事务的历史与SSI——PostgreSQL数据库技术峰会成都站分享
前言
PostgreSQL数据库技术峰会成都站
近期(2023年6月17日),由中国开源软件推进联盟PG分会发起的“PostgreSQL数据库技术峰会成都站”圆满举行。我也有幸作为演讲嘉宾参加了此次峰会,收获很多。
(分会回顾和所有ppt下载:PPT下载来了 | PostgreSQL技术峰会成都站回顾)
我的分享
我的技术分享主题为:数据库历史与SSI。
我发现国内有很多技术博客对事物的描述不太准确,会对初学者造成很多疑惑,还有很多小伙伴对事物历史和pg中的SSI不是很熟悉。这次我从wiki、SQL官方标准和各种论文中收集和汇总了事务的准确含义、事务的历史和SSI的理论基础。分享内容的主要思路是从事务的历史推进到一些92标准中不存在的异象,再到消灭这些异象可以怎么做,再循序渐进到pg库的SSI是怎么做的。
全篇分享分为4个部分:事务的基础、事务的历史、SSI理论知识、PostgresSQL中的SSI。
事务的基础
在了解事务历史和SSI之前,我们先回顾一下,复习复习一些基本的事务知识。整个章节都会围绕事务来进行讨论,事务的基本知识会引出事务历史中存在的问题。
什么是事务?
事务的原本含义:事务=>transaction=>交易。交易是事务原本的含义,而我们数据库中的事务就是从交易这个词汇而来。
数据库中的事务:事务是关系型数据库的基本工作单元。比如
从A表删除数据,从B表插入数据,我们可以把他们这两个动作包装成一个事务,他俩必须都完成。但是也有可能因为某些意外因素,事务执行到一半失败或者取消了,此时只能整个事务中的所有操作全部回退,回到事务前的状态,A也不执行删除,B也不执行插入
ACID
ACID是数据库事务的重要特性。它决定了交易事务是否是可靠的、可信任的。

原子性**:事务中的各个操作要么全部完成,要么全部取消。
就像化学中的原子一样不可分割、不可分裂。如果一个事务执行到一半有问题执行失败了,执行不下去了,那么这个事务必须全部回退。
一致性:事务完成时,所有数据都保持一致状态。
这个定义其实比较模糊。事务一般会操作数据,数据库中数据的状态会被更新,因为事务操作,数据会从一个状态到另一个状态,这个状态必须是合理合法的,数据逻辑必须和真实世界的逻辑一致。这里可能比较抽象,打个比方:比如说甲有100元,乙有200元,他们合起来的钱是300元,这时乙向甲转账100元,那么甲就有200元,乙有100元,他们合起来的钱仍然是300元。重点:这个虚拟世界的数据变化应该与真实世界的逻辑保持一致。
隔离性:多个事务并发执行的结果必须和分开单独执行的结果一致。
比如2个事务,一个接着一个的串行执行,必须和并行执行结果一致。(这个是wiki的官方理解,也是SQL标准中的定义,请记住这个定义,这个是本篇的重点)
持久性:事务处理结束后,对数据的修改就是永久的。
如果更新后数据放入内存中,关机就没了,那么他理应放入磁盘里,那么放入磁盘是安全的吗?如果磁盘损坏了呢?我们可以有高可用架构写多份数据,再延伸一下还可以有地域级别的容灾,那如果我们再杠一下,多个地域都挂了呢?如果从架构上来介绍,这个问题好像没有答案。但是从用户的角度来看,其实比较容易理解。比如用户在存钱的时候,他把钞票放进去了,那么账户上应该显示他存入的钱的数字,这个数字对于用户来说是永久的,用户认为即使天塌下来,他的账户里都应该有这个数字,这是持久性的含义。
ANSI-SQL92标准

1992年美国国家标准ANSI SQL-92标准中定义了4种隔离级别和3种异常现象。
虽然现在的数据库行业基本都参照ISO国际标准了。

但这个92年的美国标准对数据库行业影响非常大,相信很多玩数据库小伙伴的都知道4种隔离级别。
92标准的隔离级别
ANSI SQL-92标准定义了4种隔离级别
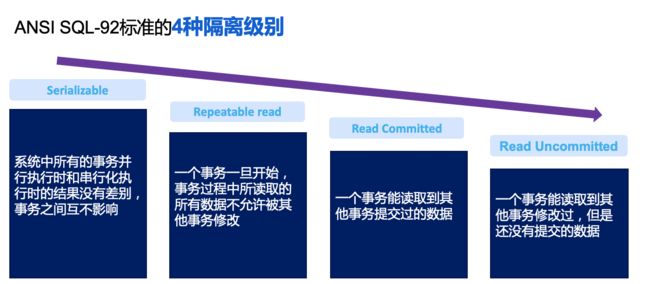
事务的隔离级别从高到低。注意看可串行化:系统中所有的事务并行执行时和串行化执行时的结果没有差别,事务之间互不影响
。这个是不是跟ACID的隔离性定义有点像?
