Caretta 利用 eBPF 实现 Kubernetes 应用网络拓扑
介绍
Caretta 是一种轻量级的独立工具,快速展示集群中运行的服务可视化网络图。
Caretta 利用 eBPF 有效地展示 K8s 集群中的服务网络交互图,并利用 Grafana 查询和可视化收集的数据。科学家们早就知道,海龟和许多动物一样,通过感应磁场中看不见的线在海上航行,类似于水手使用纬度和经度的方式。
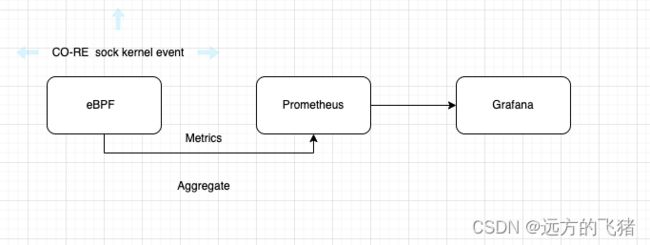
说明
内核允许使用 eBPF 的开发人员将他们的程序附加到各种类型的探测器 - 放置在内核或应用程序的代码中,当到达时,将在执行其原始代码之前或之后运行附加到它们的程序。Caretta 利用 eBPF 获取网络数据,通过 Prometheus 汇聚数据,并且通过 grafana 大盘展示。Caretta 是基于 tcplife 的启发,它是一个使用 eBPF 计算 TCP 生命周期统计数据和信息的好工具。
"tcplife" 插件可以用于监视和分析 TCP 连接的各个阶段和事件,比如连接建立、数据传输、连接关闭等。它可以捕获和记录关于 TCP 连接的相关信息,如连接持续时间、数据包统计、延迟等,并提供一些有用的指标和分析结果。这对于网络故障排除、性能优化以及网络安全分析等方面都很有用。关键词:tcp_set_state、tcp_data_queue 等。
为什么 tcp_data_queue 函数?
原理:网络数据收集机制原理 - 探测 tcp_data_queue 以观察网络套接字在其已建立状态下更新其统计信息,并探测 tcp_set_state 以跟踪其生命周期。使用此函数的优点是 tcp_set_state 和大多数内核 TCP 函数一样,它的第一个参数是一个 struct sock 对象。
具有轻量级、高效性、简单化、可视化等显著特点。
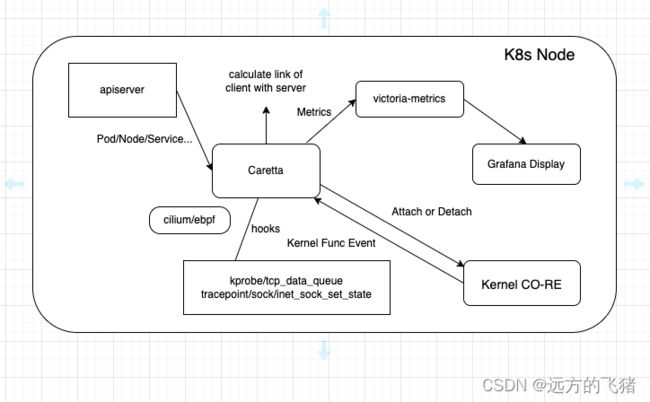
原理
有一个 Grafana 实例查询 VictoriaMetrics (caretta-vm) 代理(并在其 Web UI 上显示此地图);
Victoria agent 从 caretta daemonset 中抓取指标;
Victoria 代理和 Caretta 都使用了 Kubernetes 服务公开的 kubernetes API;
下面是 Caretta Agent 发布的时间序列指标示例:
caretta_links_observed{client_id="1074587981",client_kind="Deployment",client_name="checkoutservice",client_namespace="demo-ng",link_id="198768460",role="1",server_id="1112713827",server_kind="Service",server_name="productcatalogservice",server_namespace="demo-ng",server_port="3550"} 2537
在此连接中,我们可以看到 checkoutservice 向名为 productcatalogservice 的服务发送 2537 个字节。请注意,某些标签的生成完全符合 Grafana 期望显示节点图的格式。
Caretta 整体流程如下所示:
案例
前提条件
-
Linux 内核版本 >= 4.16。
-
支持 CO-RE。可见 CORE,(Compile Once – Run Everywhere)。
Couldn't load probes - error loading BPF objects from go-side. field HandleSockSetState: program handle_sock_set_state: apply CO-RE relocations: load kernel spec: no BTF found for kernel version 3.10.0-1160.83.1.el7.x86_64: not supported
部署应用
部署 Caretta 组件
helm repo add groundcover https://helm.groundcover.com/
helm repo update
helm install caretta --namespace caretta --create-namespace groundcover/caretta
Caretta 常见指标
Caretta 的 helm chart 使用 Caretta 自带的数据发布了一个带有预定义仪表板的 Grafana 实例。此仪表板包含一些示例来演示 Caretta 指标的用法。
使用提供的 Grafana 实例:
kubectl port-forward --namespace caretta 3000:3000 抓取 Caretta 的指标:
Caretta 的主要指标是 caretta_links_observed (Gauge)。 它使用以下标签来表示通过集群的特定连接(网络套接字):
-
client_name - kubernetes 实体的名称(如果已解析)、外部域(如果已解析)或 IP 地址。
-
client_namespace - kubernetes 实体的命名空间,或“节点”,或“外部”。
-
client_kind - kubernetes 实体的种类,或“节点”,或“外部”。
-
server_name - kubernetes 实体的名称(如果已解析)、外部域(如果已解析)或 IP 地址。
-
server_namespace - kubernetes 实体的命名空间,或“节点”,或“外部”。
-
server_kind - kubernetes 实体的种类,或“节点”,或“外部”。
-
server_port - 服务器使用的端口。
-
role - 1(客户端)或 2(服务器)。
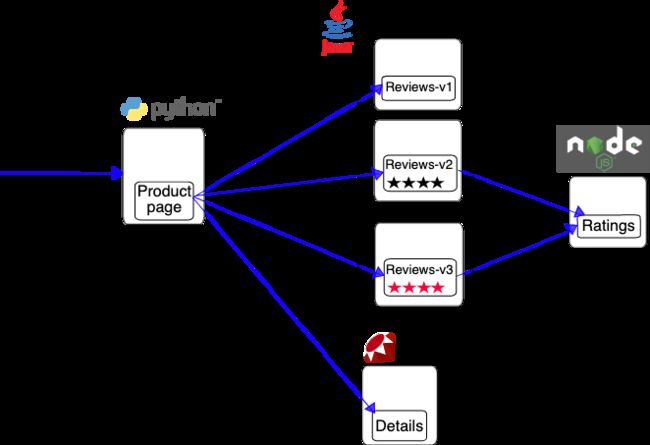
k8s 应用网络拓扑图如下所示:
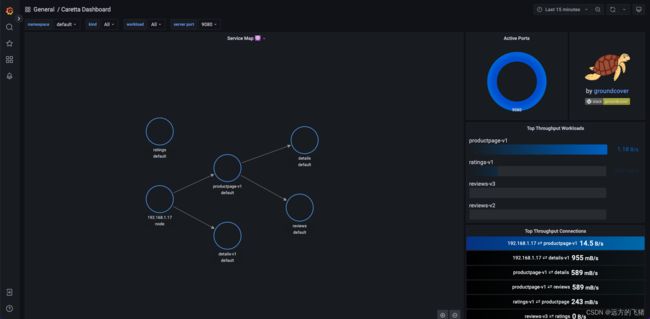
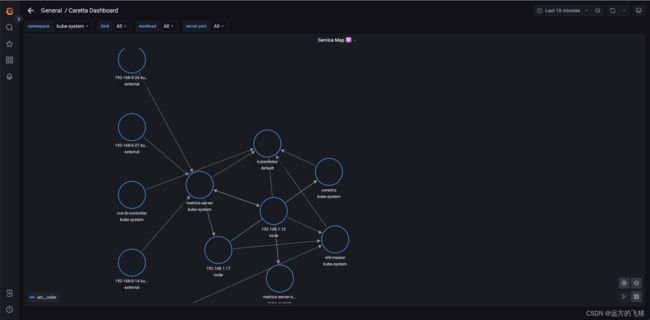
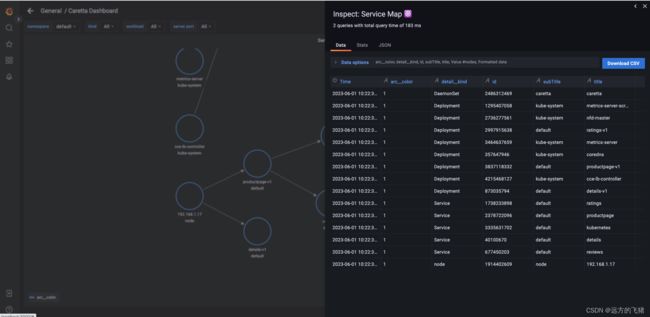
删除 Caretta 组件
helm delete caretta --namespace caretta源码
内核 eBPF 代码:
#include "core_structures.h"
#include "arm_support.h"
#include
#include
#include
#include "ebpf_utils.h"
#include "epbf_shared_types.h"
#include "ebpf_internel_types.h"
char __license[] SEC("license") = "Dual MIT/GPL";
// internal kernel-only map to hold state for each sock observed.
