【前端工程化】包管理器的发展
前阵子突然刷到了tnpm,然后学习了一下其中的优化npm install的原理,虽然对对业务没什么帮助,但是学习一些优化思想还是很有好处的。学习的过程中,刚好来总结一下这几年npm、yarn、pnpm的有点和缺点。
起源
- 一开始时候使用网址来共享代码,比如想使用JQuery的时候就去JQuery官网使用它的下载链接,弊端就是,每次用到其他人的开源代码的时候,就要逐个去找它对应的下载链接,然后引入到文件中;
- npm应运而生:用一个工具把这些开源代码集中到一起来管理,需要的时候执行命令就可以引入到项目中,然而早期的时候大家也不太愿意把代码丢到一块地方去;
- node.js诞生之后,急需一个包管理工具,与npm一拍即合,于是npm开始火了~
npm
npm install原理
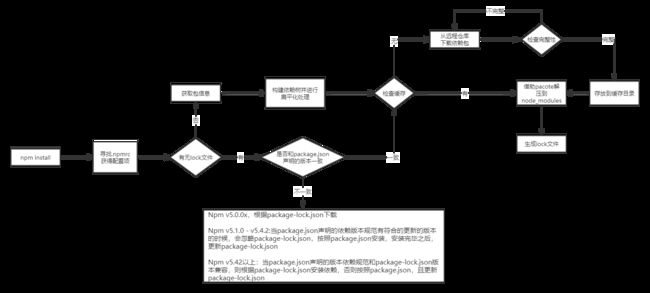
- 从项目级的
.npmrc文件 > 用户级的.npmrc文件 > 全局级的.npmrc>npm内置的.npmrc文件获取配置; - 检查是否有
package-lock.json文件:- 如果有,检查
package-lock.json和package.json声明的依赖是否一致:- 一致,直接使用
package.json来处理依赖关系; - 不一致,根据不同版本走不同的处理。
- 一致,直接使用
- 如果没有,
- 根据
package.json递归构建依赖树关系,构建过程:- 不管是直接依赖还是子依赖,都优先将其放在node_modules根目录中;
- 遇到相同的模块时,判断已经放在依赖树的模块版本是否符合新模块的版本范围,如果符合则跳过,否则在当前模块的node_modules下放置该模块。
- 从缓存中依次找到依赖树中的每个包,判断是否存在缓存:
- 不存在缓存:
- 从
npm远程仓库进行下载 - 校验包的完整性:
- 不通过,重新下载;
- 校验通过:
- 将下载的压缩包复制到缓存目录;
- 将下载的包借助
pacote解压到node_modules
- 从
- 存在缓存,将缓存的包借助
pacote解压到node_modules
- 不存在缓存:
- 将缓存的包借助
pacote解压到node_modules - 生成
package-lock.json文件。
- 根据
- 如果有,检查
扁平化结构
浪费资源
前面提到了npm3以后采用了扁平化的结构,但是这是结构也是有弊端的,假设我们现在需要安装:
node_modules
└──A
└──node_modules
└──B V1.0
└──C
└──node_modules
└──B V2.0
└──D
└──node_modules
└──B V2.0
└──E
从前面的安装机制不难猜出,由于A依赖包内部依赖了B V1.0,所以,A依赖包和B V1.0都会被安装到根目录,在安装C依赖包时,由于跟目录已经有B V2.0,所以B V2.0会被安装在C的node_modules中,D同理。即node_modules的结构大概如下:
node_modules
├──A
├──B V1.0
└──C
└──node_modules
└──B V2.0
└──D
└──node_modules
└──B V2.0
└──E
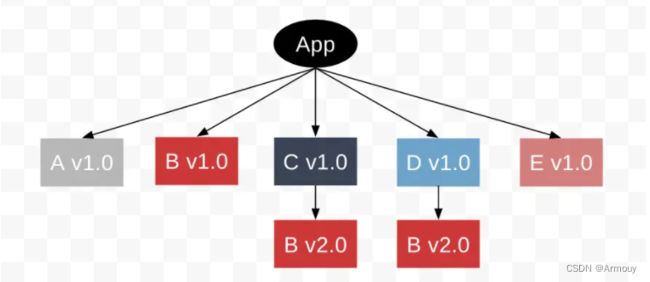
这里就不难发现,版本重复了,浪费了资源空间。
不确定性 Non-Determinism
同样的 package.json 文件,install 依赖后可能不会得到同样的 node_modules 目录结构。
还是之前的例子,A 依赖 [email protected],C 依赖 [email protected],依赖安装后究竟应该提升 B 的 1.0 还是 2.0。
node_modules
├── [email protected]
├── [email protected]
└── [email protected]
└── node_modules
└── [email protected]
└── [email protected]
└── node_modules
└── [email protected]
