IBM DB2 学习笔记:关系模型、基本概念、数据库实例基本操作、数据库对象
文章目录
- 1. 关系数据模型
-
- 1.1 什么是数据?
- 1.2 为什么使用数据库?
- 1.3 数据库管理系统(DBMS)
- 1.4 数据模型
- 1.5 关系数据模型
- 1.6 关系数据库
-
- 1.6.1 表
- 1.6.2 列
- 1.6.3 域
- 1.6.4 主键(Primary key)
- 1.6 5 外键(Foreign key)
- 1.6.6 规范化
- 2. DB2基本操作
-
- 2.1 第一步:启动当前实例
- 2.2 第二步:建立数据库连接
- 2.3 第三步:操作数据库
- 2.4 断开数据库连接
- 2.5 关闭数据库实例
- 2.6 如何删除已有数据库
- 2.7 如何创建自己的数据库(用户数据库实例)
- 3. SQL概述
-
- 3.1 数据定义语言 (DDL)
- 3.2 数据操作语言 (DML)
- 3.3 数据控制语言 (DCL)
- 3.4 事务控制语言Transaction Control Languages (TCL)
- 4. 深入认识DB2
-
- 4.1 DB2的用户
- 4.2 DB2的环境架构
- 4.3 实例
- 4.4 表空间
- 5. DB2 九大数据库对象
-
- 5.1 什么是数据库对象?
- 5.2 数据库对象详解
-
- 5.2.1 架构(Schema,也称“模式”)
- 5.2.2 表(Table)
-
- 5.2.2.1 基本表
- 5.2.2.2 结果表
- 5.2.2.3 已经声明的临时表
- 5.2.3 视图(View)
- 5.2.4 索引(Index)
- 5.2.5 别名(Alias)
- 5.2.6 序列(Sequence)
- 5.2.7 触发器(Trigger)
- 5.2.8 用户定义函数(USER DENFINE FUCTION)
- 5.2.9 存储过程
- 6. 使用数据对象
-
- 6.1 表
-
- 6.1.1 常用基本命令
- 6.1.2 基本的增删改查
- 6.1.3 联结
-
- 6.1.3.1 笛卡尔乘积
- 6.1.3.2 内联结
- 6.1.3.3 右外联结
- 6.1.3.4 左外联结
- 6.1.3.5 全外联结
- 7. 数据并发性
-
- 7.1 事务
- 7.2 并发性
-
- 7.2.1 并发性问题:丢失更新
- 7.2.2 并发性问题:未提交读(脏读)
- 7.2.3 并发性问题:不可重复读
- 7.2.3 并发性问题:幻影读
- 7.3 并发控制:隔离级别
- 7.4 实施隔离级别:锁
- 7.5 几个隔离级别
-
- 7.5.1 可重复读——最高的隔离级别
- 7.5.2 读稳定性
- 7.5.3 游标稳定性——默认的隔离级别
- 7.5 4 未提交读——最低的隔离等级
- 7.5.6 小结
- 7.6 实验场景模拟
-
- 7.6.1 带有“当前已提交”的“游标稳定性”
-
- 7.6.1.1 “前” 场景:关闭“当前已提交”
- 7.6.1.2 “后” 场景:启用“当前已提交”
- 7.6.2 可重复读
- 7.6.3 读稳定性
- 7.6.4 未提交读
-
- “未提交读”场景:游标稳定性
- “未提交读”场景:未提交读
1. 关系数据模型
1.1 什么是数据?
■ 事实和数据的集合
■ 可以是定量的或者定性的
■ 描述某个变量或者一系列变量
■ 实际上,数据可以被视为依据下述事务观察的结果:
– 测量
– 统计
1.2 为什么使用数据库?
利用数据库提供:
–访问数据的标准接口
–多个用户能够同时插入、更新和删除数据
–修改数据,而不会冒丢失数据或失去数据一致性的风险
–能够处理大量的数据和用户
–数据备份、存储和恢复的工具
–安全性
–减少冗余
–数据独立性
1.3 数据库管理系统(DBMS)
它是一种管理数据库的软件系统
– 提供了访问数据库的接口
– 为应用提供数据服务
• 高效的数据查询和升级机制
• 数据完整性 – 保证即使在发生软件和硬件错误的情况下,数据
也总是正确的
• 其他:备份、压缩、期限、复制,等等
DB2 是一套数据库管理系统
1.4 数据模型
■ 数据模型
– 定义数据被展现或结构化的方式
– 可以利用它来反映如何在软件系统中展现来自现实世界的数
据
■ 数据模型的特征
– 更低级的抽象
– 面向软件开发人员
– 包含具体的实施和协议细节
数据模型的类型
■ 扩展的关系的
■ 实体-关系的
■ 分层的
■ 网状的
■ 面向对象的
■ 对象-关系型的
■ 关系的
■ 语义的
■ 半结构化的(XML)
1.5 关系数据模型
■ 它是一种把数据描述为关系(集合)的数学模型,数据的值由域加
以定义。
■ 着重提供更好的数据独立性
■ 通过关系运算 或关系代数 对数据进行操作

