 关键字进行定义。
public @interface TestAnnotation {
}
它的形式跟接口很类似,不过前面多了一个 @ 符号。上面的代码就创建了一个名字为 TestAnnotaion 的注解。
你可以简单理解为创建了一张名字为 TestAnnotation 的标签。
1.1注解的属性
注解的属性也叫做成员变量。注解只有成员变量,没有方法。注解的成员变量在注解的定义中以“无形参的方法”形式来声明,其方法名定义了该成员变量的名字,其返回值定义了该成员变量的类型。
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {
int id();
String msg();
}
上面代码定义了 TestAnnotation 这个注解中拥有 id 和 msg 两个属性。在使用的时候,我们应该给它们进行赋值。
赋值的方式是在注解的括号内以 value=”” 形式,多个属性之前用 ,隔开。
@TestAnnotation(id=3,msg="hello annotation")
public class Test {
}
需要注意的是,在注解中定义属性时它的类型必须是 8 种基本数据类型外加 类、接口、注解及它们的数组。
注解中属性可以有默认值,默认值需要用 default 关键值指定。比如:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {
public int id() default -1;
public String msg() default "Hi";
}
TestAnnotation 中 id 属性默认值为 -1,msg 属性默认值为 Hi。 它可以这样应用。
@TestAnnotation()
public class Test {}
因为有默认值,所以无需要再在 @TestAnnotation 后面的括号里面进行赋值了,这一步可以省略。
另外,还有一种情况。如果一个注解内仅仅只有一个名字为 value 的属性时,应用这个注解时可以直接接属性值填写到括号内。
public @interface Check {
String value();
}
上面代码中,Check 这个注解只有 value 这个属性。所以可以这样应用。
@Check("hi")
int a;
这和下面的效果是一样的
@Check(value="hi")
int a;
最后,还需要注意的一种情况是一个注解没有任何属性。比如
public @interface Perform {}
那么在应用这个注解的时候,括号都可以省略。
@Perform
public void testMethod(){}
2.自定义注解
2.1注解如同标签
之前某新闻客户端的评论有盖楼的习惯,于是 “乔布斯重新定义了手机、罗永浩重新定义了傻X” 就经常极为工整地出现在了评论楼层中,并且广大网友在相当长的一段时间内对于这种行为乐此不疲。这其实就是等同于贴标签的行为。 在某些网友眼中,罗永浩就成了傻X的代名词。
广大网友给罗永浩贴了一个名为“傻x”的标签,他们并不真正了解罗永浩,不知道他当教师、砸冰箱、办博客的壮举,但是因为“傻x”这样的标签存在,这有助于他们直接快速地对罗永浩这个人做出评价,然后基于此,罗永浩就可以成为茶余饭后的谈资,这就是标签的力量。
而在网络的另一边,老罗靠他的人格魅力自然收获一大批忠实的拥泵,他们对于老罗贴的又是另一种标签。

老罗还是老罗,但是由于人们对于它贴上的标签不同,所以造成对于他的看法大相径庭,不喜欢他的人整天在网络上评论抨击嘲讽,而崇拜欣赏他的人则会愿意挣钱购买锤子手机的发布会门票。
我无意于评价这两种行为,我再引个例子。
《奇葩说》是近年网络上非常火热的辩论节目,其中辩手陈铭被另外一个辩手马薇薇攻击说是————“站在宇宙中心呼唤爱”,然后贴上了一个大大的标签————“鸡汤男”,自此以后,观众再看到陈铭的时候,首先映入脑海中便是“鸡汤男”三个大字,其实本身而言陈铭非常优秀,为人师表、作风正派、谈吐举止得体,但是在网络中,因为娱乐至上的环境所致,人们更愿意以娱乐的心态来认知一切,于是“鸡汤男”就如陈铭自己所说成了一个撕不了的标签。
我们可以抽象概括一下,标签是对事物行为的某些角度的评价与解释。
到这里,终于可以引出本文的主角注解了。
初学者可以这样理解注解:想像代码具有生命,注解就是对于代码中某些鲜活个体的贴上去的一张标签。简化来讲,注解如同一张标签。
在未开始学习任何注解具体语法而言,你可以把注解看成一张标签。这有助于你快速地理解它的大致作用。如果初学者在学习过程有大脑放空的时候,请不要慌张,对自己说:
注解,标签。注解,标签。
2.2注解语法
因为平常开发少见,相信有不少的人员会认为注解的地位不高。其实同 classs 和 interface 一样,注解也属于一种类型。它是在 Java SE 5.0 版本中开始引入的概念。
2.3元注解
元注解是什么意思呢?
元注解是可以注解到注解上的注解,或者说元注解是一种基本注解,但是它能够应用到其它的注解上面。
如果难于理解的话,你可以这样理解。元注解也是一张标签,但是它是一张特殊的标签,它的作用和目的就是给其他普通的标签进行解释说明的。
元标签有 @Retention、@Documented、@Target、@Inherited、@Repeatable 5 种。
@Retention
Retention 的英文意为保留期的意思。当 @Retention 应用到一个注解上的时候,它解释说明了这个注解的的存活时间。
它的取值如下:
- RetentionPolicy.SOURCE 注解只在源码阶段保留,在编译器进行编译时它将被丢弃忽视。
- RetentionPolicy.CLASS 注解只被保留到编译进行的时候,它并不会被加载到 JVM 中。
- RetentionPolicy.RUNTIME 注解可以保留到程序运行的时候,它会被加载进入到 JVM 中,所以在程序运行时可以获取到它们。
我们可以这样的方式来加深理解,@Retention 去给一张标签解释的时候,它指定了这张标签张贴的时间。@Retention 相当于给一张标签上面盖了一张时间戳,时间戳指明了标签张贴的时间周期。
@Retention(RetentionPolicy.RUNTIME)
public @interface TestAnnotation {
}
上面的代码中,我们指定 TestAnnotation 可以在程序运行周期被获取到,因此它的生命周期非常的长。
@Documented
顾名思义,这个元注解肯定是和文档有关。它的作用是能够将注解中的元素包含到 Javadoc 中去。
@Target
Target 是目标的意思,@Target 指定了注解运用的地方。
你可以这样理解,当一个注解被 @Target 注解时,这个注解就被限定了运用的场景。
类比到标签,原本标签是你想张贴到哪个地方就到哪个地方,但是因为 @Target 的存在,它张贴的地方就非常具体了,比如只能张贴到方法上、类上、方法参数上等等。@Target 有下面的取值
- ElementType.ANNOTATION_TYPE 可以给一个注解进行注解
- ElementType.CONSTRUCTOR 可以给构造方法进行注解
- ElementType.FIELD 可以给属性进行注解
- ElementType.LOCAL_VARIABLE 可以给局部变量进行注解
- ElementType.METHOD 可以给方法进行注解
- ElementType.PACKAGE 可以给一个包进行注解
- ElementType.PARAMETER 可以给一个方法内的参数进行注解
- ElementType.TYPE 可以给一个类型进行注解,比如类、接口、枚举
@Inherited
Inherited 是继承的意思,但是它并不是说注解本身可以继承,而是说如果一个超类被 @Inherited 注解过的注解进行注解的话,那么如果它的子类没有被任何注解应用的话,那么这个子类就继承了超类的注解。 说的比较抽象。代码来解释。
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@interface Test {}
@Test
public class A {}
public class B extends A {}
注解 Test 被 @Inherited 修饰,之后类 A 被 Test 注解,类 B 继承 A,类 B 也拥有 Test 这个注解。
可以这样理解:
老子非常有钱,所以人们给他贴了一张标签叫做富豪。
老子的儿子长大后,只要没有和老子断绝父子关系,虽然别人没有给他贴标签,但是他自然也是富豪。
老子的孙子长大了,自然也是富豪。
这就是人们口中戏称的富一代,富二代,富三代。虽然叫法不同,好像好多个标签,但其实事情的本质也就是他们有一张共同的标签,也就是老子身上的那张富豪的标签。
@Repeatable
Repeatable 自然是可重复的意思。@Repeatable 是 Java 1.8 才加进来的,所以算是一个新的特性。
什么样的注解会多次应用呢?通常是注解的值可以同时取多个。
举个例子,一个人他既是程序员又是产品经理,同时他还是个画家。
@interface Persons {
Person[] value();
}
@Repeatable(Persons.class)
@interface Person{
String role default "";
}
@Person(role="artist")
@Person(role="coder")
@Person(role="PM")
public class SuperMan{
}
注意上面的代码,@Repeatable 注解了 Person。而 @Repeatable 后面括号中的类相当于一个容器注解。
什么是容器注解呢?就是用来存放其它注解的地方。它本身也是一个注解。
我们再看看代码中的相关容器注解。
@interface Persons {
Person[] value();
}
按照规定,它里面必须要有一个 value 的属性,属性类型是一个被 @Repeatable 注解过的注解数组,注意它是数组。
如果不好理解的话,可以这样理解。Persons 是一张总的标签,上面贴满了 Person 这种同类型但内容不一样的标签。把 Persons 给一个 SuperMan 贴上,相当于同时给他贴了程序员、产品经理、画家的标签。
我们可能对于 @Person(role=”PM”) 括号里面的内容感兴趣,它其实就是给 Person 这个注解的 role 属性赋值为 PM ,大家不明白正常,马上就讲到注解的属性这一块。