node_modules
├── [email protected]
│ └── node_modules
│ └── [email protected]
├── [email protected]
└── [email protected]
└── [email protected]
取决于用户的安装顺序。
重复模块:,它指的是模块名相同且 semver(语义化版本) 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,
phantom dependency(幽灵依赖)
可以非法访问没有声明过依赖的包。虽然我们在dependencies中没有直接写B模块,但是我们可以直接require('B');这就是phantom dependency。一旦将该库被发布,因为用户安装这个库的时候并不会安装B模块,所以会报错。
耗时长
扁平化算法本身复杂性很高,耗时较长。
Yarn
Yarn优化了npm3的一些问题:依赖安装速度慢,不确定性。
提升安装速度
在 npm 中安装依赖时,安装任务是串行的,会按包顺序逐个执行安装,这意味着它会等待一个包完全安装,然后再继续下一个。
为了加快包安装速度,yarn 采用了并行操作,在性能上有显著的提高。而且在缓存机制上,yarn 会将每个包缓存在磁盘上,在下一次安装这个包时,可以脱离网络实现从磁盘离线安装。
lockfile 解决不确定性
在依赖安装时,会根据 package.josn 生成一份 yarn.lock 文件,记录了依赖,以及依赖的子依赖,依赖的版本,获取地址与验证模块完整性的 hash。即使是不同的安装顺序,相同的依赖关系在任何的环境和容器中,都能得到稳定的 node_modules 目录结构,保证了依赖安装的确定性。
弊端
还是没有解决幽灵依赖和依赖分身的问题。
npm后来也借助了package-lock.json来解决不确定性的问题。V5版本之后也加入了缓存策略,所以随着npm的升级,yarn的很多优点并不是很明显了。
CNPM
加速下载相关源文件。原理上来说,cnpm做的事情,就是给大家换了个registry。
今年6月份淘宝源换了地址,所以之后使用cnpm需要更新或者更换一下最新的
registry
地址:原淘宝 npm 域名即将停止解析
Yarn berry
抛弃node_modules
无论是 npm 还是 yarn,都具备缓存的功能,大多数情况下安装依赖时,其实是将缓存中的相关包复制到项目目录中 node_modules 里。涉及到IO操作,都是很耗费时间的。
而 yarn PnP 则不会进行拷贝这一步,而是在项目里维护一张静态映射表 pnp.cjs。
pnp.cjs 会记录依赖在缓存中的具体位置,所有依赖都存在全局缓存中。同时自建了一个解析器,在依赖引用时,帮助 node 从全局缓存目录中发现依赖,而不是查找 node_modules。
这样就避免了大量的 I/O 操作同时项目目录也不会有 node_modules 目录生成,同版本的依赖在全局也只会有一份,依赖的安装速度和解析速度都有较大提升。
脱离node生态
- 因为使用 PnP 不会再有
node_modules了,但是Webpack,Babel等各种前端工具都依赖node_modules。虽然很多工具比如pnp-webpack-plugin已经在解决了,但难免会有兼容性风险。 - PnP 自建了依赖解析器,所有的依赖引用都必须由解析器执行,因此只能通过 yarn 命令来执行 node 脚本。
PNPM
优势
前面提到了npm3采用了扁平化结构,这里存在几个问题:
- 磁盘资源占用率高;
- phantom dependency,可以非法访问没有声明过依赖的包
- 扁平化算法复杂,耗时较长。
而pnpm都对上述问题,做了改进。
pnpm i express
查看node_modules文件夹:
.pnpm
.modules.yaml
express
这里的express是一个软连接,里面没有node_modules目录,而真正的文件位置在.pnpm-store文件夹里。
▾ node_modules
▾ .pnpm
▸ [email protected]
▸ [email protected]
...