■ 域(或者数据类型)定义了数据可能具有的值的集合
■ 关系由标题和数据内容(body)构成
– 标题:一系列属性
– 数据内容:一系列元组
■ 属性由名称和域(类型)构成
■ 元组是一系列属性值
1.6 关系数据库
■ 关系数据模型中的概念可以被映射在关系数据库中所见到的实施内
容
■ 关系数据库利用表存储数据
– 数据包由行和列构成
– 每个列为一种特定的数据类型
– 每一行显示出各个列的特定值
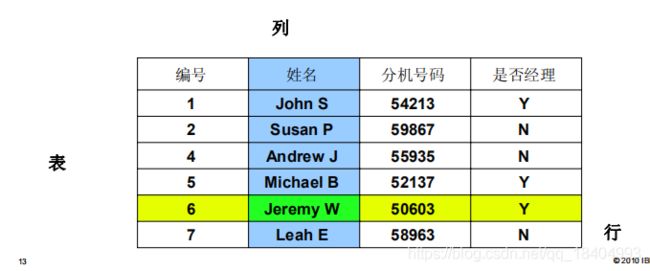
1.6.1 表
■ 表是关系数据模型中某一关系的对应物
■ 表以行和列的方式存储数据
– 行是元组的同义语
– 列是属性的同义语
1.6.2 列
■ 列也被称为字段(或域)
■ 每个字段包含特定类型的信息,例如姓名、分机号码、职位,等等
■ 必须为各个列指定特定的数据类型,
例如 DATE、VARCHAR、
INTEGER,等等
1.6.3 域
域是具体属性的所有可能值的
集合
1.6.4 主键(Primary key)
主键
– 唯一区别关系(表)中的每个元组(行)
– 关系必须具有一个主键
– 关系数据库中的表不要求一定具有主键,但建议这么做
1.6 5 外键(Foreign key)
■ 外键
– 一个关系中的属性,其值与另一个关系的主键相匹配
– 定义了两个数据包之间的关系