2.4Java 预置的注解
Java 语言本身已经提供了几个现成的注解。
@Deprecated
这个元素是用来标记过时的元素,想必大家在日常开发中经常碰到。编译器在编译阶段遇到这个注解时会发出提醒警告,告诉开发者正在调用一个过时的元素比如过时的方法、过时的类、过时的成员变量。
public class Hero {
@Deprecated
public void say(){
System.out.println("Noting has to say!");
}
public void speak(){
System.out.println("I have a dream!");
}
}
定义了一个 Hero 类,它有两个方法 say() 和 speak() ,其中 say() 被 @Deprecated 注解。然后我们在 IDE 中分别调用它们。
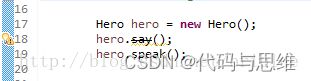
可以看到,say() 方法上面被一条直线划了一条,这其实就是编译器识别后的提醒效果。
@Override
这个大家应该很熟悉了,提示子类要复写父类中被 @Override 修饰的方法
@SuppressWarnings
阻止警告的意思。之前说过调用被 @Deprecated 注解的方法后,编译器会警告提醒,而有时候开发者会忽略这种警告,他们可以在调用的地方通过 @SuppressWarnings 达到目的。
@SuppressWarnings("deprecation")
public void test1(){
Hero hero = new Hero();
hero.say();
hero.speak();
}
@SafeVarargs
参数安全类型注解。它的目的是提醒开发者不要用参数做一些不安全的操作,它的存在会阻止编译器产生 unchecked 这样的警告。它是在 Java 1.7 的版本中加入的。
@SafeVarargs // Not actually safe!
static void m(List... stringLists) {
Object[] array = stringLists;
List tmpList = Arrays.asList(42);
array[0] = tmpList; // Semantically invalid, but compiles without warnings
String s = stringLists[0].get(0); // Oh no, ClassCastException at runtime!
}
上面的代码中,编译阶段不会报错,但是运行时会抛出 ClassCastException 这个异常,所以它虽然告诉开发者要妥善处理,但是开发者自己还是搞砸了。
Java 官方文档说,未来的版本会授权编译器对这种不安全的操作产生错误警告。
@FunctionalInterface
函数式接口注解,这个是 Java 1.8 版本引入的新特性。函数式编程很火,所以 Java 8 也及时添加了这个特性。
函数式接口 (Functional Interface) 就是一个具有一个方法的普通接口。 比如
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface Runnable is used
* to create a thread, starting the thread causes the object's
* run method to be called in that separately executing
* thread.
*
* The general contract of the method run is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
我们进行线程开发中常用的 Runnable 就是一个典型的函数式接口,上面源码可以看到它就被 @FunctionalInterface 注解。
可能有人会疑惑,函数式接口标记有什么用,这个原因是函数式接口可以很容易转换为 Lambda 表达式。这是另外的主题了,有兴趣的同学请自己搜索相关知识点学习。
3.注解的使用
3.1注解的应用
上面创建了一个注解,那么注解的的使用方法是什么呢。
@TestAnnotation
public class Test {
}
创建一个类 Test,然后在类定义的地方加上 @TestAnnotation 就可以用 TestAnnotation 注解这个类了。
你可以简单理解为将 TestAnnotation 这张标签贴到 Test 这个类上面。
3.2注解的提取
前面的部分讲了注解的基本语法,现在是时候检测我们所学的内容了。
我通过用标签来比作注解,前面的内容是讲怎么写注解,然后贴到哪个地方去,而现在我们要做的工作就是检阅这些标签内容。 形象的比喻就是你把这些注解标签在合适的时候撕下来,然后检阅上面的内容信息。
要想正确检阅注解,离不开一个手段,那就是反射。
3.3注解与反射
注解通过反射获取。首先可以通过 Class 对象的 isAnnotationPresent() 方法判断它是否应用了某个注解
public boolean isAnnotationPresent(Class annotationClass) {}
然后通过 getAnnotation() 方法来获取 Annotation 对象。
public A getAnnotation(Class annotationClass) {}
或者是 getAnnotations() 方法。
public Annotation[] getAnnotations() {}
前一种方法返回指定类型的注解,后一种方法返回注解到这个元素上的所有注解。
如果获取到的 Annotation 如果不为 null,则就可以调用它们的属性方法了。比如
@TestAnnotation()
public class Test {
public static void main(String[] args) {
boolean hasAnnotation = Test.class.isAnnotationPresent(TestAnnotation.class);
if ( hasAnnotation ) {
TestAnnotation testAnnotation = Test.class.getAnnotation(TestAnnotation.class);
System.out.println("id:"+testAnnotation.id());
System.out.println("msg:"+testAnnotation.msg());
}
}
}
程序的运行结果是:
id:-1
msg:
这个正是 TestAnnotation 中 id 和 msg 的默认值。
上面的例子中,只是检阅出了注解在类上的注解,其实属性、方法上的注解照样是可以的。同样还是要假手于反射。
@TestAnnotation(msg="hello")
public class Test {
@Check(value="hi")
int a;
@Perform
public void testMethod(){}
@SuppressWarnings("deprecation")
public void test1(){
Hero hero = new Hero();
hero.say();
hero.speak();
}
public static void main(String[] args) {
boolean hasAnnotation = Test.class.isAnnotationPresent(TestAnnotation.class);
if ( hasAnnotation ) {
TestAnnotation testAnnotation = Test.class.getAnnotation(TestAnnotation.class);
//获取类的注解
System.out.println("id:"+testAnnotation.id());
System.out.println("msg:"+testAnnotation.msg());
}
try {
Field a = Test.class.getDeclaredField("a");
a.setAccessible(true);
//获取一个成员变量上的注解
Check check = a.getAnnotation(Check.class);
if ( check != null ) {
System.out.println("check value:"+check.value());
}
Method testMethod = Test.class.getDeclaredMethod("testMethod");
if ( testMethod != null ) {
// 获取方法中的注解
Annotation[] ans = testMethod.getAnnotations();
for( int i = 0;i < ans.length;i++) {
System.out.println("method testMethod annotation:"+ans[i].annotationType().getSimpleName());
}
}
} catch (NoSuchFieldException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println(e.getMessage());
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println(e.getMessage());
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.out.println(e.getMessage());
}
}
}
它们的结果如下:
id:-1
msg:hello
check value:hi
method testMethod annotation:Perform
需要注意的是,如果一个注解要在运行时被成功提取,那么 @Retention(RetentionPolicy.RUNTIME) 是必须的。
3.4注解的使用场景
我相信博文讲到这里大家都很熟悉了注解,但是有不少同学肯定会问,注解到底有什么用呢?