▾ [email protected]
▾ node_modules
▸ accepts -> ../[email protected]/node_modules/accepts
▸ array-flatten -> ../[email protected]/node_modules/array-flatten
...
▾ express
▸ lib
History.md
index.js
LICENSE
package.json
Readme.md
这种结果可以与package.json 声明的依赖基本保持一致,还减少了资源的占用率。通过这种依赖方式的管理还解决了依赖提升的安全问题。
弊端
项目隔离
因为 .pnpm 中都是通过硬链接来链接到同一份源码文件,当我们在某个项目中修改了这个包的文件时,所有项目中这个包都会被修改,这导致无法做到修改的项目隔离。
修复依赖
前端开发过程中,经常会遇到第三方开源库有 BUG 的情况,通常我们有以下处理方式。
- 自己 fork 一份源码修改,修复完后就可以本地打包直接用了。如果你想分享你的研究成果给其他人,可以再传到 npm 仓库或者提交 PR 给源仓库。这种方式有个缺点,就是笔记难保持和官方库的同步。
- 等待库作者修复。这种方式不太靠谱,因为开源作者一般都会比较忙,你的需求可能不会排在前面。
- 借助
pacth-package给本地npm包打补丁。
然而pacth-package并不支持pnpm。
npm的优化方向
蚂蚁集团 npm 工程师零弌在 SEE Conf 2022 支付宝体验科技大会上给分享了 一种秒级安装 npm 的方式:tnpm(蚂蚁集团鲁班奖),文中提出了npm install的痛点及优化方案:
HTTP请求

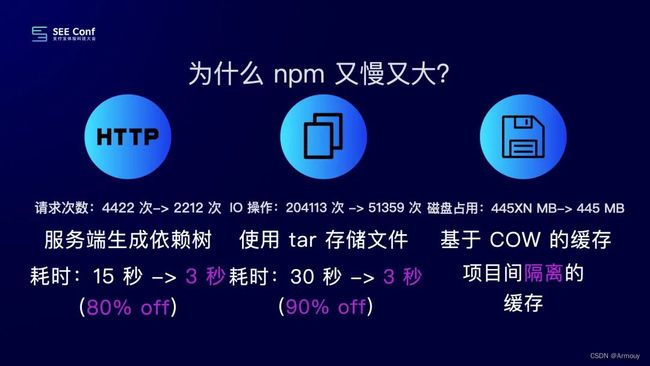
不考虑缓存的情况下, 在执行 npm install的时候,我们会按顺序、递归地去获取当前依赖的包信息、并将其对应的tar下载下来,即这样HTTP请求的数量会越来越多,会导致依赖树生成的时间逐渐增多。
对此,可以 通过聚合的方式来减少 HTTP 请求量。
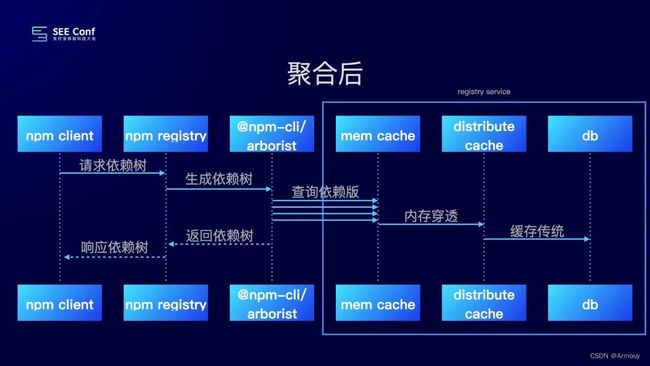
将项目的 package.json 发送到服务端,在服务端运行 @npmcli/arborist 来生成依赖树。将 arborist 访问 registry 的 HTTP 接口,直接劫持到我们的 registry服务。通过内存缓存/分布式缓存/DB 来加速依赖树的生成过程。
@npmcli/arborist是npm底层检查和管理node_modules树的包。
IO操作

文中以他安装的包为例子,当拉取tar包到本地之后,解压之后其中涉及的IO操作有:创建文件夹、写入文件、bin文件的软连接、对bin的读写权限设置。即共涉及13次IO操作。