1.6.6 规范化

上表中有数据冗余,规范化后

2. DB2基本操作
在虚拟机环境下搭建DB2操作环境
使用IBM DATA STUDIO GUI界面工具 和 终端Terminal工具(db2数据库会话终端)
用户登录 :db2inst1
密码:password
以下演示在终端Terminal工具中操作DB2数据库
2.1 第一步:启动当前实例
**注意:**在Terminal工具中的命令格式为Db2 "select * from act"
正常的SQL语句需要用双引号引起来,并且前面加上db2前缀
启动实例:
db2inst1@db2rules:~> db2start
SQL1026N The database manager is already active.
可使用以下get instance命令显示当前实例信息
db2inst1@db2rules:~> db2 get instance
The current database manager instance is: db2inst1
可以使用list db directory命令显示当前实例下的数据库结点
db2inst1@db2rules:~> db2 list db directory
System Database Directory
Number of entries in the directory = 2
Database 1 entry:
Database alias = STUDENT
Database name = STUDENT
Local database directory = /home/db2inst1
Database release level = d.00
Comment =
Directory entry type = Indirect
Catalog database partition number = 0
Alternate server hostname =
Alternate server port number =
Database 2 entry:
Database alias = SAMPLE
Database name = SAMPLE
Local database directory = /home/db2inst1
Database release level = d.00
Comment =
Directory entry type = Indirect
Catalog database partition number = 0
Alternate server hostname =
Alternate server port number =
可以看到,现在实例中有两个数据库——STUDENT和SAMPLE
其中,SAMPLE数据库时DB2的例程数据库
可以使用db2sampl命令创建SAMPLE数据库
db2inst1@db2rules:~> db2sampl
Creating database "SAMPLE"...
Existing "SAMPLE" database found...
The "-force" option was not specified...
Attempt to create the database "SAMPLE" failed.
SQL1005N The database alias "SAMPLE" already exists in either the local
database directory or system database directory.
'db2sampl' processing complete.
db2inst1@db2rules:~>
可以看到,命令提示“SAMPLE”数据库已存在。
2.2 第二步:建立数据库连接
未建立数据库连接之前,无法执行SQL语句。
必须建立与某个特定数据库的连接
使用connect to命令
db2inst1@db2rules:~> db2 connect to sample
Database Connection Information
Database server = DB2/LINUX 9.7.1
SQL authorization ID = DB2INST1
Local database alias = SAMPLE
以上显示了数据库sample连接成功,并显示出该数据库的基本信息。
以上一句省略了用户名和密码,完整的语句应该如下:
db2 connect to sample [user db2inst1 using password]
2.3 第三步:操作数据库
建立好数据库连接之后,就可以使用SQL语句对数据库表进行操作了。
例如:使用db2 "select * from db2inst1.act”语句进行查询
db2inst1@db2rules:~> db2 "select * from db2inst1.act"
ACTNO ACTKWD ACTDESC
------ ------ --------------------
10 MANAGE MANAGE/ADVISE
20 ECOST ESTIMATE COST
30 DEFINE DEFINE SPECS
40 LEADPR LEAD PROGRAM/DESIGN
50 SPECS WRITE SPECS
60 LOGIC DESCRIBE LOGIC
70 CODE CODE PROGRAMS
80 TEST TEST PROGRAMS
90 ADMQS ADM QUERY SYSTEM
100 TEACH TEACH CLASSES
110 COURSE DEVELOP COURSES
120 STAFF PERS AND STAFFING
130 OPERAT OPER COMPUTER SYS
140 MAINT MAINT SOFTWARE SYS
150 ADMSYS ADM OPERATING SYS
160 ADMDB ADM DATA BASES
170 ADMDC ADM DATA COMM
180 DOC DOCUMENT
18 record(s) selected.
接下来,就可以使用各种SQL语句来对数据库进行操作
例如,创建一个表
db2 "create table temp_2019(id int,name varchar(10))"
DB20000I The SQL command completed successfully.
2.4 断开数据库连接
可使用db2 connect reset命令来断开数据库连接
db2 connect reset
DB20000I The SQL command completed successfully.
2.5 关闭数据库实例
可使用db2stop命令来关闭数据库实例
db2stop
SQL1064N DB2STOP processing was successful.
2.6 如何删除已有数据库
删除之前,同样需要先启动实例
使用的语句为db2 drop db sample
db2inst1@db2rules:~> db2start
SQL1063N DB2START processing was successful.
db2inst1@db2rules:~> db2 drop db sample
DB20000I The DROP DATABASE command completed successfully.
db2inst1@db2rules:~> db2 list db directory
System Database Directory
Number of entries in the directory = 1
Database 1 entry:
Database alias = STUDENT
Database name = STUDENT
Local database directory = /home/db2inst1
Database release level = d.00
Comment =
Directory entry type = Indirect
Catalog database partition number = 0
Alternate server hostname =
Alternate server port number =
db2inst1@db2rules:~>
可以看到,数据库sample被成功删除。
2.7 如何创建自己的数据库(用户数据库实例)
可以使用db2 create db [数据库名]语句创建用户数据库
db2 create db studata
DB20000I The CREATE DATABASE command completed successfully.
db2inst1@db2rules:~> db2 connect to studata
Database Connection Information
Database server = DB2/LINUX 9.7.1
SQL authorization ID = DB2INST1
Local database alias = STUDATA
往新建的数据库中新增数据并查询
db2inst1@db2rules:~> db2 "create table db2inst1.department
> (dno char(4) not NULL unique,
> dname char(20) not NUll,
> head char(20))"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~>
db2inst1@db2rules:~> db2 "insert into db2inst1.department values('1','计算机系','王凯锋')"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~> db2 "insert into db2inst1.department values('2','数学系',' 李永军')"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~> db2 "insert into db2inst1.department values('3','物理系',' 康健')"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~> db2 "insert into db2inst1.department values('4','中文系',' 秦峰')"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~> db2 "select * from department"
DNO DNAME HEAD
---- -------------------- --------------------
1 计算机系 王凯锋
2 数学系 李永军
3 物理系 康健
4 中文系 秦峰
4 record(s) selected.
3. SQL概述
3.1 数据定义语言 (DDL)
定义数据对象的属性
CREATE, ALTER, DROP, TRANSFER OWNERSHIP
3.2 数据操作语言 (DML)
用于检索、添加、编辑和删除数据
SELECT, INSERT, UPDATE, DELETE
3.3 数据控制语言 (DCL)
控制对数据库和数据对象的访问
GRANT, REVOKE
3.4 事务控制语言Transaction Control Languages (TCL)
把 DML 语言组合为事务,它们可以集体用于某个数据库或者
在发生故障时恢复数据库
COMMIT, ROLLBACK, SAVEPOINT
4. 深入认识DB2
4.1 DB2的用户