对啊注解到底有什么用?
我们不妨将目光放到 Java 官方文档上来。
文章开始的时候,我用标签来类比注解。但标签比喻只是我的手段,而不是目的。为的是让大家在初次学习注解时能够不被那些抽象的新概念搞懵。既然现在,我们已经对注解有所了解,我们不妨再仔细阅读官方最严谨的文档。
注解是一系列元数据,它提供数据用来解释程序代码,但是注解并非是所解释的代码本身的一部分。注解对于代码的运行效果没有直接影响。 注解有许多用处,主要如下:
- 提供信息给编译器: 编译器可以利用注解来探测错误和警告信息
- 编译阶段时的处理: 软件工具可以用来利用注解信息来生成代码、Html文档或者做其它相应处理。
- 运行时的处理: 某些注解可以在程序运行的时候接受代码的提取 值得注意的是,注解不是代码本身的一部分。
如果难于理解,可以这样看。罗永浩还是罗永浩,不会因为某些人对于他“傻x”的评价而改变,标签只是某些人对于其他事物的评价,但是标签不会改变事物本身,标签只是特定人群的手段。所以,注解同样无法改变代码本身,注解只是某些工具的的工具。
还是回到官方文档的解释上,注解主要针对的是编译器和其它工具软件(SoftWare tool)。
当开发者使用了Annotation 修饰了类、方法、Field 等成员之后,这些 Annotation 不会自己生效,必须由开发者提供相应的代码来提取并处理 Annotation 信息。这些处理提取和处理 Annotation 的代码统称为 APT(Annotation Processing Tool)。
现在,我们可以给自己答案了,注解有什么用?给谁用?给 编译器或者 APT 用的。
如果,你还是没有搞清楚的话,我亲自写一个好了。
3.5亲手自定义注解完成项目
我要写一个测试框架,测试程序员的代码有无明显的异常。
—— 程序员 A : 我写了一个类,它的名字叫做 NoBug,因为它所有的方法都没有错误。 —— 我:自信是好事,不过为了防止意外,让我测试一下如何? —— 程序员 A: 怎么测试? —— 我:把你写的代码的方法都加上 @Jiecha 这个注解就好了。 —— 程序员 A: 好的。
package ceshi;
import ceshi.Jiecha;
public class NoBug {
@Jiecha
public void suanShu(){
System.out.println("1234567890");
}
@Jiecha
public void jiafa(){
System.out.println("1+1="+1+1);
}
@Jiecha
public void jiefa(){
System.out.println("1-1="+(1-1));
}
@Jiecha
public void chengfa(){
System.out.println("3 x 5="+ 3*5);
}
@Jiecha
public void chufa(){
System.out.println("6 / 0="+ 6 / 0);
}
public void ziwojieshao(){
System.out.println("我写的程序没有 bug!");
}
}
上面的代码,有些方法上面运用了 @Jiecha 注解。
这个注解是我写的测试软件框架中定义的注解。
package ceshi;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
@Retention(RetentionPolicy.RUNTIME)
public @interface Jiecha {
}
然后,我再编写一个测试类 TestTool 就可以测试 NoBug 相应的方法了。
package ceshi;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class TestTool {
public static void main(String[] args) {
// TODO Auto-generated method stub
NoBug testobj = new NoBug();
Class clazz = testobj.getClass();
Method[] method = clazz.getDeclaredMethods();
//用来记录测试产生的 log 信息
StringBuilder log = new StringBuilder();
// 记录异常的次数
int errornum = 0;
for ( Method m: method ) {
// 只有被 @Jiecha 标注过的方法才进行测试
if ( m.isAnnotationPresent( Jiecha.class )) {
try {
m.setAccessible(true);
m.invoke(testobj, null);
} catch (Exception e) {
// TODO Auto-generated catch block
//e.printStackTrace();
errornum++;
log.append(m.getName());
log.append(" ");
log.append("has error:");
log.append("\n\r caused by ");
//记录测试过程中,发生的异常的名称
log.append(e.getCause().getClass().getSimpleName());
log.append("\n\r");
//记录测试过程中,发生的异常的具体信息
log.append(e.getCause().getMessage());
log.append("\n\r");
}
}
}
log.append(clazz.getSimpleName());
log.append(" has ");
log.append(errornum);
log.append(" error.");
// 生成测试报告
System.out.println(log.toString());
}
}
测试的结果是:
1234567890
1+1=11
1-1=0
3 x 5=15
chufa has error:
caused by ArithmeticException
/ by zero
NoBug has 1 error.
提示 NoBug 类中的 chufa() 这个方法有异常,这个异常名称叫做 ArithmeticException,原因是运算过程中进行了除 0 的操作。
所以,NoBug 这个类有 Bug。
这样,通过注解我完成了我自己的目的,那就是对别人的代码进行测试。
所以,再问我注解什么时候用?我只能告诉你,这取决于你想利用它干什么用。
3.6注解应用实例
注解运用的地方太多了,如: JUnit 这个是一个测试框架,典型使用方法如下:
public class ExampleUnitTest {
@Test
public void addition_isCorrect() throws Exception {
assertEquals(4, 2 + 2);
}
}
@Test 标记了要进行测试的方法 addition_isCorrect().
还有例如ssm框架等运用了大量的注解。
注解部分总结
- 如果注解难于理解,你就把它类同于标签,标签为了解释事物,注解为了解释代码。
- 注解的基本语法,创建如同接口,但是多了个 @ 符号。
- 注解的元注解。
- 注解的属性。
- 注解主要给编译器及工具类型的软件用的。
- 注解的提取需要借助于 Java 的反射技术,反射比较慢,所以注解使用时也需要谨慎计较时间成本。
4.APT实现原理
4.1 SPI机制
SPI是jdk内置的服务发现机制, 全称叫Service Provider Interface.
