网络解析----yolov3网络解析
Yolov3是一种针对目标检测任务的神经网络模型,其网络结构主要由三个部分组成:特征提取网络、检测头和非极大值抑制(NMS)模块。特征提取网络采用Darknet-53作为骨干网络,Darknet-53由53个卷积层和5个Max-Pooling层组成,可以提取图像的高层次特征。检测头是由三个卷积层和两个全连接层组成,用于检测目标的位置和类别。其中,第一个卷积层用于缩小特征图的尺寸,第二个卷积层用于提取特征,第三个卷积层用于预测边界框的坐标和置信度得分。非极大值抑制模块用于去除重叠的边界框,确保每个目标只被检测一次。Yolov3的网络结构具有高效性和准确性,可以在处理速度和检测精度之间取得平衡,因此被广泛应用于计算机视觉领域的目标检测任。
Yolov3在Yolov2的基础上进行了许多改进。Yolov3的网络结构与Yolov2相似,都采用了Darknet架构,但Yolov3使用了更多的卷积层和更大的输入尺寸,从而使得网络更深更广,并且能够检测到更小的物体。此外,Yolov3还使用了三个不同尺度的特征图来检测不同大小的物体,从而提高了检测的准确性和召回率。此外,Yolov3还引入了一种新的技术,称为"Bag of Freebies",该技术通过数据增强、改进的训练策略和更好的网络初始化来提高模型的性能。综上所述,Yolov3相比Yolov2具有更好的性能和更高的准确性,特别是在检测小物体方面表现更加突出。

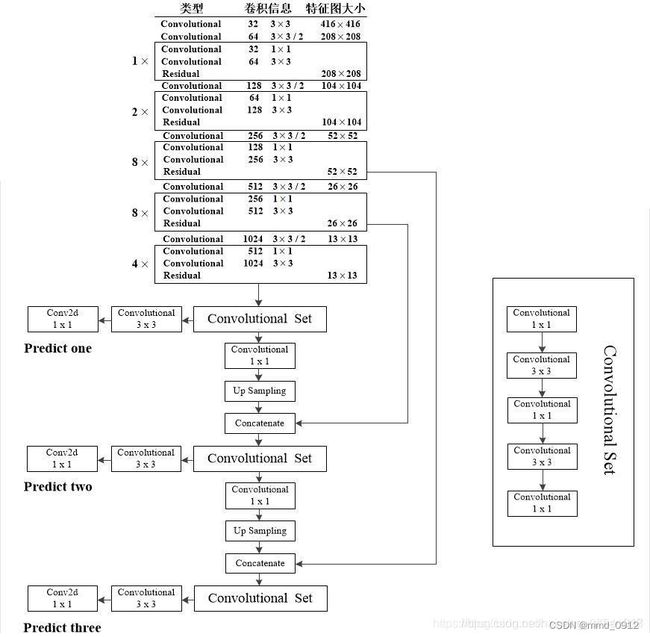
原始yolov3的网络
[net]
batch=1 # 所有的图片分成all_num/batch个批次,每batch个样本(64)更新一次参数,尽量保证一个batch里面各个类别都能取到样本
subdivisions=1 # 决定每次送入显卡的图片数目 batch/subdivisions
width=608 # 送入网络的图片宽度
height=608 # 送入网络的图片高度
channels=3 # 送入网络的图片通道数
momentum=0.949 # 动量参数,表示梯度下降到最优值的速度
decay=0.0005 # 权重衰减正则项,防止过拟合.
angle=0 # 图片角度变化
saturation = 1.5 # 图片饱和度
exposure = 1.5 # 图片曝光量
hue=.1 # 图片色调
learning_rate=0.001 # 学习率,影响权值更新的速度
burn_in=1000
max_batches = 40200 # 训练最大次数
policy=steps # 学习率调整策略
steps=40000,45000 # 学习率调整时间
scales=.1,.1 # 学习率调整倍数
[convolutional] # 利用32个大小为3*3*3的滤波器步长为1,填充值为1进行过滤然后用leaky函数进行激活
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky # DBL模块 (416 + 2 * 1 - 3)/ 1 + 1 = 416 # 416 * 416 * 32
# Downsample
[convolutional] # 利用64个大小为3*3*3的滤波器步长为1,填充值为1进行过滤然后用leaky函数进行激活
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky #(416 + 2 * 1 - 3)/ 2 + 1 = 208 208*208*64
[convolutional] # 利用32个大小为1*1*3的滤波器步长为1,填充值为1进行过滤然后用leaky函数进行激活
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky #(208 + 2 * 1 - 3)/ 1 + 1 = 208 208*208*32
[convolutional] # 利用64个大小为3*3*3的滤波器步长为1,填充值为1进行过滤然后用leaky函数进行激活
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky #(208 + 2 * 1 - 3)/ 1 + 1 = 208 208*208*64
[shortcut] #shortcut 操作是类似 ResNet 的跨层连接
from=-3 # 参数 from 是 −3,意思是 shortcut 的输出是当前层与先前的倒数第三层相加而得到,通俗来讲就是 add 操作
activation=linear # res_unit 416*416*128
# Downsample
[convolutional]
batch_normalize=1
filters=128
size=3
stride=2
pad=1
activation=leaky #(416 + 2 * 1 - 3)/ 2 + 1 = 208 208*208*128
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky #(208 + 2 * 1 - 1)/ 1 + 1 = 208 208*208*64
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear # res_unit
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear # res_unit
# Downsample
[convolutional]
batch_normalize=1
filters=256
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=512
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
# Downsample
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
[shortcut]
from=-3
activation=linear
######################
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=1024
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 18,22, 33,28, 44,61, 62,56, 61,119, 116,100, 180,198, 244,226
classes=3
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 18,22, 33,28, 44,61, 62,56, 61,119, 116,100, 180,198, 244,226
classes=3
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route] #当属性layers有两个值,就是将上一层和从当前层倒数第7层进行融合,大于两个值同理
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 18,22, 33,28, 44,61, 62,56, 61,119, 116,100, 180,198, 244,226
classes=3
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
shortcut的操作代码:
import torch
import torch.nn as nn
class ShortcutBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ShortcutBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1)
# 此处可以添加其他层,如卷积、BN、激活函数等
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
def forward(self, x):
residual = self.conv1(x)
out = self.conv2(x)
out += residual # 执行shortcut的add操作
return out
训练时的实时日志:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BF
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BF
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32 0.177 BF
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64 1.595 BF
4 Shortcut Layer: 1
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128 1.595 BF
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
8 Shortcut Layer: 5
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64 0.177 BF
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128 1.595 BF
11 Shortcut Layer: 8
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256 1.595 BF
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
15 Shortcut Layer: 12
16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
18 Shortcut Layer: 15
19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
21 Shortcut Layer: 18
22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
24 Shortcut Layer: 21
25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
27 Shortcut Layer: 24
28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
30 Shortcut Layer: 27
31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
33 Shortcut Layer: 30
34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
36 Shortcut Layer: 33
37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512 1.595 BF
38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
40 Shortcut Layer: 37
41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
43 Shortcut Layer: 40
44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
46 Shortcut Layer: 43
47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
49 Shortcut Layer: 46
50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
52 Shortcut Layer: 49
53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
55 Shortcut Layer: 52
56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
58 Shortcut Layer: 55
59 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
60 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
61 Shortcut Layer: 58
62 conv 1024 3 x 3 / 2 26 x 26 x 512 -> 13 x 13 x1024 1.595 BF
63 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
64 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
65 Shortcut Layer: 62
66 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
67 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
68 Shortcut Layer: 65
69 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
70 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
71 Shortcut Layer: 68
72 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
73 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
74 Shortcut Layer: 71
75 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
76 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
77 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
78 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
79 conv 512 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 512 0.177 BF
80 conv 1024 3 x 3 / 1 13 x 13 x 512 -> 13 x 13 x1024 1.595 BF
81 conv 18 1 x 1 / 1 13 x 13 x1024 -> 13 x 13 x 18 0.006 BF
82 yolo
83 route 79
84 conv 256 1 x 1 / 1 13 x 13 x 512 -> 13 x 13 x 256 0.044 BF
85 upsample 2x 13 x 13 x 256 -> 26 x 26 x 256
86 route 85 61
87 conv 256 1 x 1 / 1 26 x 26 x 768 -> 26 x 26 x 256 0.266 BF
88 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
89 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
90 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
91 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256 0.177 BF
92 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512 1.595 BF
93 conv 18 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 18 0.012 BF
94 yolo
95 route 91
96 conv 128 1 x 1 / 1 26 x 26 x 256 -> 26 x 26 x 128 0.044 BF
97 upsample 2x 26 x 26 x 128 -> 52 x 52 x 128
98 route 97 36
99 conv 128 1 x 1 / 1 52 x 52 x 384 -> 52 x 52 x 128 0.266 BF
100 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
101 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
102 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
103 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128 0.177 BF
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BF
105 conv 18 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 18 0.025 BF
106 yolo