js逆向系列之猿人学爬虫第12题-入门级js
文章目录
- 1. 目标网站
- 2. 初步抓包
- 3. 逆向分析
- 4. 编码测试
-
- 参考代码1(python + js版)
- 参考代码2(纯python版)
1. 目标网站
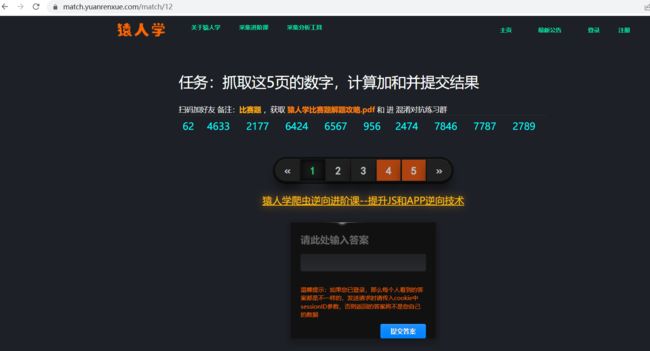
网址:
http://match.yuanrenxue.com/match/12
2. 初步抓包
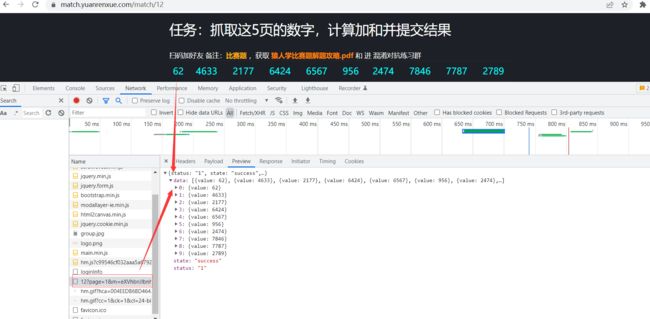
包也很容易找到:
看一下请求:
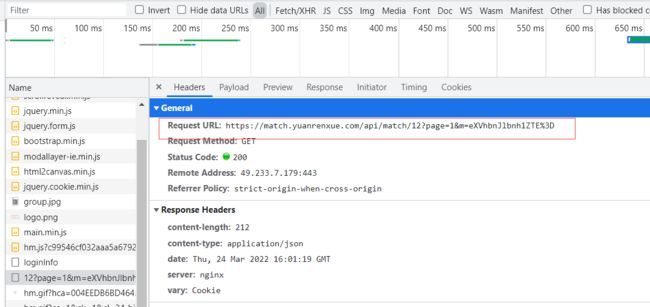
看一下payload的携带参数只有page和m,这里就可以初步估计翻页就靠url里的page和m的值控制。
看一下第2页:
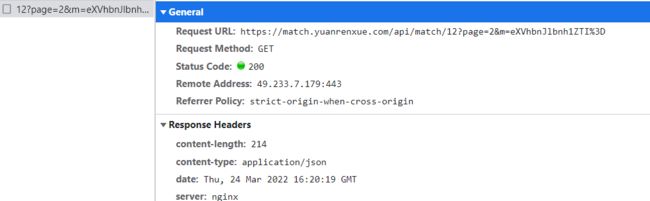
好家伙,这个m乍一看还以为俩都一样,实际上是有一个字母不一样,果然如猜测的那般改了page,m。
3. 逆向分析
看一下请求回调,
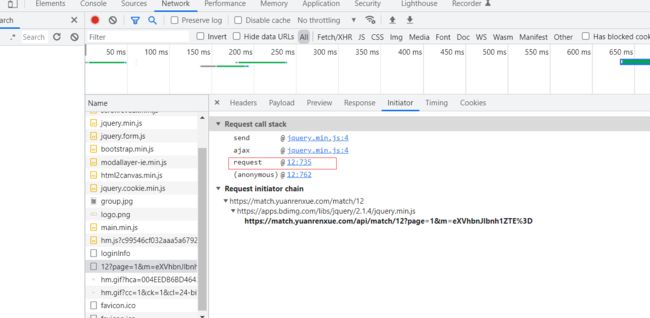
直接点request,跳转进入:
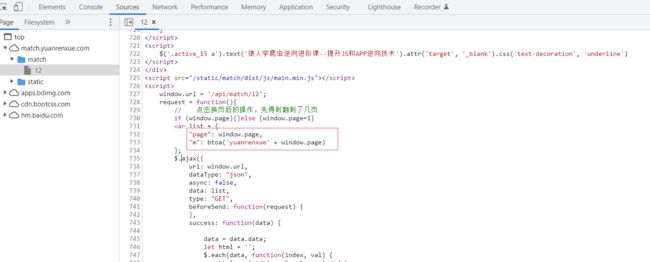
可以看到page和m的参数生成,所谓的page就是窗口的page这个没啥,而m看着是一个btoa方法传进两个字符串拼接生成的。
接下来我们就直接在这个地方打个断点调试一下:
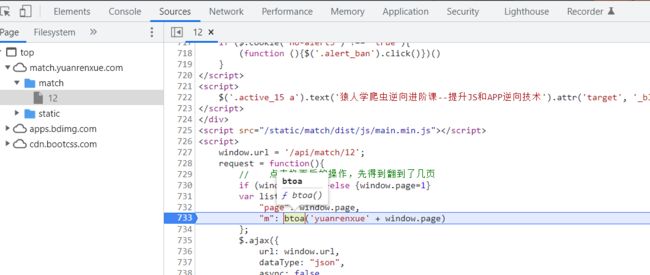
断在这里,实际上btoa这个家伙就是浏览器自带的函数,类似的还有atob。
好家伙,我们直接百度搜一下js btoa ,
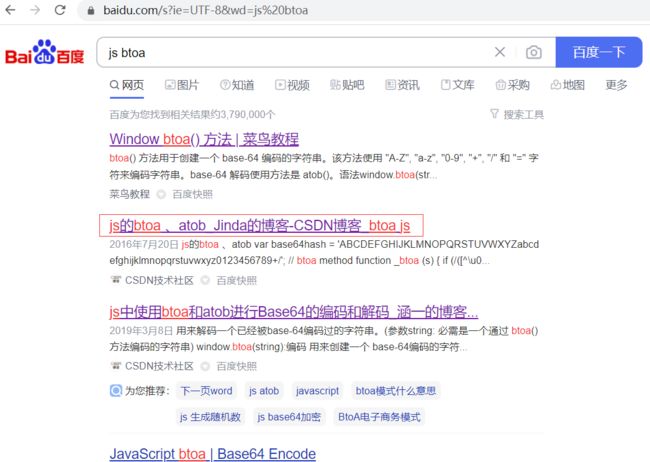
把这个方法复制下来:
var base64hash = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
// btoa method
function btoa (s) {
if (/([^\u0000-\u00ff])/.test(s)) {
throw new Error('INVALID_CHARACTER_ERR');
}
var i = 0,
prev,
ascii,
mod,
result = [];
while (i < s.length) {
ascii = s.charCodeAt(i);
mod = i % 3;
switch(mod) {
// 第一个6位只需要让8位二进制右移两位
case 0:
result.push(base64hash.charAt(ascii >> 2));
break;
//第二个6位 = 第一个8位的后两位 + 第二个8位的前4位
case 1:
result.push(base64hash.charAt((prev & 3) << 4 | (ascii >> 4)));
break;
//第三个6位 = 第二个8位的后4位 + 第三个8位的前2位
//第4个6位 = 第三个8位的后6位
case 2:
result.push(base64hash.charAt((prev & 0x0f) << 2 | (ascii >> 6)));
result.push(base64hash.charAt(ascii & 0x3f));
break;
}
prev = ascii;
i ++;
}
// 循环结束后看mod, 为0 证明需补3个6位,第一个为最后一个8位的最后两位后面补4个0。另外两个6位对应的是异常的“=”;
// mod为1,证明还需补两个6位,一个是最后一个8位的后4位补两个0,另一个对应异常的“=”
if(mod == 0) {
result.push(base64hash.charAt((prev & 3) << 4));
result.push('==');
} else if (mod == 1) {
result.push(base64hash.charAt((prev & 0x0f) << 2));
result.push('=');
}
return result.join('');
}
调试验证一下:
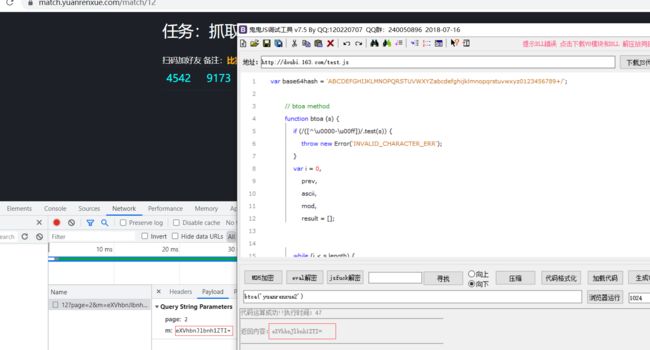
完全一样,没啥问题,这也太简单了吧。。。
其实还可以更简单,看上面的js代码,这个方法是可以用python直接写出来的,特别简单:
def btoa(s):
return base64.b64encode(s.encode()).decode()
print(btoa('yuanrenxue2'))
结果:

这样的话写python代码就更简单了。。。
但是我还是走一下流程吧,就用python直接调js生成m,接下来咱们就直接写代码吧。
4. 编码测试
编码过程中,有一点要注意,看一下页面:
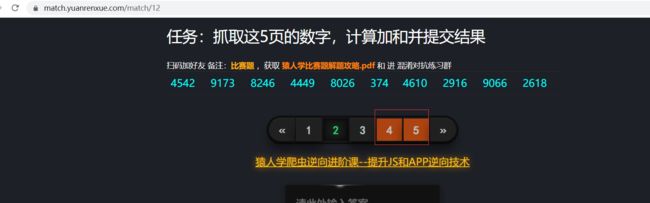
第四页和第五页,明显和前三页不一样,难道是又整了啥幺蛾子?
点一下看看:

我们在浏览器上不登录就看不了,提示需要我们加个user-agent,还需要传cookie的sessionid,而有效的sessionid是必须登录才可以看的,要登陆肯定要注册账号,要注册账号则必须填邀请码,而要填邀请码必须加这个大佬的微信:
稍微有点麻烦,我写博客的现在时间是凌晨2:15,
![]()
我现在加大佬的微信怕是不太好。
先爬前三页吧,反正逆向的大致思路已经清楚了,就差一个登录传cookie的sessionid就可以拿到第4,5页了。
无关紧要,逆向主要学的就是思路,这里附一下代码,我只计算了前三页,如果想全弄下来就老实注册传cookie的sessionid就完事了。
参考代码1(python + js版)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 冰履踏青云
# @File : 12.py
import requests
import execjs
import jsonpath
def get_m(page):
'''获取m值'''
with open('12.js','r',encoding='utf-8') as f:
js = f.read()
s = 'yuanrenxue' + str(page)
m = execjs.compile(js).call('btoa',s)