SPI的工作原理, 就是ClassPath路径下的META-INF/services文件夹中, 以接口的全限定名来命名文件名, 文件里面写该接口的实现。 然后再资源加载的方式,读取文件的内容(接口实现的全限定名), 然后再去加载类。
SPI可以很灵活的让接口和实现分离, 让api提供者只提供接口, 第三方来实现。
这一机制为很多框架的扩展提供了可能,比如在 Dubbo、JDBC、SpringBoot 中都使用到了SPI机制。虽然他们之间的实现方式不同,但原理都差不多。今天我们就来看看,SPI到底是何方神圣,在众多开源框架中又扮演了什么角色。
4.1.1 JDK中的SPI
我们先从JDK开始,通过一个很简单的例子来看下它是怎么用的。
4.1.1.1、小栗子
首先,我们需要定义一个接口,SpiService
package com.dxz.jdk.spi;
public interface SpiService {
void println();
}
然后,定义一个实现类,没别的意思,只做打印。
package com.dxz.jdk.spi;
public class SpiServiceImpl implements SpiService {
@Override
public void println() {
System.out.println("------SPI DEMO-------");
}
}
最后呢,要在resources路径下配置添加一个文件。文件名字是接口的全限定类名,内容是实现类的全限定类名,多个实现类用换行符分隔。
文件内容就是实现类的全限定类名:
4.1.1.2、测试
然后我们就可以通过 ServiceLoader.load 方法拿到实现类的实例,并调用它的方法。
public static void main(String[] args){
ServiceLoader load = ServiceLoader.load(SpiService.class);
Iterator iterator = load.iterator();
while (iterator.hasNext()){
SpiService service = iterator.next();
service.println();
}
}
4.1.1.3、源码分析
首先,我们先来了解下 ServiceLoader,看看它的类结构。
public final class ServiceLoader implements Iterable{
//配置文件的路径
private static final String PREFIX = "META-INF/services/";
//加载的服务类或接口
private final Class service;
//已加载的服务类集合
private LinkedHashMap providers = new LinkedHashMap<>();
//类加载器
private final ClassLoader loader;
//内部类,真正加载服务类
private LazyIterator lookupIterator;
}
当我们调用 load 方法时,并没有真正的去加载和查找服务类。而是调用了 ServiceLoader 的构造方法,在这里最重要的是实例化了内部类 LazyIterator ,它才是接下来的主角。
private ServiceLoader(Class svc, ClassLoader cl) {
//要加载的接口
service = Objects.requireNonNull(svc, "Service interface cannot be null");
//类加载器
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
//访问控制器
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
//先清空
providers.clear();
//实例化内部类
LazyIterator lookupIterator = new LazyIterator(service, loader);
}
查找实现类和创建实现类的过程,都在 LazyIterator 完成。当我们调用 iterator.hasNext和iterator.next 方法的时候,实际上调用的都是 LazyIterator 的相应方法。
public Iterator iterator() {
return new Iterator() {
public boolean hasNext() {
return lookupIterator.hasNext();
}
public S next() {
return lookupIterator.next();
}
.......
};
}
所以,我们重点关注 lookupIterator.hasNext() 方法,它最终会调用到 hasNextServicez ,在这里返回实现类名称。
private class LazyIterator implements Iterator{
Class service;
ClassLoader loader;
Enumeration configs = null;
Iterator pending = null;
String nextName = null;
private boolean hasNextService() {
//第二次调用的时候,已经解析完成了,直接返回
if (nextName != null) {
return true;
}
if (configs == null) {
//META-INF/services/ 加上接口的全限定类名,就是文件服务类的文件
//META-INF/services/com.viewscenes.netsupervisor.spi.SPIService
String fullName = PREFIX + service.getName();
//将文件路径转成URL对象
configs = loader.getResources(fullName);
}
while ((pending == null) || !pending.hasNext()) {
//解析URL文件对象,读取内容,最后返回
pending = parse(service, configs.nextElement());
}
//拿到第一个实现类的类名
nextName = pending.next();
return true;
}
}
然后当我们调用 next() 方法的时候,调用到 lookupIterator.nextService 。它通过反射的方式,创建实现类的实例并返回。
private S nextService() {
//全限定类名
String cn = nextName;
nextName = null;
//创建类的Class对象
Class c = Class.forName(cn, false, loader);
//通过newInstance实例化
S p = service.cast(c.newInstance());
//放入集合,返回实例
providers.put(cn, p);
return p;
}
到这为止,已经获取到了类的实例。
4.1.2 JDBC中的应用
我们开头说,SPI机制为很多框架的扩展提供了可能,其实JDBC就应用到了这一机制。
在以前,需要先设置数据库驱动的连接,再通过 DriverManager.getConnection 获取一个 Connection 。
String url = "jdbc:mysql:///consult?serverTimezone=UTC";
String user = "root";
String passwor d = "r oot";
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, user, password);
而现在,设置数据库驱动连接,这一步骤就不再需要,那么它是怎么分辨是哪种数据库的呢?答案就在SPI。
4.1.2.1 加载
下图mysql Driver的实例。 com.mysql.cj.jdbc.Driver就是Driver的实现。
mysql驱动为例

mysql Driver实现类
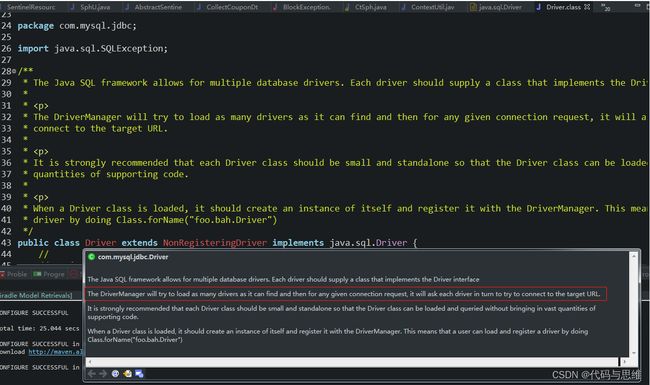
Driver接口上的一段注释。
DriverManager将尝试加载尽可能多的驱动程序。
我们把目光回到 DriverManager 类,它在静态代码块里面做了一件比较重要的事。很明显,它已经通过SPI机制, 把数据库驱动连接初始化了。
public class DriverManager {
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
}
接下来我们去DriverManger上看看是如何加载Driver接口的实现类的。
public class DriverManager {
/**
* Load the initial JDBC drivers by checking the System property
* jdbc.properties and then use the {@code ServiceLoader} mechanism
*/
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
private static void loadInitialDrivers() {
AccessController.doPrivileged(new PrivilegedAction() {
public Void run() {
ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class);
Iterator driversIterator = loadedDrivers.iterator();
try{
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
}
return null;
}
});
}
在DriverManger类初始化的时候, 调用loadInitialDrivers方法。
具体过程还得看 loadInitialDrivers ,它在里面查找的是Driver接口的服务类,所以它的文件路径就是:
META-INF/services/java.sql.Driver
在loadInitialDrivers方法中,
private static void loadInitialDrivers() {
AccessController.doPrivileged(new PrivilegedAction() {
public Void run() {
//很明显,它要加载Driver接口的服务类,Driver接口的包为:java.sql.Driver
//所以它要找的就是META-INF/services/java.sql.Driver文件
ServiceLoader loadedDrivers = ServiceLoader.load(Driver.class);
Iterator driversIterator = loadedDrivers.iterator();
try{
//查到之后创建对象
while(driversIterator.hasNext()) {
driversIterator.next();//当调用next方法时,就会创建这个类的实例。它就完成了一件事,向 DriverManager 注册自身的实例。
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
}
这段代码是实现SPI的关键, 真是这个ServiceLoader类去实现SPI的。 那么下面就分析分析ServiceLoader的代码, 看看是如何实现SPI的。
package java.util;
public final class ServiceLoader implements Iterable {
public static ServiceLoader load(Class service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
//其中service就是要加载实现类对应的接口, loader就是用该加载器去加载对应的实现类
public static ServiceLoader load(Class service, ClassLoader loader){
return new ServiceLoader<>(service, loader);
}
}
先调用ServiceLoader类的静态方法load, 然后根据当前线程的上下文类加载器,创建一个ServiceLoader实例。
private static final String PREFIX = "META-INF/services/";
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
private ServiceLoader(Class svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
创建ServiceLoader实例的时候,接着创建一个Iterator实现类。 接下来这个Iterator分析的重点。基本所有的加载类的实现逻辑都在里面。