4.2 DB2的环境架构

4.3 实例
■ 独立的 DB2 环境
■ 每台数据库服务器上可以有多个实例
■ 所有的实例共享相同的可执行二进制文件
■ 各个实例有其自己的配置
■ DB2 允许在相同的机器中存在不同版本(二
进制)的装置
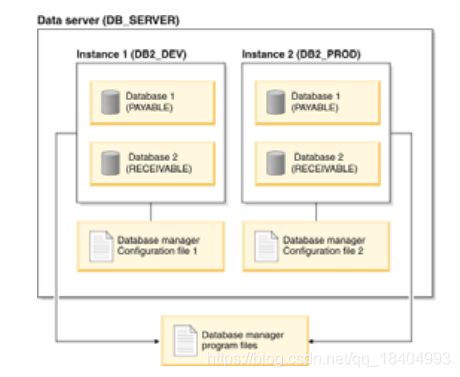

4.4 表空间
■ 逻辑表与物理容器之间的逻辑对象
■ 允许把数据的位置指定给特定的逻辑设
备或者这些设备中的某些分区
■ 所有的表、索引和其他数据都存储在表
空间中
■ 可以与具体的缓存池关联起来

5. DB2 九大数据库对象
服务器、实例和数据库之间的关系

5.1 什么是数据库对象?
–DB2 数据库由一系列对象构成
–数据库包含以下对象:
• 表、视图、索引、架构
• 锁、触发器、存储过程、包
• 缓冲池、日志文件、表空间
创建DB2数据库
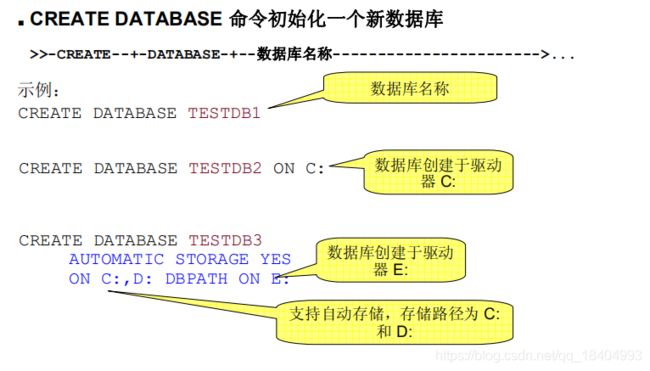
在创建数据库的同时,DB2还自动创建…

5.2 数据库对象详解
5.2.1 架构(Schema,也称“模式”)
■ 架构(唯一标识符)是用来对数据库中的其他对象进行逻辑分类和
分组的对象。
■ 架构具有与其相关的特权,这能够让架构所有者控制哪些用户可以
在其中创建、修改及删除对象。
■ 架构的优势:
–在整个数据库中搜索同名对象是一件乏味的工作
• 每个对象的名称在其架构中应当是独特的
–访问控制
在创建一个对象时,你可以把它指定给特定的架构
– SCHEMA_NAME.OBJECT_NAME
例如
CREATE SCHEMA PAYROLL
CREATE TABLE PAYROLL.STAFF
–名为 STAFF 的表被指定给 PAYROLL 架构
使用以下命令来创建架构:
CREATE SCHEMA payroll AUTHORIZATION db2ist1;
COMMENT ON SCHEMA payroll IS 'schema for payroll
application';

5.2.2 表(Table)
■ 关系数据库把数据展示为表的集合
■ 表由逻辑上安排在列和行(记录)中的数据构成
–每个列中含有具有相同数据类型的值
–每个行中含有关于所提供的各个列的一组值
■ 一个行的存储表达被称为一条记录
■ 一个列的存储表达被称为一条字段
■ 行和列的每个交叉点被称为值
5.2.2.1 基本表
用户定义的、用来保存持久性用户数据的表
CREATE TABLE department
(deptid CHAR(4),
deptname VARCHAR(30),
costcenter INTEGER);
5.2.2.2 结果表
由 DB2 Database Manager 所定义的表,其中的各个列是由在响应查询的
过程中从一个或多个基础表中检索到的行构成的
5.2.2.3 已经声明的临时表
–用户定义的、代表单个应用的、用来临时保存非持久性数据的表。
–在需要时由某个应用显式创建,而在创建该临时表的应用终止其最后一个
数据库连接时,则隐式销毁该临时表。
–利用 DECLARE GLOBAL TEMPORARY TABLE 语句创建
--先创建临时表空间
create user temporary tablespace test
pagesize 4 k managed by system
using ('[curdir]\temp');
--再创建临时表
declare global temporary table temp_1
like department2
on commit preserve rows not logged in test;
--往临时表里添加数据
insert into session.temp_1 select * from department2;
--从临时表里查询
select * from session.temp_1
5.2.3 视图(View)
视图可以被视为从一个或多个表或视图中推导出来的虚拟表
–创建视图是为了限制访问敏感数据,或者把来自不同表的数据组合
到单一对象中。
–视图中不包含真实的数据。
• 只有视图定义本身被实际存储在数据库中
–是可删除的、可更新的、可插入的、只读的。 –当通过视图对数据进行修改时,数据是在基础性的表本身之中被修
改的。
–在检索数据时,可以与表替换使用。
create view myview(deptid_view,deptname_view) as
select deptid,deptname from db2inst1.department2;
select * from myview;
5.2.4 索引(Index)
索引是含有一组经过排序的指针的对象,这些指针指向基础表中的
列。索引以一个或多个列为基础,但被存储为独立的实体。
create unique index dept_index on department2(deptid);

5.2.5 别名(Alias)
别名是供公开引用的名称,因此,使用它们时不需要特别的权限或
特权。
–但是,访问别名所引用的表或视图仍然需要适当的授权。
■ 通过执行 CREATE ALIAS SQL 语句,可以创建别名
create alias dept2 for department2;
select * from dept2
5.2.6 序列(Sequence)
■ 序列是用来自动生成数据值的对象。与标识列不同的是,序列并不与任何特定的列或任何特定的表关联到一起。
–标识列为 DB2 提供了一种方法,用于为添加到表中的每一行自动生
成一个唯一的数字值。
■ 序列有以下特征:
–所生成的值可以是任何准确的数值型数字,其标量为零
(SMALLINT、BIGINT、INTEGER 或 DECIMAL)。
–相邻值可以相差任何规定的增量值。
–计数值是可以恢复的。在需要恢复时,计数值可以从日志中重新构
造出来。
–所生成的值可以缓存,以便改进性能。
■ 序列可以按照下述三种方式之一生成值:
–按照规定数量进行增加或减少,没有界限
–按照规定数量进行增加或减少至用户定义的界限,然后停止
–按照规定数量进行增加或减少至用户定义的界限,然后返回起点,重新开始
■ 示例:你打算创建一个生成数字的序列,自数字 100 开始,每一
个后续数字的增量为10
CREATE SEQUENCE emp_id START WITH 100 INCREMENT BY 10

create sequence dept_seq start with 100 increment by 10;
select nextval for dept_seq from department2;--值往下推进
select prevval for dept_seq from department2;--当前值
运行示例:
db2inst1@db2rules:~> db2 "create sequence abc start with 100 increment by 10"
DB20000I The SQL command completed successfully.
db2inst1@db2rules:~> db2 "select nextval for abc from department"
1
-----------
100
110
120
130
4 record(s) selected.
db2inst1@db2rules:~>
db2inst1@db2rules:~> db2 "select nextval for abc from department"
1
-----------
140
150
160
170
4 record(s) selected.
db2inst1@db2rules:~> db2 "select prevval for abc from department"
1
-----------
170
170
170
170
4 record(s) selected.
5.2.7 触发器(Trigger)
触发器定义了在响应对指定的表进行插入、更新或删除操作时采取
的一系列行动。
■ 与约束条件一样的是,触发器经常用来实施数据完整性和业务规
则。
■ 与约束条件不一样的是,触发器还可以用于更新其他表,自动为所
插入的或更新的行生成或转换值,以及调用函数以便执行发出错误
消息或警报消息等任务。
■ 利用触发器执行在数据库中实施业务规则的逻辑。
–向表中 插入一行时,使所有行的costcenter值增1
create trigger trigger_dept2
after insert on dept2
for each row
update dept2 set costcenter=costcenter+1
select * from dept2
insert into dept2 values('5','english','5')
select * from dept2

5.2.8 用户定义函数(USER DENFINE FUCTION)
■ 用户定义的函数 (UDF) 是一些特殊的对象,,用来扩展或增强
DB2 具有的内置函数所提供的支持。
■ 通过执行 CREATE FUNCTION SQL 语句,可以创建(或者注册)
用户定义的函数
例如:
create function ca(r double)
returns double
language sql
contains sql
NO EXTERNAL ACTION
DETERMINISTIC
RETURN 3.14159 * (r * r);
SELECT ca(96.8) AS area FROM sysibm.sysdummy1
5.2.9 存储过程
■ SQL 存储过程是一段普通的程序,它完全由 SQL 语句构成,可以
被应用调用。
■ 存储过程可以被本地或远程调用。
■ 外部存储过程是利用高级编程语言编写的存储过程
–外部存储过程可以比 SQL 存储过程更强大,因为它们可以把系统调
用和管理 API 与 SQL 语句一同使用。
create procedure create_user(
in in_deptid char(4),
in in_deptname varchar(30),
in in_costcenter int
)
begin
declare v_result varchar(30);
select deptname into v_result from dept2 where deptid=in_deptid;
if(v_result is not null) then
update dept2 set deptid=in_deptid,deptname=in_deptname where costcenter=in_costcenter;
else
insert into dept2 values(in_deptid,in_deptname,in_costcenter);
end if;
end
call create_user('6','japan','6')
6. 使用数据对象
6.1 表
6.1.1 常用基本命令
列出实例中已有的数据库:db2 list database directory
创建新的数据库 db2 create db testdb
创建表:
db2 "CREATE TABLE employees
(empid INTEGER,
name CHAR(50),
dept INTEGER)"
查看表的基本属性 db2 describe table employees
更改表的属性(以把dept的数据类型从intrger改成character为例)
db2 "alter table employees alter colmun dept set data type char(9)"
6.1.2 基本的增删改查
略
6.1.3 联结
■ 把一个或多个表连接到一起
SELECT *
FROM EMPLOYEE E
INNER JOIN TEAM T ON E.TEAMID = T.ID
■ 多种联接类型:
–笛卡尔乘积 (Cartesian Product)
–内联接 (Inner Join)
–左外联接 (Left Outer Join)
–右外联接 (Right Outer Join)
–全外联接 (Full Outer Join)
6.1.3.1 笛卡尔乘积
■ 把每一个条目与相应的条目联接起来,不考虑任何标准
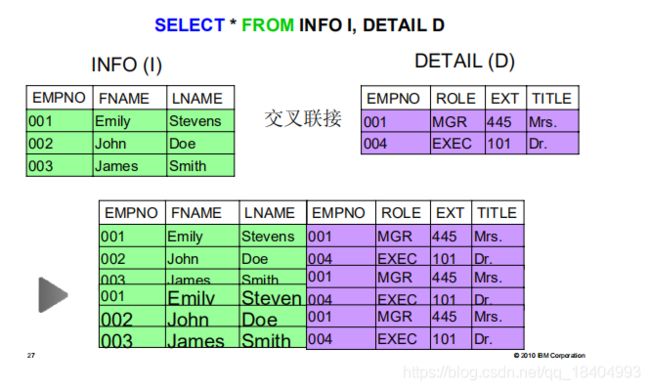
6.1.3.2 内联结
■ 内联接需要两侧匹配
■ 两侧条目都必须满足 ON 子句中规定的条件

6.1.3.3 右外联结
■ 右外联接根据一定的条件把多个表连接到一起,此条件是:ON 子
句中指定的字段相匹配
–右外联接 – 对于右侧而言,条件必须满足
■ 如果条件不满足
– 从指定的一侧获取条目,并对未指定的一侧填入 NULL
总结一句话:右外联结包含右侧

6.1.3.4 左外联结
■ 左外联接根据一定的条件把多个表连接到一起,此条件是:ON 子
句中指定的字段相匹配
–左外联接 – 对于左侧而言,条件必须满足
■ 如果条件不满足
–从指定的一侧获取条目,并对未指定的一侧填入 NULL
总结一句话:左外连接包含左侧

6.1.3.5 全外联结
■ 将匹配满足匹配条件的列上的记录
■ 如果条件不满足
–条件不满足的一侧将填入 NULL
–条件满足的一侧将被复制
–对两侧重复上面的操作
总结一句话:全外联结兼容并包