struct bpf_map_def SEC("maps") sock_infos = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(struct sock *),
.value_size = sizeof(struct sock_info),
.max_entries = MAX_CONNECTIONS,
};
// the main product of the tracing - map containing all connections observed,
// with metadata and throughput stats.
// key is a whole identifier struct and not a single id to split the constant
// and dynamic values and to resemble as closely as possible the end result in
// the userspace code.
struct bpf_map_def SEC("maps") connections = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(struct connection_identifier),
.value_size = sizeof(struct connection_throughput_stats),
.max_entries = MAX_CONNECTIONS,
};
// helper to convert short int from BE to LE
static inline u16 be_to_le(__be16 be) { return (be >> 8) | (be << 8); }
static inline u32 get_unique_id() {
return bpf_ktime_get_ns() % __UINT32_MAX__; // no reason to use 64 bit for this
}
// function for parsing the struct sock
static inline int
parse_sock_data(struct sock *sock, struct connection_tuple *out_tuple,
struct connection_throughput_stats *out_throughput) {
if (sock == NULL) {
return BPF_ERROR;
}
// struct sock wraps struct tcp_sock and struct inet_sock as its first member
struct tcp_sock *tcp = (struct tcp_sock *)sock;
struct inet_sock *inet = (struct inet_sock *)sock;
// initialize variables. IP addresses and ports are read originally
// big-endian, and we will convert the ports to little-endian.
__be16 src_port_be = 0;
__be16 dst_port_be = 0;
// read connection tuple
if (0 != bpf_core_read(&out_tuple->src_ip, sizeof(out_tuple->src_ip),
&inet->inet_saddr)) {
return BPF_ERROR;
}
if (0 != bpf_core_read(&out_tuple->dst_ip, sizeof(out_tuple->dst_ip),
&inet->inet_daddr)) {
return BPF_ERROR;
}
if (0 != bpf_core_read(&src_port_be, sizeof(src_port_be), &inet->inet_sport)) {
return BPF_ERROR;
}
out_tuple->src_port = be_to_le(src_port_be);
if (0 != bpf_core_read(&dst_port_be, sizeof(dst_port_be), &inet->inet_dport)) {
return BPF_ERROR;
}
out_tuple->dst_port = be_to_le(dst_port_be);
// read throughput data
if (0 != bpf_core_read(&out_throughput->bytes_received,
sizeof(out_throughput->bytes_received),
&tcp->bytes_received)) {
return BPF_ERROR;
}
if (0 != bpf_core_read(&out_throughput->bytes_sent,
sizeof(out_throughput->bytes_sent), &tcp->bytes_sent)) {
return BPF_ERROR;
}
return BPF_SUCCESS;
};
static inline enum connection_role get_sock_role(struct sock* sock) {
// the max_ack_backlog holds the limit for the accept queue
// if it is a server, it will not be 0
int max_ack_backlog = 0;
if (0 != bpf_core_read(&max_ack_backlog, sizeof(max_ack_backlog),
&sock->sk_max_ack_backlog)) {
return CONNECTION_ROLE_UNKNOWN;
}
return max_ack_backlog == 0 ? CONNECTION_ROLE_CLIENT : CONNECTION_ROLE_SERVER;
}
// probing the tcp_data_queue kernel function, and adding the connection
// observed to the map.