4种隔离级别都可以满足事务全做或全部不做,只是在隔离性上有不同的定义,所有的隔离级别都可有原子性、一致性、持久性,但不同的隔离级别有不同的隔离性,从定义上看,其实只有可串行化是完全满足ACID的。
92标准的异常现象
92标准中定义了3种异常现象,网上有很多相关的定义,其实很多说的都不太准确,我们这里直接从92标准文档中摘取出来3种异常现象的定义
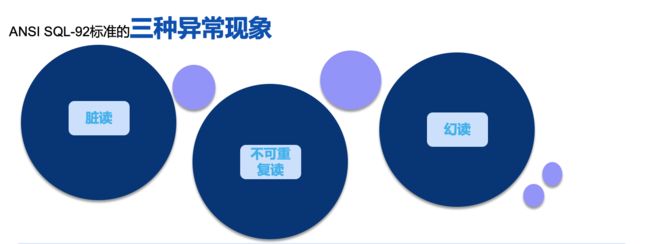
脏读:事务T1更新了一行,事务T2可以在事务T1提交前读到这个行。如果T1执行了回退,T2会读到一个从未提交的行。
*脏读有个明显的问题,用户可能不知道钱是不是到账了,在事务没有完成前用户就可以查到账户里有钱已经转入了,但是某些原因失败了导致事务回退,钱又没了,这对用户来说是难以理解的。
不可重复读:事务T1读取了一行,事务T2更新或删除了这行并提交了。如果T1再次读取这行,它会发现行被更改或删除了。
幻读:事务T1通过某些条件读取到了N行,事务T2执行sql生成了行并满足了这个条件,T1重复读取时发现了不一致的行结果。
*不可重复读和幻读的区别在于一是其他事务的更新或删除导致同一事务内读数不一致,一个是其他事务的插入导致同一事物内读数不一致
92标准与pg
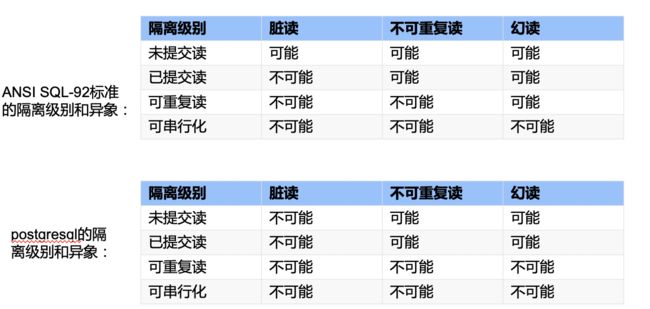
在92标准的隔离级别和异常现象是呈阶梯式的,除了可串行化没有异常现象外,每个隔离级别都有阶梯式的增加了异常现象。然后我们看下面这个表格,这是pgsql中的隔离级别和异常现象,他跟92标准是不一样的。
为什么PostgreSQL数据库隔离级别与“92标准”不一致的情况呢?