7. 数据并发性
7.1 事务
– 一项或多项 SQL 操作的序列,组织到一起成为一个单元,它
发生于一次原子行动中
– 也被称为一个工作单元
■ 在对数据库采取一次事务处理之后,其结果可以成为永久性的(提 交),也可以被退回(回滚) –手工提交:使用 COMMIT(提交)或 ROLLBACK(回滚)语
句–自动提交:数据库管理器在每次执行 SQL 语句之后进行一次
提交操作
■ 事务的起始和终止定义了数据与数据库之间的数据一致性点
–已提交的数据与未提交的数据
7.2 并发性
■ 并发性
–由多名交互用户或多项应用程序同时共享资源
■ 当存在多名交互用户时,可能会导致:
–丢失更新
–未提交读
–不可重复读
–幻影读
■ 需要能够控制并发性的程度:
–具有适当的数据稳定性
–不会损失性能
7.2.1 并发性问题:丢失更新
–发生在两项事务分别读取,然后又企图更新相同的数据之
时,此时,第二次更新将会在第一次更新被提交之前覆盖它
例如:
- 两项应用程序 A 和 B 读取相同的一行,并根据所读取的数
据为某一列计算新值 - 应用 A 更新了这行
- 然后应用 B 也更新了该行
- 应用 A 的更新丢失了
7.2.2 并发性问题:未提交读(脏读)
■ 未提交读
–发生在事务处理期间读取未提交的数据的时候
–也被称为 “脏读
例如:
- 应用 A 更新了某个值
- 应用 B 在该值被提交之前读取了该值
- 3)应用 A更新被退回
- 由应用 B 进行的计算是以未提交的数据为基础的
7.2.3 并发性问题:不可重复读
■ 不可重复读
–发生在某事务两次读取同一行数据,但每次读取返回不同的
数据值
例如:
- 应用 A 在处理其他请求之前读取了某一行
- 应用 B 修改了或者删除了该行并提交了该变更
- 应用 A 试图再次读取该原始行
- 应用 A 看到已经被修改的行,或者发现原始行已经被删
除了
7.2.3 并发性问题:幻影读
■ 幻影读
–发生在某次事务处理期间,根据某些标准进行检索时,在连
续检索之后返回了额外的行
- 应用 A 执行一次查询,它根据某些检索标准读取某些行
- 应用 B 插入了新数据,这些数据也满足应用 A 的查询标
准 - 应用 A 在同一个工作单元内再次执行其查询,结果返回了
某些额外的幻影值
7.3 并发控制:隔离级别
■ 隔离级别
–决定在访问数据期间,如何锁定数据或者如何与其他同时执
行的进程相隔离
–在事务被处理期间生效
■ DB2 中规定了四种隔离级别:
–可重复读
–读稳定性
–游标稳定性
• 当前已提交
–未提交读
7.4 实施隔离级别:锁
■ 共享锁 (S)
–并发事务仅限于只读操作
■ 更新锁 (U)
–并发事务仅限于只读操作
–如果这些事务未声明它们可能更新某一行,数据库管理器则
假设目前正在查看该行的事务可能会更新它
■ 排他锁 (X)
–阻止并发事务以任何方式访问该数据
–不适应于 UR 隔离级别的事务
■ 数据库管理器对每一个被插入、更新或删除的行加排他锁
7.5 几个隔离级别
7.5.1 可重复读——最高的隔离级别
■ 最高的隔离级别
–不会发生脏读、不可重复读或者幻影读
■ 锁定正在被某项查询扫描的整个表或视图
–提供最低并发性
■ 什么时候使用“可重复读” : –对结果集合的更改是不可接受的
–数据稳定性比性能更重要
7.5.2 读稳定性
■ 与可重复读类似,但没有那么严格
–不会发生脏读或不可重复读
–可能发生幻影读
■ 仅锁定表中或视图中被检索的或被修改的行
■ 什么时候使用“读稳定性” : –应用需要在并发环境中操作
–在工作单元的期间内,限定行 (qualifying row) 必须保持稳定
–在工作单元的期间内,只能发出唯一查询
• 如果在工作单元的期间内发出一次以上同样的查询,不应当
要求相同的结果集合
7.5.3 游标稳定性——默认的隔离级别
■ 默认的隔离级别
–不会发生脏读
–可能发生不可重复读以及幻影读
■ 仅锁定当前正在被游标引用的行
■ 什么时候使用“游标稳定性”: –期望获得最大的并发性,同时仅需要看到已提交的数据
游标稳定性隔离级别能够在游标处于某一行时锁定事务处理期间对该行的访问。该锁定在抓取下一行之前或在该事务终止之前将一直保持有效。但是,如果该行中的任何数据被修改,该锁将一直保持到此修改被提交为止。
当前已提交是游标稳定性的变异
–避免超时和死锁
–基于日志的:
• 无管理开销

