每日学术速递6.8
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects(CVPR 2023)

标题:BundleSDF:未知对象的神经 6-DoF 跟踪和 3D 重建
作者:Bowen Wen, Jonathan Tremblay, Valts Blukis, Stephen Tyree, Thomas Muller, Alex Evans, Dieter Fox, Jan Kautz, Stan Birchfield
文章链接:https://arxiv.org/abs/2303.14158
项目代码:https://bundlesdf.github.io/
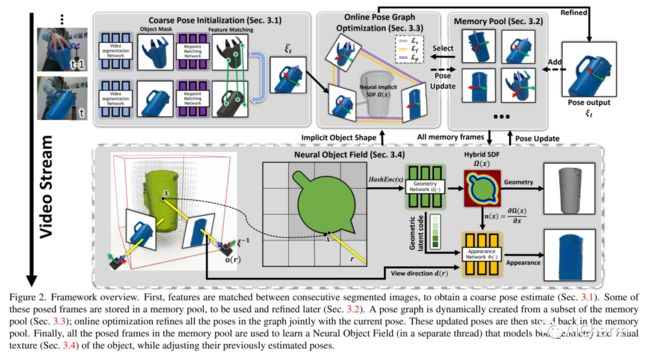

摘要:
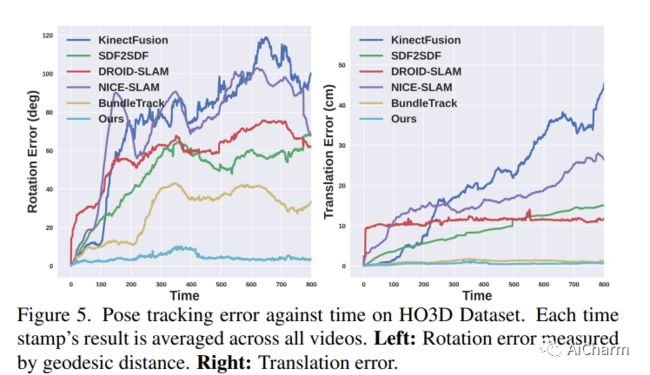
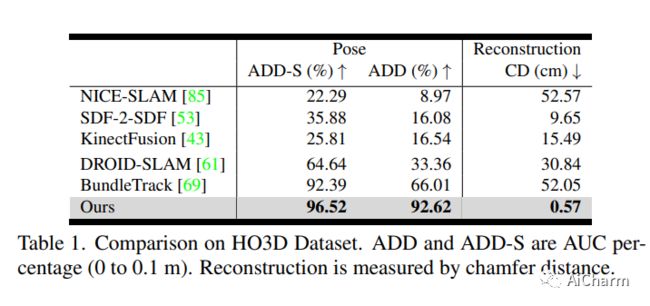
我们提出了一种近乎实时的方法,用于从单目 RGBD 视频序列中对未知物体进行 6-DoF 跟踪,同时对物体进行神经 3D 重建。我们的方法适用于任意刚性物体,即使在视觉纹理基本不存在的情况下也是如此。假定对象仅在第一帧中被分割。不需要其他信息,并且不对交互代理做出任何假设。我们方法的关键是神经对象场,它与姿势图优化过程同时学习,以便将信息稳健地积累到一致的 3D 表示中,同时捕获几何和外观。自动维护一个动态的 posed 内存帧池,以促进这些线程之间的通信。我们的方法可以处理具有较大姿势变化、部分和完全遮挡、无纹理表面和镜面高光的具有挑战性的序列。我们在 HO3D、YCBInEOAT 和 BEHAVE 数据集上展示了结果,表明我们的方法明显优于现有方法。
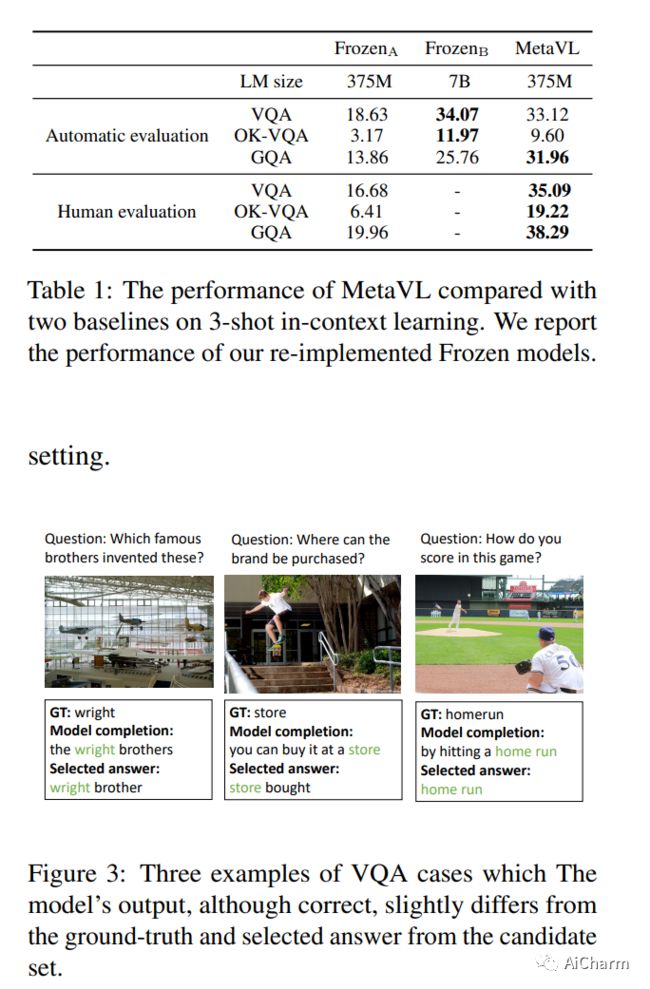
2.MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models