- 为什么未提交读与“92标准”不一致?未提交读实在是太奇怪了,在关系型数据库中基本想不到使用未提交读的场景。它严重违反了事务的隔离性。PostgreSQL将“未提交读”视为“已提交读”
- 为什么可重复读与“92标准”不一致?PostgreSQL通过快照实现MVCC多版本并发控制, PostgreSQL中的可重复读级别实际上是快照隔离级别,这个隔离级别实际上没有幻读这个异常现象
- 虽然“92标准”影响深远,但是还是有许多数据库没有全部实现它。
- ANSI SQL-92标准定义模糊。“92标准”在数据库行业很有代表性,“它很好,但不够好”。
事务的历史
事务的历史
理解 “它很好,但不够好”,需要把回顾一下事务的历史,时间往回推40年。

注意92标准提出的时间和“92批判”的时间。虽然92标准很“烂”,但是仍然对数据库行业影响深远。随后在很多串行化理论得到证实后,PostgresSQL数据库第一个在商业数据库中实现了SSI。
对92标准的批判
在92标准出来不久,一些微软工程师和学者对92标准做了批评,并在提出了更多的隔离级别和异常现象。
之前92标准中定义了4个隔离级别和3个异常现象,在“对92的批评”中有6种隔离级别和8种异常现象。
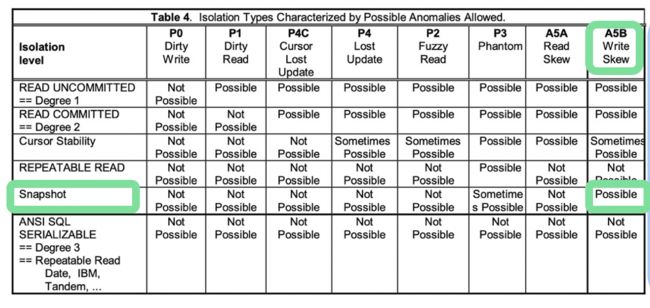
- 更多的隔离级别和异常现象出现, 它们没有在ANSI SQL-92中定义
- 快照隔离在可重复读和可串行化间。这也是为什么pgsql的可重复读跟可串行化这么像的原因之一
- 写偏序异常提出。它会在快照隔离级别发生。
热门数据库的隔离级别
- mysql在serializability隔离级别下,读对数据加读共享锁,读会阻塞写
- oracle其实也可以设置serializability隔离级别,并号称是支持可串行化的,但是它不是真正的可串行化,只是snapshot isolation
- PostgreSQL支持serializability,它在snapshot isolation基础上实现可串行化,全称为可串行化快照隔离Serializable Snapshot Isolation (SSI) ,读写不会相互阻塞
能看出来3者的差别,只有pgsql的可串行化是有干货的。
为什么oracle欺骗了我们?
oracle欺骗了我们什么呢?他把快照隔离这个隔离级别当成可串行化隔离级别糊弄我们。
为什么会发生这种情况呢?
如果我们把snapshot isolation加到ANSI SQL-92标准中

- “92标准”的异象定义较少,也没有定义快照隔离,以92标准来看,snapshot isolation看上去跟serializable差不多
- 大部分关系型数据库都以“92标准”为标准,包括oracle。但是随后更好的标准出现后,他们没有做出改变
为什么弱隔离级别在学术上有问题,实际上没出现严重问题 ?
-
非可串行化隔离级别的异常现象,一般都需要在高并发情况下才会发生,低并发数据库不太会出现问题;
-
当异常现象真的发生的时候,有些应用可能没发现异常现象或检查到异常但对他们不重要;
-
有可能数据异常了,但应用只是返回报错,并进入数据异常处理程序;
-
成本过高。不仅是数据库串行化隔离级别开发成本高,应用对可串行化也需要适应成本。光是理解这部分复杂的理论就不是一件容易的事;
-
高级别的隔离会丢失一些性能。大量的改造工作可能是吃力不讨好的,应用需要在“高并发”和“无异常现象”间做抉择;
-
业务基于机制开发,而不是规则开发。业务多少有点适应弱隔离级别的异常现象,特别是RC 。
可串行化有什么意义?