return m
# print(get_m(1))
def get_data(page):
'''获取数据'''
url = 'https://match.yuanrenxue.com/api/match/12?'
headers = {
"User-Agent":"yuanrenxue.project",
"cookie":"sessionid=8a5pzjkldcv7d1gf8epgltw1ybrmdvll"
}
params = {
"page":page,
"m":get_m(page)
}
res = requests.get(url,params=params,headers=headers).json()
values_list = jsonpath.jsonpath(res,"$..value")
return values_list
# print(get_data(1))
if __name__ == '__main__':
res_list = []
for page in range(1,4):
values_list = get_data(page)
res_list.extend(values_list)
print(res_list,len(res_list))
print("前三页数字之和为:",sum(res_list))
结果:

参考代码2(纯python版)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 冰履踏青云
# @File : 不调js.py
import requests
import jsonpath
import base64
def get_m(page):
'''获取m值'''
s = 'yuanrenxue' + str(page)
return base64.b64encode(s.encode()).decode()
def get_data(page):
'''获取数据'''
url = 'https://match.yuanrenxue.com/api/match/12?'
headers = {
"User-Agent":"yuanrenxue.project",
"cookie":"sessionid=8a5pzjkldcv7d1gf8epgltw1ybrmdvll"
}
params = {
"page":page,
"m":get_m(page)
}
res = requests.get(url,params=params,headers=headers).json()
values_list = jsonpath.jsonpath(res,"$..value")
return values_list
if __name__ == '__main__':
res_list = []
for page in range(1,4):
values_list = get_data(page)
res_list.extend(values_list)
print(res_list,len(res_list))
print("前三页数字之和为:",sum(res_list))
结果同上:
