第一天,PyTorch张量的运算
文章目录
- 一、说明
- 二、张量的常用运算
-
- 1. 索引和切片(与numpy类似)
- 2. 通过`torch.cat`来进行连接张量
- 3. 矩阵运算和算数运算
-
- 1. 在PyTorch中`mul`与`matmul`和`@`的区别
- 2. 矩阵运算和算数运算的示例
- 4. 聚合张量中的所有值
- 5. 给所有元组增加1,使用add_,同理的还有其他的
- 三,张量的计算
一、说明
张量运算,包括算术、线性代数、矩阵运算(转置、索引、切片)、采样等。这些操作中的每一个都可以在 GPU 上运行(速度通常高于 CPU),默认情况下,张量是在 CPU 上创建的。我们需要使用方法将张量显式移动到 GPU .to(在检查 GPU 可用性之后)。注意的是:跨设备复制大型张量在时间和内存方面可能会很昂贵!
例如:
# We move our tensor to the GPU if available
if torch.cuda.is_available():
tensor = tensor.to("cuda")
-
实现神经网络:神经网络是深度学习的核心,它是由多个层组成的,每一层都包含了一些张量的运算。在神经网络中,张量的运算被广泛应用于计算输入和输出之间的权重、偏差、激活函数等。 -
数据处理:在深度学习中,我们通常需要对数据进行预处理和转换。例如,图像分类任务中,我们需要将原始图像转换为张量并进行归一化操作。这些操作通常都涉及到对张量进行各种运算,如平均值计算、标准差计算、数据增强等。 -
特征提取:特征提取是深度学习中另一个重要的应用场景。在这个过程中,我们需要使用卷积运算从原始数据中提取出关键特征。卷积运算可以用于图像识别、语音识别等领域,它可以帮助我们从原始数据中提取出最有价值的信息。 -
模型评估:在深度学习中,我们通常需要对模型进行评估,以确定其性能如何。为此,我们需要使用各种张量的运算来计算模型的精度、召回率、F1得分等指标。
二、张量的常用运算
1. 索引和切片(与numpy类似)
例如:
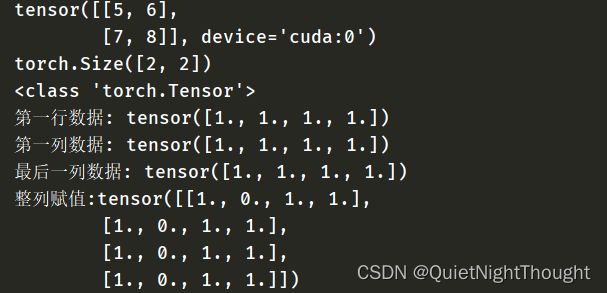
tensor = torch.ones((4,4))
print(f"第一行数据: {tensor[0]}")
print(f"第一列数据: {tensor[:, 0]}")
print(f"最后一列数据: {tensor[..., -1]}")
tensor[:,1] = 0
print(f"整列赋值:{tensor}")
2. 通过torch.cat来进行连接张量
torch.cat()函数在二维数据和三维数据上的详细说明
例如:
#接上面的张量设置
t = torch.cat([tensor,tensor,tensor],dim=1)
print('拼接结果:',t)

3. 矩阵运算和算数运算
1. 在PyTorch中mul与matmul和@的区别
mul是逐元素相乘。当两个张量具有相同的形状时,使用mul对这两个张量进行逐元素相乘。例如,如果有一个大小为3x3的张量a和另一个大小也为3x3的张量b,则使用a.mul(b)将得到一个大小为3x3的张量,其中每个元素都是a和b对应位置上的元素相乘得到的结果。
mul的例子:
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = a.mul(b)
print(result)
matmul是矩阵相乘。当两个张量不具有相同的形状时,我们使用matmul函数执行矩阵相乘。例如,如果有一个大小为3x4的张量a和另一个大小为4x5的张量b,则使用matmul(a, b)将得到一个大小为3x5的张量,其中每个元素都是a和b矩阵相乘后得到的结果。