如果弱隔离在真实世界都好像没问题,那么可串行化还有什么意义呢?其实是有的
- 虽然应用适应了弱隔离级别,但是不代表他们真的理解了
- 使用可串行化,应用可以极大的减少对数据异常的担忧
- 除了可串行化外,其他的隔离级别都有各自的异常现象,他们也不完全满足ACID的隔离性
- 可串行化可以消灭异常现象这个“蛀虫”,完全保证数据的安全性
- 可串行化在理论上已经证明可以实现
- 一些可串行的实现确实极大的降低了并发性,但是还有其他的可串行化实现,对并发性影响很小。比如说,可串行化快照隔离SSI可串行化的实现
SSI理论知识
说了那么多事务的基本知识和事务的历史,终于来到了SSI的概念。但在了解SSI之前,还得先了解2个概念:可串行化、快照隔离
可串行化
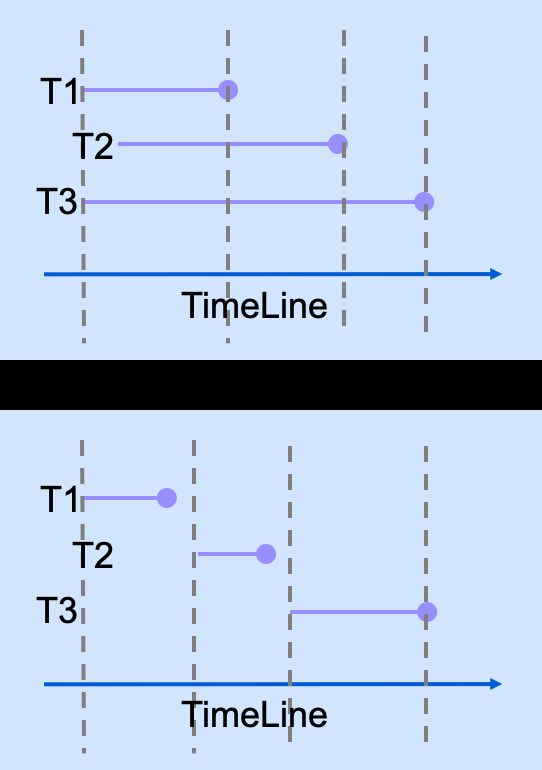
可串行化的含义
如果每个事务本身是正确的,即满足某些完整性条件,那么包括这些事务的任何串行执行的时间表是正确的(其事务仍然满足其条件):“串行”意味着事务在时间上不重叠,并且不能相互干扰,即彼此之间存在完全隔离。
可串行化的实现
事务发展早期,可串行化(serializable)通过严格两阶段锁(SS2PL)实现,读写相互阻塞,直到事务结束。消除了异常现象但SS2PL丢失了高性能。
除了SS2PL实现可串行化,还有其他方式,比如可串行化快照隔离(SSI)。
可串行化的意义
为了保证没有异常,可串行化会丢失一些并发性(不同实现方式有所不同),但可以真正保证数据的ACID隔离性。也就是说没有实现串行化的数据库,其实没有完全支持ACID特性。
可串行化在理论上已经证明可以实现,但是真实的数据库世界有点”不正常“。实际上,可串行化是事务隔离级别中最高级的,也是学者和业界大佬强力推荐的隔离级别,不过绝大部分数据库在RC或快照隔离级别上运行。
快照隔离
快照隔离的定义
在快照隔离下执行的事务是在事务开始时拍摄的数据库快照上操作的。当事务结束时,只有当事务更新的值自快照拍摄以来没有外部更改时,它才会成功提交。
快照隔离级别顾名思义就是就是使用了快照,这广泛用于实现MVCC,使多版本并发机制支持用户并发执行事务。
快照隔离的出现
ANSI SQL92并未定义快照隔离snapshot isolation(SI),这个隔离级别随着数据库行业发展才出现。1992年 ANSI SQL92标准基于数据库的锁而定义,所以没有快照隔离级别这个定义。直到1995年《批判》的出现才被提出。
SSI
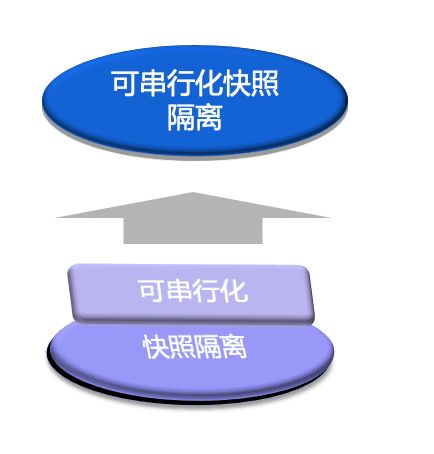
可串行化快照隔离SSI
由于快照隔离的广泛应用,而可串行化是学术上数据库需要达到的隔离级别目标。可串行化快照隔离Serializable Snapshot Isolation (SSI) 顾名思义,在快照隔离的基础上实现可串行化。
为什么有SSI?