由于npm install的时候是从仓库拉取对应依赖包的tar包,缓存的时候也是tar包,所以优化方式从tar入手。如果不需要解压tar包即都不需要上面这些IO操作:

tar 可以很简单的在尾部添加文件。因此我们可以将两个 tar 合并在一起。
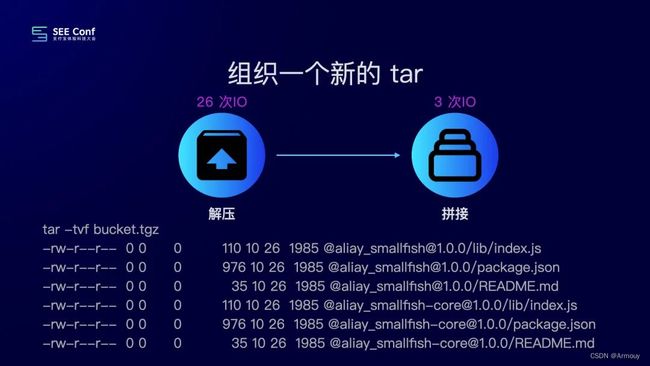
写入两个包的流程将会变成:
fs.createFile:创建出公共的文件fs.appendFile:将第一个包写入fs.appendFile:将第二个包写入
从 26 次 IO 减少到了 3 次 IO操作。
虽然现在下载安装飞快,但是装完的东西没法用。tar 完全不是 JS 文件,没法直接用 JS 去 require,没法在 shell 里操作,更没法在 IDE 里编辑。一切习惯都被打破了。接下来我们就需要解决 tar 的读写问题。
研究一下通过 JS 去require的过程:
- 通过
fs.readFile这个 API 去发起一个文件读请求。 - JS 方法构造出
libuv中的uv_req_t数据结果 libuv会调用libc中的read方法。read方法会发起系统调用,来访问内核中的文件系统去读取文件。
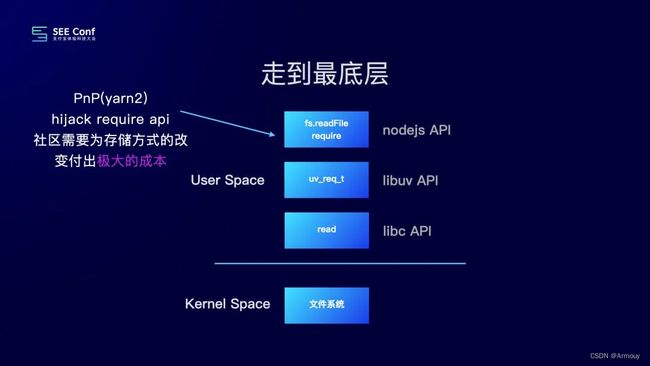
PnP 采用了 zip 包的形式保存。通过劫持 node 的 require 方法来实现 zip 包的读取,通过开发 IDE 插件的方式来支持在 IDE 中读取。但是社区中有大量的实现是通过 fsAPI 去遍历 node_modules 目录,开发者也会使用 shell 去进行一些依赖操作。对于现有的使用习惯破坏较大。

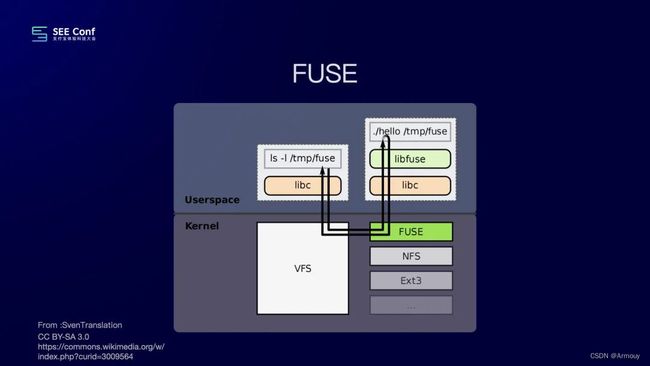
- 解决对tar文件的读取:使用FUSE(FUSE 全称是 FileSystem In UserSpace,是Linux 中用于挂载某些网络空间,如SSH,到本地文件系统的模块)在用户态程序来实现一个文件系统;
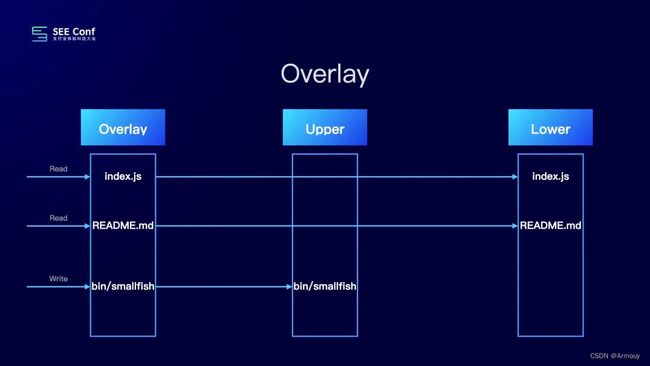
- 解决对tar文件的修改:借助Overlay文件系统(Overlay文件系统是Docker容器中广泛使用的文件系统,写作时复制的思想是将文件分为两层,分为lower和upper。)Lower 目录是只读的,Upper 目录是可读写的,我们可以将 Overlay 把 Upper 和 Lower 目录组合在一起,构造出一个可读写的目录。对于文件的修改会反映到 Upper 目录中,而不会影响到 Lower 目录。解决了项目隔离。
缓存