import torch
a = torch.tensor([[1, 2], [3, 4], [5, 6]])
b = torch.tensor([[7, 8], [9, 10]])
result = torch.matmul(a, b)
print(result)
@符号是矩阵相乘的简写形式。与matmul函数类似,@符号也用于执行矩阵相乘的操作。可以使用x @ y或者torch.matmul(x, y)来计算两个张量的矩阵乘积。例如,如果有一个大小为3x4的张量a和另一个大小为4x5的张量b,则使用a @ b或者torch.matmul(a, b)将得到一个大小为3x5的张量,其中每个元素都是a和b矩阵相乘后得到的结果。
import torch
a = torch.tensor([[1, 2], [3, 4], [5, 6]])
b = torch.tensor([[7, 8], [9, 10]])
result = a @ b
print(result)
2. 矩阵运算和算数运算的示例
- 矩阵运算
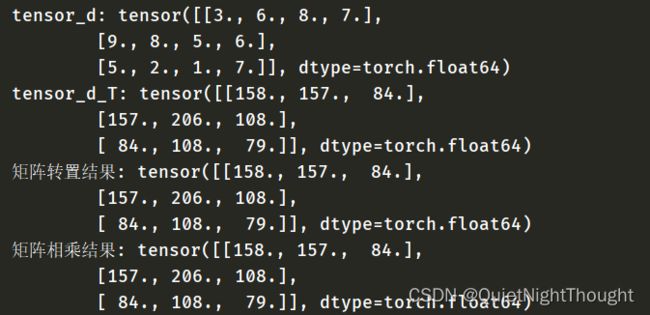
tensor_d = torch.tensor(np.array([
[3.,6.,8.,7.],
[9.,8.,5.,6.],
[5.,2.,1.,7.]
]))
print('tensor_d:',tensor_d)
tensor_d_T = tensor_d.matmul(tensor_d.T)
print('tensor_d_T:',tensor_d_T)
y1 = tensor_d @ tensor_d.T
print('矩阵转置结果:',y1)
y3 = torch.rand_like(y1)
y2 = torch.matmul(tensor_d,tensor_d.T,out=y3)
print('矩阵相乘结果:',y2)
- 乘法运算
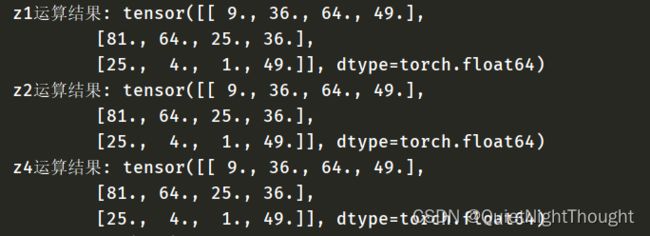
tensor_e = torch.tensor(np.array([
[3.,6.,8.,7.],
[9.,8.,5.,6.],
[5.,2.,1.,7.]
]))
z1 = tensor_e * tensor_e
print('z1运算结果:',z1)
z2 = tensor_e.mul(tensor_e)
print('z2运算结果:',z2)
z3 = torch.rand_like(tensor_e)
z4 = torch.mul(tensor_e, tensor_e, out=z3)
print('z4运算结果:',z4)
4. 聚合张量中的所有值
agg = tensor.sum()
print('agg:',agg)
![]()
agg_item = agg.item() #将其转换为 Python 数值
print(agg_item, type(agg_item))
![]()
5. 给所有元组增加1,使用add_,同理的还有其他的
print(f"{tensor} \n")
tensor.add_(1)
print(tensor)
add_()是一个in-place方法,它将张量中所有元素都加上1,并直接改变了原始张量的值。这意味着,当我们执行a.add_(1)时,张量a中的每个元素都会增加1,而不会创建新的变量。这种方法可用于更新权重、偏差等参数,以及执行其他需要直接改变张量的操作。
需要注意的是,in-place操作往往具有副作用,可能会导致难以预测的结果。因此,在使用in-place方法时,一定要确保自己清楚地知道这种方法的影响,并且仅在必要时使用它们。
三,张量的计算
更为全面的阅读
涵盖一百多种张量运算