标题:MetaVL:将上下文学习能力从语言模型转移到视觉语言模型
作者:Masoud Monajatipoor, Liunian Harold Li, Mozhdeh Rouhsedaghat, Lin F. Yang, Kai-Wei Chang
文章链接:https://arxiv.org/abs/2306.01311
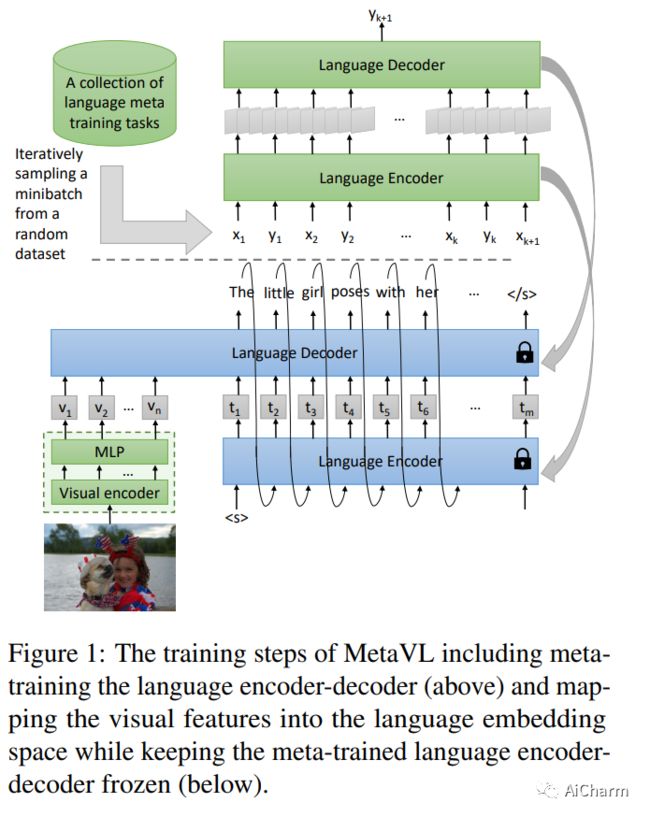


摘要:
大型语言模型已经显示出通过对一些演示进行调节(即上下文学习)来适应新任务的能力。然而,在视觉语言领域,大多数大规模预训练视觉语言(VL)模型不具备进行上下文学习的能力。我们如何为 VL 模型启用上下文学习?在本文中,我们研究了一个有趣的假设:我们能否将上下文学习能力从语言领域迁移到 VL 领域?具体来说,我们首先对语言模型进行元训练,以对 NLP 任务执行上下文学习(如在 MetaICL 中);然后我们通过附加一个视觉编码器来转移这个模型来执行 VL 任务。我们的实验表明,确实可以跨模态转移上下文学习能力:我们的模型大大提高了 VL 任务的上下文学习能力,甚至可以显着补偿模型的大小。在 VQA、OK-VQA 和 GQA 上,我们的方法可以胜过基线模型,同时参数减少 20 倍。
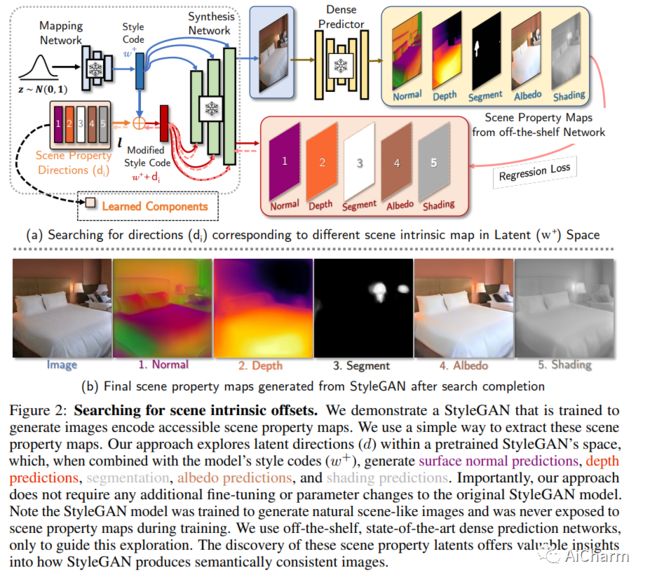
3.StyleGAN knows Normal, Depth, Albedo, and More

标题:StyleGAN 知道法线、深度、反照率等
作者:Anand Bhattad, Daniel McKee, Derek Hoiem, D.A. Forsyth
文章链接:https://arxiv.org/abs/2306.00987



摘要:
在原始意义上,固有图像是深度、法线、反照率或阴影等场景属性的类图像映射。本文证明了 StyleGAN 可以很容易地被诱导产生内在图像。程序很简单。我们表明,如果 StyleGAN 从潜在的 w 中生成 G(w) ,那么对于每种类型的固有图像,都有一个固定的偏移量 dc ,因此 G(w+dc) 是 G(w) 的那种类型的固有图像。这里 dc {独立于 w }。我们使用的 StyleGAN 是由其他人预训练的,所以这个属性不是我们训练制度的意外。我们表明 StyleGAN 将{not}以这种方式产生图像转换,因此 StyleGAN 不是通用图像回归引擎。从概念上讲,图像生成器应该“知道”并表示内在图像是令人兴奋的。使用生成模型生成内在图像也可能具有实际优势。从 StyleGAN 获得的内在图像在定性和定量上都与使用 SOTA 图像回归技术获得的图像进行了比较;但与 SOTA 方法不同,StyleGAN 的固有图像对重新照明效果具有鲁棒性。
更多Ai资讯:公主号AiCharm