由于ANSI92标准的模糊性,虽然没有定义快照隔离,但许多数据库实际上就是使用的快照隔离。而快照隔离同样存在一些异常现象(包括写偏序),SSI的出现就是为了解决这些异常现象。
SSI相对于S2PL的优势
传统的可串行化通过S2PL实现,在S2PL下写操作会阻塞其他事务读写,虽然可以实现可串行化,不会有写偏序异常等问题,但会产生很多锁冲突,降低并发性能。而通过快照实现的MVCC读写互不阻塞,只有写写冲突。在此基础上实现的SSI对并发性的影响相比传统S2PL要小很多。
PG实现SSI
SSI在pg9.1开始实现SSI,是第一个实现SSI的商业数据库。
3种依赖关系

**读写依赖:**事务T1写数据项的一个版本,事务T2读这个版本,意味着T1先于T2
**写写依赖:**事务T1写数据项的一个版本,事务T2使用一个新版本替换了这个版本,意味着T1先于T2
**读写反依赖:**事务T1写数据项的一个版本,事务T2读这个版本之前的版本,意味着T2先于T1
写偏序的理论
由于某些冲突构成环,会出现串行化异常。也就是说,有些并行执行的事务,从理论上就是不可串行化的。其中比较容易理解的一个就是写偏序(write skew)。
写偏序只发生在rw模型,ww、wr均不会发生写偏序,并且事务必须在并发条件下才会出现。
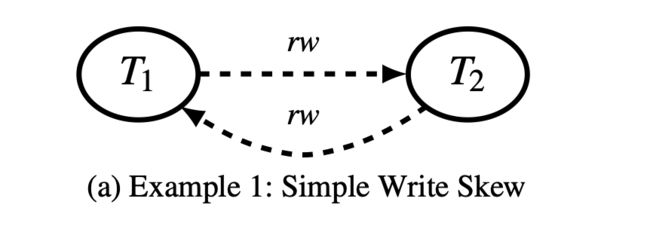
简单写偏序:事务T1读写反依赖T2,T2又读写反依赖T1。这两个事务的并发执行是不可串行化的。
写偏向的现实问题
有许多现实案例可以出现写偏序异常,我们用一个经典的黑白球问题来理解写偏序

袋中有4个球,2个白球和2个黑球。此时有两个事务,P和Q。P将所有黑球改成白球,Q将所有白球改成黑球。此时可以有两个串行执行,
但是,快照隔离允许另一种结果:
事务 P 拿出2个黑球
事务 Q 拿出2个白球
事务 P 将手中所有黑球改成白球,放回袋中
事务 Q 将手中所有白球改成黑球,放回袋中
此时袋中还是2个黑球和2个白球。这在任何一个串行执行中都是不可能的。
但这在快照隔离中是有效:每个事务都维护数据库的一致视图,并且其写集不与任何并发事务的写集重叠,如此白球黑球发生交换。
我们还可以把问题具象化、更实际。举一个比较粗糙的例子:比如我手里有几个银行卡,一半冻结,一半解冻状态。我在一个终端上执行了所有卡冻结,然后在另一个终端上立即执行所有卡解冻。这个时候从目的上讲,我的卡应该是全部解冻的,但是出现了一个奇怪的现象,以前冻结的卡解冻了,以前解冻的卡冻结了。作为一个客户,我会感到困惑。
黑白球问题说明:快照隔离执行结果与串行化执行结果不一致,快照隔离下发生写偏序异常,数据结果与预期不一致。
PostgreSQL中的SSI
pg是怎么处理SSI的
其实很简单就是把构成”危险结构“的某个支点事务取消。
我们先把隔离级别都设置为可串行化,表中有一些白球和一些黑球。
| T1 | T2 |
|---|---|
| set default_transaction_isolation = ‘serializable’; | set default_transaction_isolation = ‘serializable’; |