其中ServiceLoader类中一个常量的定义是关键的。 前面说过,我们service的实现类在放在哪, 就是这里写死的常量路径。
//这里先介绍Iterator的变量,先大概有个印象。
private class LazyIterator
implements Iterator
{
//service, loader前面介绍过了。
Class service;
ClassLoader loader;
Enumeration configs = null;
Iterator pending = null;
String nextName = null;
public boolean hasNext() {
//省略权限相关代码
return hasNextService();
}
private boolean hasNextService() {
//一开始nextName肯定为空
if (nextName != null) {
return true;
}
//一开始configs也肯定为空
if (configs == null) {
try {
//PREFIX = META-INF/services/
//以mysql为例,就是 META-INF/services/java.sql.Driver
String fullName = PREFIX + service.getName();
if (loader == null) configs = ClassLoader.getSystemResources(fullName);
//loader去加载这个classpath下文件。
//这里很有可能返回的是多个文件的资源,
//例如一个项目下既有mysql驱动, 也有sql server驱动等
//所以返回的是一个枚举类型。
else configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
//然后根据加载出来的资源,解析一个文件中的内容。放到Iterator实现类中
pending = parse(service, configs.nextElement());
}
//这里next返回的就是文件一行的内容,一般一行对应一个接口的实现类。
//一个接口放多行,就可以有多个接口实现类中。
nextName = pending.next();
return true;
}
}
configs变量,就对应service文件。 是个枚举, 就是说可以定义多个service文件。
pending 变量: 就对应configs中, service文件解析出来的一行有效内容,即一个实现类的全限定类名称。
parse方法就是简单,不是重点。这里就略过了。就是读取service文件中读取,一行就是一个nextName,然后遇到“#“就跳过“#”后面的内容。所以service文件可以用“#”作为注释。 直到遇到空行,解析结束。
LazyIterator类中的hasNext方法就分析完了。 使用classLoader.getResources方法加载service文件。我看了下getResources方法,并一定是加载classpath下的资源,得根据classLoader来解决。不过绝大多数情况下,都是classpath的资源。这里为了好理解,就理解成classpath下的资源。
接着分析LazyIterator#next方法。
public S next() {
//删除权限相关代码
return nextService();
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
//这个nextName前面分析过了
String cn = nextName;
nextName = null;
Class c = null;
try {
//加载类,且不初始化
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
//类型判断
S p = service.cast(c.newInstance());
//最后放到ServiceLoader实例变量Map中,缓存起来,下次直接使用
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
next方法就比较简单了,根据前面解析出来的nextName(接口实现类的全限定名称),用Class.forName创建对应的Class对象。
4.1.2.2 创建Connection
DriverManager.getConnection() 方法就是创建连接的地方,它通过循环已注册的数据库驱动程序,调用其connect方法,获取连接并返回。
private static Connection getConnection(String url, Properties info, Class caller) throws SQLException {
//registeredDrivers中就包含com.mysql.cj.jdbc.Driver实例
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
//调用connect方法创建连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
}catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println("skipping: " + aDriver.getClass().getName());
}
}
}
4.1.2.3 扩展
既然我们知道JDBC是这样创建数据库连接的,我们能不能再扩展一下呢?如果我们自己也创建一个 java.sql.Driver 文件,自定义实现类MySQLDriver,那么,在获取连接的前后就可以动态修改一些信息。
还是先在项目resources下创建文件,文件内容为自定义驱动类 com.jcc.java.spi.domyself.MySQLDriver
我们的 MySQLDriver 实现类,继承自MySQL中的 NonRegisteringDriver ,还要实现 java.sql.Driver 接口。这样,在调用connect方法的时候,就会调用到此类,但实际创建的过程还靠MySQL完成。
public class MySQLDriver extends NonRegisteringDriver implements Driver{
static {
try {
DriverManager.registerDriver(new MySQLDriver());
} catch (SQLException e) {
e.printStackTrace();
}
}
public MySQLDriver() throws SQLException {}
@Override
public Connection connect(String url, Properties info) throws SQLException {
System.out.println("准备创建数据库连接.url:"+url);
System.out.println("JDBC配置信息:"+info);
//重置配置
info.setProperty("user", "root");
Connection connection = super.connect(url, info);
System.out.println("数据库连接创建完成!"+connection.toString());
return connection;
}
}
这样的话,当我们获取数据库连接的时候,就会调用到这里。
--------------------输出结果---------------------
准备创建数据库连接.url:jdbc:mysql:///consult?serverTimezone=UTC
JDBC配置信息:{user=root, password=root}
数据库连接创建完成!com.mysql.cj.jdbc.ConnectionImpl@7cf10a6f
4.1.3 SpringBoot中的应用
Spring Boot提供了一种快速的方式来创建可用于生产环境的基于Spring的应用程序。它基于Spring框架,更倾向于约定而不是配置,并且旨在使您尽快启动并运行。
即便没有任何配置文件,SpringBoot的Web应用都能正常运行。这种神奇的事情,SpringBoot正是依靠自动配置来完成。
说到这,我们必须关注一个东西: SpringFactoriesLoader,自动配置就是依靠它来加载的。
4.1.3.1 配置文件
SpringFactoriesLoader 来负责加载配置。我们打开这个类,看到它加载文件的路径是: META-INF/spring.factories

笔者在项目中搜索这个文件,发现有4个Jar包都包含它:
- List itemspring-boot-2.1.9.RELEASE.jar
- spring-beans-5.1.10.RELEASE.jar
- spring-boot-autoconfigure-2.1.9.RELEASE.jar
- mybatis-spring-boot-autoconfigure-2.1.0.jar
那么它们里面都是些啥内容呢?其实就是一个个接口和类的映射。在这里笔者就不贴了,有兴趣的小伙伴自己去看看。
比如在SpringBoot启动的时候,要加载所有的 ApplicationContextInitializer ,那么就可以这样做:
SpringFactoriesLoader.loadFactoryNames(ApplicationContextInitializer.class, classLoader)
4.1.3.2 加载文件
loadSpringFactories 就负责读取所有的 spring.factories 文件内容。
private static Map> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
//获取所有spring.factories文件的路径
Enumeration urls = lassLoader.getResources("META-INF/spring.factories");
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
//加载文件并解析文件内容
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry entry : properties.entrySet()) {
String factoryClassName = ((String) entry.getKey()).trim();
for (String factoryName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryClassName, factoryName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
可以看到,它并没有采用JDK中的SPI机制来加载这些类,不过原理差不多。都是通过一个配置文件,加载并解析文件内容,然后通过反射创建实例。
4.1.3.3 参与其中
假如你希望参与到 SpringBoot 初始化的过程中,现在我们又多了一种方式。
我们也创建一个 spring.factories 文件,自定义一个初始化器。
org.springframework.context.ApplicationContextInitializer=com.youyouxunyin.config.context.MyContextInitializer
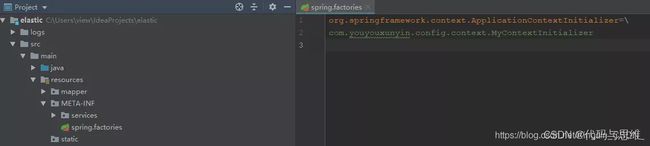
然后定义一个MyContextInitializer类
public class MyContextInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
System.out.println(configurableApplicationContext);
}
}
4.1.4 Dubbo中的应用
我们熟悉的Dubbo也不例外,它也是通过 SPI 机制加载所有的组件。同样的,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。
它的使用方式同样是在 META-INF/services 创建文件并写入相关类名。
4.1.5 sentinel中的应用
通过SPI机制将META-INFO/servcie下配置好的默认责任链构造这加载出来,然后调用其builder()方法进行构建调用链。
public final class SlotChainProvider {
private static volatile SlotChainBuilder slotChainBuilder = null;
/**
* The load and pick process is not thread-safe, but it's okay since the method should be only invoked
* via {@code lookProcessChain} in {@link com.alibaba.csp.sentinel.CtSph} under lock.