SEC("kprobe/tcp_data_queue")
static int handle_tcp_data_queue(struct pt_regs *ctx) {
// first argument to tcp_data_queue is a struct sock*
struct sock *sock = (struct sock *)PT_REGS_PARM1(ctx);
struct connection_identifier conn_id = {};
struct connection_throughput_stats throughput = {};
if (parse_sock_data(sock, &conn_id.tuple, &throughput) == BPF_ERROR) {
return BPF_ERROR;
}
// skip unconnected sockets
if (conn_id.tuple.dst_port == 0 && conn_id.tuple.dst_ip == BPF_SUCCESS) {
return BPF_SUCCESS;
}
// fill the conn_id extra details from sock_info map entry, or create one
struct sock_info *sock_info = bpf_map_lookup_elem(&sock_infos, &sock);
if (sock_info == NULL) {
// first time we encounter this sock
// check if server or client and insert to the maps
enum connection_role role = get_sock_role(sock);
struct sock_info info = {
.pid = 0, // can't associate to pid anyway
.role = role,
.is_active = true,
.id = get_unique_id(),
};
bpf_map_update_elem(&sock_infos, &sock, &info, BPF_ANY);
conn_id.pid = info.pid;
conn_id.id = info.id;
conn_id.role = info.role;
throughput.is_active = true;
bpf_map_update_elem(&connections, &conn_id, &throughput, BPF_ANY);
return BPF_SUCCESS;
}
conn_id.pid = sock_info->pid;
conn_id.id = sock_info->id;
conn_id.role = sock_info->role;
if (!sock_info->is_active) {
return -1;
}
throughput.is_active = sock_info->is_active;
bpf_map_update_elem(&connections, &conn_id, &throughput, BPF_ANY);
return BPF_SUCCESS;
};
static inline int handle_set_tcp_syn_sent(struct sock* sock) {
// start of a client session
u32 pid = bpf_get_current_pid_tgid() >> 32;
struct sock_info info = {
.pid = pid,
.role = CONNECTION_ROLE_CLIENT,
.is_active = true,
.id = get_unique_id(),
};
bpf_map_update_elem(&sock_infos, &sock, &info, BPF_ANY);
return BPF_SUCCESS;
}
static inline int handle_set_tcp_syn_recv(struct sock* sock) {
// this is a server getting syn after listen
struct connection_identifier conn_id = {};
struct connection_throughput_stats throughput = {};
if (parse_sock_data(sock, &conn_id.tuple, &throughput) == BPF_ERROR) {
return BPF_ERROR;
}
struct sock_info info = {
.pid = 0, // can't associate to process
.role = CONNECTION_ROLE_SERVER,
.is_active = true,
.id = get_unique_id(),
};
bpf_map_update_elem(&sock_infos, &sock, &info, BPF_ANY);
// probably the dst ip will still be unitialized
if (conn_id.tuple.dst_ip == 0) {
return BPF_SUCCESS;
}
conn_id.pid = info.pid;
conn_id.id = info.id;
conn_id.role = info.role;
bpf_map_update_elem(&connections, &conn_id, &throughput, BPF_ANY);
return BPF_SUCCESS;
}
static inline int handle_set_tcp_close(struct sock* sock) {
// mark as inactive
struct connection_identifier conn_id = {};
struct connection_throughput_stats throughput = {};
if (parse_sock_data(sock, &conn_id.tuple, &throughput) == BPF_ERROR) {
return BPF_ERROR;
}
struct sock_info *info = bpf_map_lookup_elem(&sock_infos, &sock);
if (info == NULL) {
conn_id.id = get_unique_id();
conn_id.pid = 0; // cannot associate to PID in this state
conn_id.role = get_sock_role(sock);
} else {
conn_id.id = info->id;
conn_id.pid = info->pid;
conn_id.role = info->role;
bpf_map_delete_elem(&sock_infos, &sock);
}
throughput.is_active = false;
bpf_map_update_elem(&connections, &conn_id, &throughput, BPF_ANY);
return BPF_SUCCESS;
}
SEC("tracepoint/sock/inet_sock_set_state")