7.5 4 未提交读——最低的隔离等级
■ 最低的隔离等级
–可能发生脏读、不可重复读以及幻影读
■ 仅锁定在涉及 DROP 或 ALTER TABLE 的事务中被修改的行
–提供最大的并发性
■ 什么时候使用未提交读:
–查询只读表 –仅使用 SELECT 语句
–允许检索未提交的数据
7.5.6 小结

7.6 实验场景模拟
7.6.1 带有“当前已提交”的“游标稳定性”
7.6.1.1 “前” 场景:关闭“当前已提交”
(1)关闭“当前已提交”
db2 get db cfg for sample
-- cur_commit的值修改为 DISABLED(禁用)
db2 update db cfg for sample using cur_commit disabled
(2)在终端A中执行写查询
首先需要禁用“自动提交”(autocommit) 功能
--键入下面的命令,进入 CLP 提示符。“+c” 选项将对此会话禁用“自动提交”功能
db2 +c
--通过执行下面的命令,你可以查看“自动提交”功能是否已经关闭。
list command options
--在终端A执行更新查询,把所有的值都修改为20
update tb1 set column1 = 20
(3)在终端B进行一条查询
--time 命令能够让我们量化等待时间。
time db2 "select * from tb1"
我们可以看到,该查询处于等待状
态,没有返回任何结果。实际上,它被终端 A 的查询封锁了。
(4)终端A commit之后即解锁
7.6.1.2 “后” 场景:启用“当前已提交”
(1)在终端 A 中,我们使用下面的命令开启“当前已提交”:
update db cfg for sample using cur_commit on
(2)修改该值之后,我们需要断开数据库连接,以便让新值生效。在终端 A中,执行:
connect reset
(3)在终端 B 中,执行:
db2 connect reset
(4)在终端A进行更新查询
(5)在终端B中进行读查询
查询立即返回,因为没有封锁对数据的访问。此外,还应注意到,所返回的值不是最近更新的值,因为我们还没有提交该更新
(6)A commit
(7)B 执行上一步同样的查询
这次返回的值反映了终端 A 中的事务结束而且变更内容被提交给
数据库以来所做的最新更新。
(8)终止A
(9)终止B
7.6.2 可重复读
"幻影读”场景:可重复读
(1)我们需要把终端 A 中当前 CLP 会话的隔离级别修改为“可重复读”。
这必须在接入数据库之前完为。
--此句必须是在CLP会话中执行(即db2=>)
change isolation to RR
(2)终端A:连接数据库并进行一次快速查询
(3)终端B:试图插图一条数据,在刚刚被A读取的表中
db2 connect to sample
db2 "insert into tb1 values (30)"
我们可以看到此操作处于等待状态,没有返回任何结果。实际上,它被终端A 的查询锁定了
(4)A commit之后 B立即执行成功
(5)中断A B的数据库连接
7.6.3 读稳定性
“幻影读”场景:读稳定性
(1)把终端 A 中当前 CLP 会话的隔离级别修改为“读稳定性”。
这必须在接入数据库之前完为。
change isolation to RS
(2)终端A连接数据库并做一次快速查询
(3)终端B插入一些数据
该查询未等待终端 A 提交,而是为功把数据插入 tb1
(4)在终端A中再查询一次(同样的语句)
比第一次查询查出来的数据要多,这是因为“读稳定性”隔离级
别不阻止幻影行的出现。出现了幻影读现象
(5)A commit A B 中断数据库连接
7.6.4 未提交读
“未提交读”场景:游标稳定性
(1)把终端 A 中当前 CLP 会话的隔离级别修改为“可重复读”。这必须在接入数据库之前完成。
change isolation to RR
(2)连接数据库并进行一次快速查询更新
update tb1 set column1 = 40
(3)在终端B中进行读查询
利用 CS(游标稳定性),终端 B 将试图读取被终端 A 锁定的数据
此查询操作在读取数据之前一直在等待终端 A 提交
(4)解锁之后即可查询成功
“未提交读”场景:未提交读
(1)在终端A中进行一次快速查询更新
update tb1 set column1 = 50
(2)在终端B中进行读查询
db2 change isolation to UR
db2 connect to sample
db2 "select * from tb1"
在“未提交读”隔离级别中,该查询操作在读取数据之前并未等待终端 A 提交。相反,所返回的值来自终端 A 中未提交的事务。
如果终端 A 中的事务执行了一次回滚,则终端 B 中所列出的数据不反映TB1 中的实际数据。此现象被称为**“脏读”**。