*
* @return new created slot chain
*/
public static ProcessorSlotChain newSlotChain() {
if (slotChainBuilder != null) {
return slotChainBuilder.build();
}
// Resolve the slot chain builder SPI.
slotChainBuilder = SpiLoader.of(SlotChainBuilder.class).loadFirstInstanceOrDefault();
if (slotChainBuilder == null) {
// Should not go through here.
RecordLog.warn("[SlotChainProvider] Wrong state when resolving slot chain builder, using default");
slotChainBuilder = new DefaultSlotChainBuilder();
} else {
RecordLog.info("[SlotChainProvider] Global slot chain builder resolved: {}",
slotChainBuilder.getClass().getCanonicalName());
}
return slotChainBuilder.build();
}
private SlotChainProvider() {}
}
SpiLoader.of()
public static SpiLoader of(Class service) {
AssertUtil.notNull(service, "SPI class cannot be null");
AssertUtil.isTrue(service.isInterface() || Modifier.isAbstract(service.getModifiers()),
"SPI class[" + service.getName() + "] must be interface or abstract class");
String className = service.getName();
SpiLoader spiLoader = SPI_LOADER_MAP.get(className);
if (spiLoader == null) {
synchronized (SpiLoader.class) {
spiLoader = SPI_LOADER_MAP.get(className);
if (spiLoader == null) {
SPI_LOADER_MAP.putIfAbsent(className, new SpiLoader<>(service));
spiLoader = SPI_LOADER_MAP.get(className);
}
}
}
return spiLoader;
}
@Spi(isDefault = true)
public class DefaultSlotChainBuilder implements SlotChainBuilder {
@Override
public ProcessorSlotChain build() {
ProcessorSlotChain chain = new DefaultProcessorSlotChain();
List sortedSlotList = SpiLoader.of(ProcessorSlot.class).loadInstanceListSorted();
for (ProcessorSlot slot : sortedSlotList) {
if (!(slot instanceof AbstractLinkedProcessorSlot)) {
RecordLog.warn("The ProcessorSlot(" + slot.getClass().getCanonicalName() + ") is not an instance of AbstractLinkedProcessorSlot, can't be added into ProcessorSlotChain");
continue;
}
chain.addLast((AbstractLinkedProcessorSlot) slot);
}
return chain;
}
}
责任链同样是由spi机制加载出来的,上面的加载只会在第一次使用的时候加载,然后缓存到内从后,以后直接取即可。
至此,SPI机制的实现原理就分析完了。 虽然SPI我们日常开发中用的很少,但是至少了解了解还是有必要的。 例如: 一些框架实现中一般都会用到SPI机制。
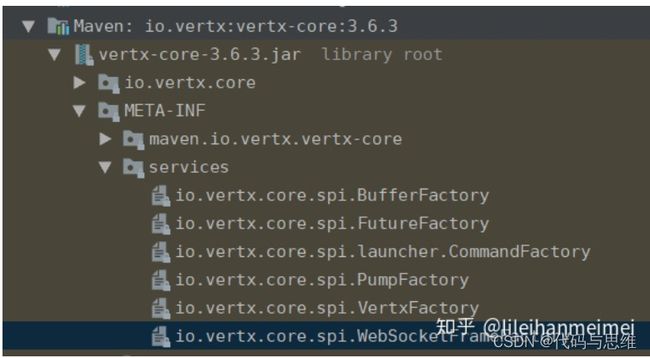
vert.x内部也是大量使用SPI
4.2 APT注解处理器
4.2.1 基础知识
注解的保留时间分为三种:
- SOURCE——只在源代码中保留,编译器将代码编译成字节码文件后就会丢掉
- CLASS——保留到字节码文件中,但Java虚拟机将class文件加载到内存是不一定在内存中保留
- RUNTIME——一直保留到运行时
通常我们使用后两种,因为SOURCE主要起到标记方便理解的作用,无法对代码逻辑提供有效的信息。
| 时间 | 解析 | 性能影响 | |
|---|---|---|---|
| RUNTIME | 运行时 | 反射 | 有 |
| CLASS | 编译期 | APT+JavaPoet | 无 |
如上图,对比两种解析方式:
- 运行时注解比较简单易懂,可以运用反射技术在程序运行时获取指定的注解信息,因为用到反射,所以性能会收到一定影响。
- 编译期注解可以使用APT(Annotation Processing Tool)技术,在编译期扫描和解析注解,并结合JavaPoet技术生成新的java文件,是一种更优雅的解析注解的方式,不会对程序性能产生太大影响。
下面以BindView为例,介绍两种方式的不同使用方法。
4.2.2 运行时注解
运行时注解主要通过反射进行解析,代码运行过程中,通过反射我们可以知道哪些属性、方法使用了该注解,并且可以获取注解中的参数,做一些我们想做的事情。
首先,新建一个注解
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface BindViewTo {
int value() default -1; //需要绑定的view id
}
然后,新建一个注解解析工具类AnnotationTools,和一般的反射用法并无不同:
public class AnnotationTools {
public static void bindAllAnnotationView(Activity activity) {
//获得成员变量
Field[] fields = activity.getClass().getDeclaredFields();
for (Field field : fields) {
try {
if (field.getAnnotations() != null) {
//判断BindViewTo注解是否存在
if (field.isAnnotationPresent(BindViewTo.class)) {
//获取访问权限
field.setAccessible(true);
BindViewTo getViewTo = field.getAnnotation(BindViewTo.class);
//获取View id
int id = getViewTo.value();
//通过id获取View,并赋值该成员变量
field.set(activity, activity.findViewById(id));
}
}
} catch (Exception e) {
}
}
}
}
在Activity中调用
public class MainActivity extends AppCompatActivity {
@BindViewTo(R.id.text)
private TextView mText;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//调用注解绑定,当前Activity中所有使用@BindViewTo注解的控件将自动绑定
AnnotationTools.bindAllAnnotationView(this);
//测试绑定是否成功
mText.setTextColor(Color.RED);
}
}
测试结果毫无意外,字体变成了红色,说明绑定成功。
4.2.3 编译期注解(APT+JavaPoet)
编译期注解解析需要用到APT(Annotation Processing Tool)技术,APT是javac中提供的一种编译时扫描和处理注解的工具,它会对源代码文件进行检查,并找出其中的注解,然后根据用户自定义的注解处理方法进行额外的处理。APT工具不仅能解析注解,还能结合JavaPoet技术根据注解生成新的的Java源文件,最终将生成的新文件与原来的Java文件共同编译。
APT实现流程如下:
- 创建一个java lib作为注解解析库——如apt_processor
- 在创建一个java lib作为注解声明库——如apt_annotation
- 搭建两个lib和主项目的依赖关系
- 实现AbstractProcessor
- 编译和调用
整个流程是固定的,我们的主要工作是继承AbstractProcessor,并且实现其中四个方法。下面一步一步详细介绍:
4.2.3.1创建解析库apt_processor
apply plugin: 'java-library'
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.squareup:javapoet:1.9.0' // square开源的 Java 代码生成框架
compile 'com.google.auto.service:auto-service:1.0-rc2' //Google开源的用于注册自定义注解处理器的工具
implementation project(':apt_annotation') //依赖自定义注解声明库
}
sourceCompatibility = "7"
targetCompatibility = "7"
4.2.3.2 创建注解库apt_annotation
声明一个注解BindViewTo,注意@Retention不再是RUNTIME,而是CLASS。
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.CLASS)
public @interface BindViewTo {
int value() default -1;
}
4.2.3.3 搭建主项目依赖关系
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation project(':apt_annotation') //依赖自定义注解声明库
annotationProcessor project(':apt_processor') //依赖自定义注解解析库(仅编译期)
}
这里需要解释一下,因为注解解析库只在程序编译期有用,没必要打包进APK。所以依赖解析库使用的关键字是annotationProcessor,这是google为gradle插件添加的特性,表示只在编译期依赖,不会打包进最终APK。这也是为什么前面要把注解声明和注解解析拆分成两个库的原因。因为注解声明是一定要编译到最终APK的,而注解解析不需要。
4.2.3.4 实现AbstractProcessor
这是最复杂的一步,也是完成我们期望工作的重点。首先,我们在apt_processor中创建一个继承自AbstractProcessor的子类,重载其中四个方法:
- init()——此处初始化一个工具类
- getSupportedSourceVersion()——声明支持的Java版本,一般为最新版本
- getSupportedAnnotationTypes()——声明支持的注解列表
- process()——编译器回调方法,apt核心实现方法
具体代码如下:
//@SupportedSourceVersion(SourceVersion.RELEASE_7)
//@SupportedAnnotationTypes("com.xibeixue.apt_annotation.BindViewTo")
@AutoService(Processor.class)
public class BindViewProcessor extends AbstractProcessor {
private Elements mElementUtils;
private HashMap mCreatorMap = new HashMap<>();
/**
* init方法一般用于初始化一些用到的工具类,主要有
* processingEnvironment.getElementUtils(); 处理Element的工具类,用于获取程序的元素,例如包、类、方法。
* processingEnvironment.getTypeUtils(); 处理TypeMirror的工具类,用于取类信息
* processingEnvironment.getFiler(); 文件工具
* processingEnvironment.getMessager(); 错误处理工具
*/
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
mElementUtils = processingEnv.getElementUtils();
}
/**
* 获取Java版本,一般用最新版本
* 也可以使用注解方式:@SupportedSourceVersion(SourceVersion.RELEASE_7)
*/
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
/**
* 获取目标注解列表
* 也可以使用注解方式:@SupportedAnnotationTypes("com.xibeixue.apt_annotation.BindViewTo")
*/
@Override
public Set getSupportedAnnotationTypes() {
HashSet supportTypes = new LinkedHashSet<>();
supportTypes.add(BindViewTo.class.getCanonicalName());
return supportTypes;
}
/**
* 编译期回调方法,apt核心实现方法
* 包含所有使用目标注解的元素(Element)
*/
@Override
public boolean process(Set set, RoundEnvironment roundEnvironment) {
//扫描整个工程, 找出所有使用BindViewTo注解的元素
Set elements = roundEnvironment.getElementsAnnotatedWith(BindViewTo.class);
//遍历元素, 为每一个类元素创建一个Creator
for (Element element : elements) {
//BindViewTo限定了只能属性使用, 这里强转为变量元素VariableElement
VariableElement variableElement = (VariableElement) element;
//获取封装属性元素的类元素TypeElement
TypeElement classElement = (TypeElement) variableElement.getEnclosingElement();
//获取简单类名
String fullClassName = classElement.getQualifiedName().toString();
BinderClassCreator creator = mCreatorMap.get(fullClassName);
//如果不存在, 则创建一个对应的Creator
if (creator == null) {
creator = new BinderClassCreator(mElementUtils.getPackageOf(classElement), classElement);
mCreatorMap.put(fullClassName, creator);
}
//将需要绑定的变量和对应的view id存储到对应的Creator中
BindViewTo bindAnnotation = variableElement.getAnnotation(BindViewTo.class);
int id = bindAnnotation.value();
creator.putElement(id, variableElement);
}
//每一个类将生成一个新的java文件,其中包含绑定代码
for (String key : mCreatorMap.keySet()) {
BinderClassCreator binderClassCreator = mCreatorMap.get(key);
//通过javapoet构建生成Java类文件
JavaFile javaFile = JavaFile.builder(binderClassCreator.getPackageName(),
binderClassCreator.generateJavaCode()).build();
try {
javaFile.writeTo(processingEnv.getFiler());
} catch (IOException e) {
e.printStackTrace();
}
}
return false;
}
}
其中,BinderClassCreator是代码生成相关方法,具体代码如下:
public class BinderClassCreator {
public static final String ParamName = "rootView";
private TypeElement mTypeElement;
private String mPackageName;
private String mBinderClassName;
private Map mVariableElements = new HashMap<>();
/**
* @param packageElement 包元素
* @param classElement 类元素
*/
public BinderClassCreator(PackageElement packageElement, TypeElement classElement) {
this.mTypeElement = classElement;
mPackageName = packageElement.getQualifiedName().toString();
mBinderClassName = classElement.getSimpleName().toString() + "_ViewBinding";
}
public void putElement(int id, VariableElement variableElement) {
mVariableElements.put(id, variableElement);
}
public TypeSpec generateJavaCode() {
return TypeSpec.classBuilder(mBinderClassName)
//public 修饰类
.addModifiers(Modifier.PUBLIC)
//添加类的方法
.addMethod(generateMethod())
//构建Java类
.build();
}
private MethodSpec generateMethod() {
//获取全类名
ClassName className = ClassName.bestGuess(mTypeElement.getQualifiedName().toString());
//构建方法--方法名
return MethodSpec.methodBuilder("bindView")
//public方法
.addModifiers(Modifier.PUBLIC)
//返回void
.returns(void.class)
//方法传参(参数全类名,参数名)
.addParameter(className, ParamName)
//方法代码
.addCode(generateMethodCode())
.build();
}
private String generateMethodCode() {
StringBuilder code = new StringBuilder();
for (int id : mVariableElements.keySet()) {
VariableElement variableElement = mVariableElements.get(id);
//变量名称
String name = variableElement.getSimpleName().toString();
//变量类型
String type = variableElement.asType().toString();
//rootView.name = (type)view.findViewById(id), 注意原类中变量声明不能为private,否则这里是获取不到的
String findViewCode = ParamName + "." + name + "=(" + type + ")" + ParamName + ".findViewById(" + id + ");\n";
code.append(findViewCode);
}
return code.toString();
}
public String getPackageName() {
return mPackageName;
}
}
4.2.3.5 编译和调用
在MainActivity中调用,这里需要强调的是待绑定变量不能声明为private,原因在上面代码注释中已经解释了。
public class MainActivity extends AppCompatActivity {
@BindViewTo(R.id.text)
public TextView mText;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);//这里的MainActivity需要先编译生成后才能调用
new MainActivity_ViewBinding().bindView(this);
//测试绑定是否成功
mText.setTextColor(Color.RED);
}
}
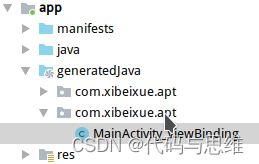
此时,build或rebuild工程(需要先注掉MainActivity的调用),会看到在generatedJava文件夹下生成了新的Java文件。
上面的调用方式需要先编译一次才能使用,当有多个Activity时比较繁琐,而且无法做到统一。
我们也可以选择另一种更简便的方法,即反射调用。新建工具类如下:
public class MyButterKnife {
public static void bind(Activity activity) {
Class clazz = activity.getClass();
try {
Class bindViewClass = Class.forName(clazz.getName() + "_ViewBinding");
Method method = bindViewClass.getMethod("bindView", activity.getClass());
method.invoke(bindViewClass.newInstance(), activity);
} catch (Exception e) {
e.printStackTrace();
}
}
}
调用方式改为:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//通过反射调用
MyButterKnife.bind(this);
//测试绑定是否成功
mText.setTextColor(Color.RED);
}
此方式虽然也会稍微影响性能,但依然比直接使用运行时注解高效得多。
4.2.4 APT注解处理器总结
说到底,APT是一个编译器工具,是一个非常好的从源码到编译期的过渡解析工具。虽然结合JavaPoet技术被各大框架使用,但是依然存在固有的缺陷,比如变量不能私有,依然要采用反射调用等,普通开发者可斟酌使用。
个人认为APT有如下优点:
- 配置方式,替换文件配置方式,改为代码内配置,提高程序内聚性
- 代码精简,一劳永逸,省去繁琐复杂的格式化代码,适合团队内推广
以上优点同时也是缺点,因为很多代码都在后台生成,会对新同学造成理解困难,影响其对整体架构的理解,增加学习成本。
近期研究热修复和APT,发现从我们写完成代码,到代码真正执行,期间还真是有大把的“空子”可以钻啊,借图mark一下。
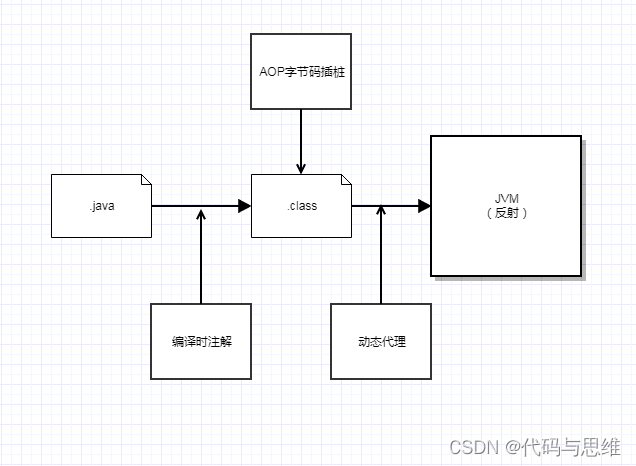
4.3 javac源码分析
4.3.1 javac概述
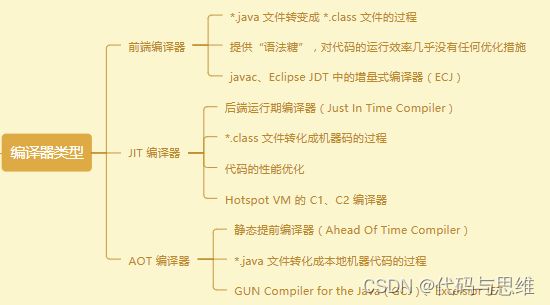
我们都知道 *.java 文件要首先被编译成 *.class 文件才能被 JVM 认识,这部分的工作主要由 Javac 来完成,类似于 Javac 这样的我们称之为前端编译器;
但是 *.class 文件也不是机器语言,怎么才能让机器识别呢?就需要 JVM 将 *.class 文件编译成机器码,这部分工作由JIT 编译器完成;
除了这两种编译器,还有一种直接把 *.java 文件编译成本地机器码的编译器,我们称之AOT 编译器。
4.3.2 javac 的编译过程
首先,我们先导一份 javac 的源码(基于 openjdk8)出来,下载地址:https://hg.openjdk.java.net/jdk8/jdk8/langtools/archive/tip.tar.gz,然后将 JDK_SRC_HOME/langtools/src/share/classes/com/sun 目录下的源文件全部复制到工程的源码目录中,生成的 目录如下: 
我们执行 com.sun.tools.javac.Main 的 main 方法,就和我们在命令窗口中使用 javac 命令一样:
从 Sun Javac 的代码来看,编译过程大致可以分为三个步骤:
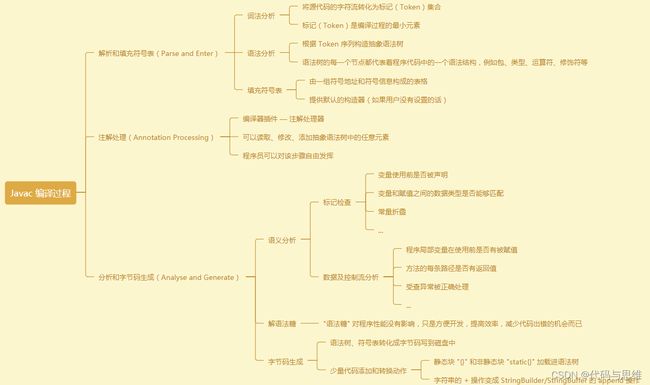
- 解析和填充符号表过程
- 插入式注解处理器的注解处理过程
- 分析和字节码生成过程
这三个步骤所做的工作内容大致如下:
这三个步骤之间的关系和交互顺序如下图所示,可以看到如果注解处理器在处理注解期间对语法树进行了修改,编译器将回到解析和填充符号表的过程进行重新处理,直到注解处理器没有再对语法树进行修改为止。

Javac 编译的入口是 com.sun.tools.javac.main.JavaCompiler 类,上述三个步骤的代码都集中在这个类的 compile() 和 compile2() 中:
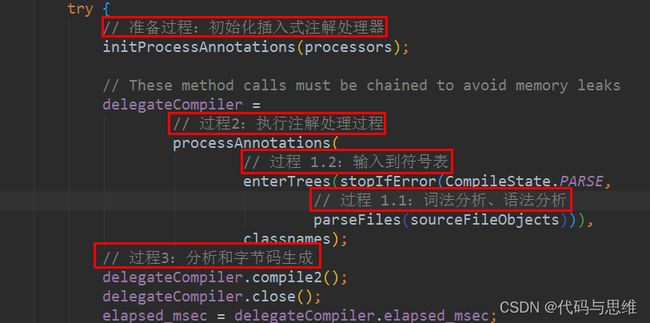
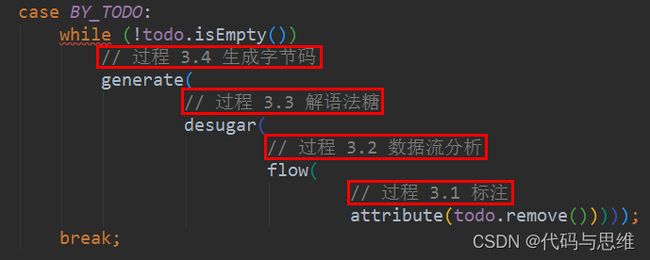
4.3.3 javac编译器编译程序的步骤
词法分析
首先是读取源代码,找出这些字节中哪些是我们定义的语法关键词,如Java中的if、else、for等关键词
语法分析的结果:从源代码中找出一些规范化的token流
注:token是一种认证机制
语法分析
检查关键词组合在一起是不是Java语言规范,如if后面是不是紧跟着一个布尔表达式。
语法分析的结果:形成一个符合Java语言规范的抽象语法树
语义分析
把一些难懂的、复杂的语法转化为更加简单的语法
语义分析的结果:完成复杂语法到简单语法的简化,如将foreach语句转化成for循环结果,还有注解等。最后形成一个注解过后的抽象语法树,这颗语法树更接近目标语言的语法规则
生成字节码
通过字节码生成器生成字节码,根据经过注解的抽象语法树生成字节码,也就是将一个数据结构转化成另一个数据结构
代码生成器的结果:生成符合Java虚拟机规范的字节码
注:抽象语法树
在计算机科学中,抽象语法树是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构