解决完安装速度之后,我们还要解决最终的磁盘空间问题,现在 npm 安装之后占用了太多空间,黑洞之称实至名归。
NPM 采用全局 tar 的缓存来加速下载过程,减少重复的下载。但是每次解压还是占用了太多时间。
pnpm 采用文件硬链的形式来减少写入量,但是硬链代表全局指向了同一个文件,比如两个项目依赖了同一个包,如果其中一个在 debug 进行了一些改动,会影响到另一个包,造成意料之外的影响。
Overlay 还有一个特性是 COW(Copy On Write),在修改底层文件的时候会将底层的文件拷贝到上层目录中。因此我们可以使用同一份缓存,来支持全局所有的项目。
其他
Corepack「管理包管理器的管理器」
Corepack是一个实验性工具,在 Node.js v16.13 版本中引入.
- 不再需要专门全局安装 yarn pnpm 等工具。
- 可以强制团队项目中使用他特定的包管理器版本,而无需他们在每次需要进行更新时手动同步它,如果不符合配置将在控制台进行错误提示。
可以在 package.json中配置:
"packageManager": "[email protected]"
// 声明的包管理器,会自动下载对应的 yarn,然后执行
yarn install
// 用非声明的包管理器,会自动拦截报错
pnpm install
Usage Error: This project is configured to use yarn
试验阶段存在的问题:
- 目前仅支持 pnpm 和 yarn,cnpm 也是不支持的
- 兼容性还有些问题,npm 还无法拦截也就是说 即便配置了 packageManager 使用 yarn,但是依然可以调用全局 npm 安装
@antfu/ni
在它运行之前,它会检测你的 yarn.lock / pnpm-lock.yaml / package-lock.json 以了解当前的包管理器,并运行相应的命令。
使用 `ni` 在项目中安装依赖时:
假设你的项目中有锁文件 `yarn.lock`,那么它最终会执行 `yarn install` 命令。
假设你的项目中有锁文件 `pnpm-lock.yaml`,那么它最终会执行 `pnpm i` 命令。
假设你的项目中有锁文件 `package-lock.json`,那么它最终会执行 `npm i` 命令。
npm i -g @antfu/ni
ni
参考
- 《一种秒级安装 npm 的方式 - 零弌》演讲视频 + 文字版
- npm install 原理分析
- 深入浅出 npm & yarn & pnpm 包管理机制
- 记录一次组内npm&pnpm分享
- Node.js Corepack
- 尤雨溪推荐神器 ni ,能替代 npm/yarn/pnpm ?简单好用!源码揭秘!
如有错误,欢迎指出,感谢阅读~