Spark中python和jvm的通信杂谈--ArrowConverter
背景
要提起ArrowConverters,就得说起Arrow这个项目,该项目的初衷是加速进程间的数据交换,从目前的社区发展以及它的周边来看,其实是一个很不错的项目。
那为什么Spark要引入Arrow呢?其实还得从Pyspark中python和jvm的交互方式上说起,目前pyspark采用的py4j与spark jvm进行交互,而数据的交换采用的是jvm和python两个进程间的数据交换(感兴趣的同学可以参考PySpark架构),这个时候引进Arrow恰到好处。
闲说杂谈
spark具体采用的是Arrow IPC,
而IPC中用到了flatbuffers这种高效获取序列化数据的组件,再加上IPC采用的是Java NIO的ByteBuffer零拷贝的方式以及RecordBatch列批的方式,大大提升了进程间的数据交换效率。关于NIO的零拷贝参考NIO效率高的原理之零拷贝与直接内存映射
具体细节
直接到ArrowConverters的类中:
主要看两个方法:toBatchIterator和fromBatchIterator
- ArrowConverters.toBatchIterator
private[sql] def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Long,
timeZoneId: String,
context: TaskContext): ArrowBatchIterator = {
new ArrowBatchIterator(
rowIter, schema, maxRecordsPerBatch, timeZoneId, context)
}
这个主要是把spark内部的InternalRow转换为ArrowRecordBatches,方法直接就是返回ArrowBatchIterator类型(Iterator[Array[Byte]]类型)的迭代器:
- ArrowConverters.fromBatchIterator
private[sql] def fromBatchIterator(
arrowBatchIter: Iterator[Array[Byte]],
schema: StructType,
timeZoneId: String,
context: TaskContext): Iterator[InternalRow] = new InternalRowIteratorWithoutSchema(
arrowBatchIter, schema, timeZoneId, context
)
这个主要是把序列化的ArrowRecordBatche转换为Spark内部的InternalRow,这里也是直接返回了InternalRowIteratorWithoutSchema类型的迭代器,这里就涉及到了内存的零拷贝,具体的方法如下:
override def nextBatch(): (Iterator[InternalRow], StructType) = {
val arrowSchema = ArrowUtils.toArrowSchema(schema, timeZoneId)
val root = VectorSchemaRoot.create(arrowSchema, allocator)
resources.append(root)
val arrowRecordBatch = ArrowConverters.loadBatch(arrowBatchIter.next(), allocator)
val vectorLoader = new VectorLoader(root)
vectorLoader.load(arrowRecordBatch)
arrowRecordBatch.close()
(vectorSchemaRootToIter(root), schema)
}
其中涉及的调用链如下:
ArrowConverters.loadBatch
||
\/
MessageSerializer.deserializeRecordBatch
||
\/
readMessageBody
||
\/
ReadChannel.readFully
||
\/
buffer.nioBuffer
||
\/
getDirectBuffer
最后的getDirectBuffer直接返回的是DirectByteBuffer直接内存,这样可以避免了JVM内存到native内存的数据拷贝,尤其是在大数据场景下,提升的效率更加明显,且减少了用户态和内核态的切换次数。
-
怎么运用到python与spark jvm的交互中
调用网上的Pyspark的架构图
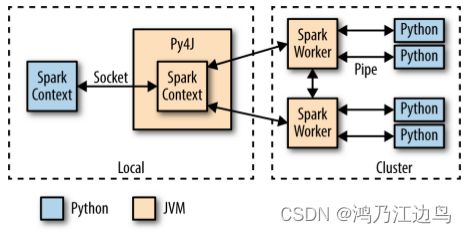
参考具体conversion.py中部分代码如下:
jrdd = self._sc._serialize_to_jvm(arrow_data, ser, reader_func, create_RDD_server) jdf = self._jvm.PythonSQLUtils.toDataFrame(jrdd, schema.json(), jsqlContext)主要在self._jvm.PythonSQLUtils.toDataFrame这个方法中,python调用spark中方法,把序列化的*Iterator[Array[Byte]]*传给jvm执行,具体的细节,读者可以自行参考源代码.
其他
在最新发布的Spark-3.4.0中有一项SPIP,也是采用了Arrow IPC作为数据传输的格式。
当然Arrow Flight SQL也将是一个很好的技术点。