static int handle_sock_set_state(struct set_state_args *args) {
struct sock *sock = (struct sock *)args->skaddr;
switch(args->newstate) {
case TCP_SYN_RECV: {
return handle_set_tcp_syn_recv(sock) == BPF_ERROR;
}
case TCP_SYN_SENT: {
return handle_set_tcp_syn_sent(sock) == BPF_ERROR;
}
case TCP_CLOSE: {
return handle_set_tcp_close(sock);
}
}
return BPF_SUCCESS;
}
使用 Go 加载 ebpf 代码:
func LoadProbes() (Probes, *ebpf.Map, error) {
if err := rlimit.RemoveMemlock(); err != nil {
return Probes{}, nil, fmt.Errorf("error removing memory lock - %v", err)
}
objs := bpfObjects{}
err := loadBpfObjects(&objs, &ebpf.CollectionOptions{})
if err != nil {
var ve *ebpf.VerifierError
if errors.As(err, &ve) {
fmt.Printf("Verifier Error: %+v\n", ve)
}
return Probes{}, nil, fmt.Errorf("error loading BPF objects from go-side. %v", err)
}
log.Printf("BPF objects loaded")
// attach a kprobe and tracepoint
kp, err := link.Kprobe("tcp_data_queue", objs.bpfPrograms.HandleTcpDataQueue, nil)
if err != nil {
return Probes{}, nil, fmt.Errorf("error attaching kprobe: %v", err)
}
log.Printf("Kprobe attached successfully")
tp, err := link.Tracepoint("sock", "inet_sock_set_state", objs.bpfPrograms.HandleSockSetState, nil)
if err != nil {
return Probes{}, nil, fmt.Errorf("error attaching tracepoint: %v", err)
}
log.Printf("Tracepoint attached successfully")
// We are done with loading kprobes - clear the btf cache
btf.FlushKernelSpec()
return Probes{
Kprobe: kp,
Tracepoint: tp,
BpfObjs: objs,
}, objs.Connections, nil
}解析工作负载 trace 链路拓扑图:
// a single polling from the eBPF maps
// iterating the traces from the kernel-space, summing each network link
func (tracer *LinksTracer) TracesPollingIteration(pastLinks map[NetworkLink]uint64) (map[NetworkLink]uint64, map[NetworkLink]uint64) {
// outline of an iteration -
// filter unwanted connections, sum all connections as links, add past links, and return the new map
pollsMade.Inc()
unroledCounter := 0
loopbackCounter := 0
currentLinks := make(map[NetworkLink]uint64)
var connectionsToDelete []ConnectionIdentifier
var conn ConnectionIdentifier
var throughput ConnectionThroughputStats
entries := tracer.connections.Iterate()
// iterate the map from the eBPF program
itemsCounter := 0
for entries.Next(&conn, &throughput) {
itemsCounter += 1
// filter unnecessary connection
if throughput.IsActive == 0 {
connectionsToDelete = append(connectionsToDelete, conn)
}
// skip loopback connections
if conn.Tuple.SrcIp == conn.Tuple.DstIp && isAddressLoopback(conn.Tuple.DstIp) {
loopbackCounter++
continue
}
// filter unroled connections (probably indicates a bug)
link, err := tracer.reduceConnectionToLink(conn)
if conn.Role == UnknownConnectionRole || err != nil {
unroledCounter++
continue
}
currentLinks[link] += throughput.BytesSent
}
mapSize.Set(float64(itemsCounter))
unRoledConnections.Set(float64(unroledCounter))
filteredLoopbackConnections.Set(float64(loopbackCounter))
// add past links
for pastLink, pastThroughput := range pastLinks {
currentLinks[pastLink] += pastThroughput
}
// delete connections marked to delete
for _, conn := range connectionsToDelete {
tracer.deleteAndStoreConnection(&conn, pastLinks)
}
return pastLinks, currentLinks
}参考
1、Navigate your way to production bliss with Caretta
2、https://github.com/groundcover-com/caretta