| begin; update dots set color = ‘black’ where color = ‘white’; | |
| begin; update dots set color = ‘white’ where color = ‘black’; | |
| commit; | |
| commit; | |
ERROR: could not serialize access due to read/write dependencies among transactions DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt. HINT: The transaction might succeed if retried. |
事务1把所有白色改成黑色,事务2把所有黑色改成白色,然后2个事务提交。第一个提交的事务成功了,第二个提交的事务失败了,这里是报错,说的是:因为读写依赖不可串行化,把当前事务作为支点取消了,如果重新尝试事务,可能会成功。
这里当然会成功,另一个事务已经完成,一个事务不会构成依赖关系,不会构成环。在其他隔离级别,比如可重复读、已提交读,这个两个事务这样执行不会有任何报错,正常执行,但是数据执行结果跟SSI的执行结果不同。
PostgreSQL对SSI实现的优化
postgresql在快照隔离级别基础上实现了可串行化SSI,并对其做了很多优化,以提高高隔离级别下的并发性,pgsql对ssi的优化主要有3点:
安全快照:不会引起环形结构的只读事务,不必检测冲突,可减少检查负担和内存负担
延迟事务:延迟事务可重新尝试。在检查到”危险结构“后,延迟事务会被取消,然后再次尝试执行。延迟事务需要显示声明
检测粒度升级:多个细粒度的锁可合成粗粒度的锁减少内存开销
优化结果:
优化结果-压测性能对比:
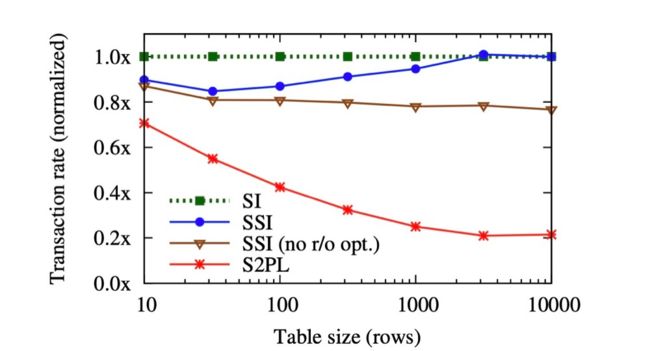
绿色线是快照隔离基准线,蓝色线pgsql的SSI性能跟快照隔离已经很接近了。而褐色的线是SSI在没有只读事务,全是数据更改事务的场景,能看出只读事务优化对性能提升也很大。实际上一般业务系统,只读事务都会比更改事务多。红色的线是严格两阶段提交实现的可串行化,性能惨不忍睹。
下面这个表格,是并发压力和事务失败率,因为有些事务需要取消才能打破环,所以可串行化肯定比弱隔离取消的事务更多,这个表格也能看出pgsql的SSI的并发度和事务成功率远高于严格两阶段提交。
优化结果-请求量和失败率:

总结
-
可串行化能简化系统开发的问题,开发人员不需要管并发下事务的异常现象,特别是如今更多的高并发系统下。
-
PostgreSQL的可串行化显然比严格两阶段提交模式更好。不仅性能更好,而且中止事务的概率也更低。
-
PostgreSQL是第一个实现SSI的商业数据库,而很多传统关系型数据库根本不支持可串行化,pgsql数据库往前走了一大步。
-
PostgreSQL不仅实现了SSI,还在此基础上做了很多优化,比如只读事务和内存优化,并且效果显著