(1999,非线性映射)使用核进行 Fisher 判别式分析
Fisher discriminant analysis with kernels
公众号:EDPJ
目录
0. 摘要
1. 判别式分析(Discriminant Analysis)
2. Fisher 的线性判别式
3. 特征空间中的 Fisher 判别式
4. 实验
5. 讨论和结论
参考
S. 总结
S.1 主要思想
S.2 方法
0. 摘要
提出了一种基于 Fisher 判别式的非线性分类技术。 主要成分是内核技巧,它允许在特征空间中高效计算 Fisher 判别式。 特征空间中的线性分类对应于输入空间中的(强大的)非线性决策函数。 大规模模拟证明了我们方法的竞争力。
1. 判别式分析(Discriminant Analysis)
在分类和其他数据分析任务中,通常需要在应用手头的算法之前对数据进行预处理,并且通常首先提取适合待解决任务的特征。
用于分类的特征提取与用于描述数据的特征提取有很大不同。 例如,PCA 通过使用 m 个正交方向描述尽可能多的数据方差来找到具有最小重建误差的方向。 他们考虑第一个方向,不需要(实际上通常不会)揭示我们正确分类所需的类结构。 判别分析解决以下问题:给定一个包含两个类的数据集,比如说,哪个是区分这两个类的最佳特征或特征集(线性或非线性)? 经典方法解决这个问题通过使用(理论上)最佳贝叶斯分类器(假设类的正态分布)和标准算法(如二次或线性判别分析),它们包括著名的 Fisher 判别。当然,对于类别分布,可以假设任何不同于高斯模型的其他模型,然而,这通常会牺牲简单的闭合形式的解。
在这项工作中,我们建议使用最初应用于支持向量机(SVM)、内核 PCA 和其他基于内核算法的内核思想,来定义非线性 Fisher 判别式的泛化。 我们的方法使用内核特征空间产生高度灵活的算法,结果证明与 SVM 具有竞争力。
请注意,存在多种称为核判别分析的方法。 他们中的大多数旨在用非参数核估计代替类条件分布的参数估计。 即使我们的方法也可能被这样看待,重要的是要注意它通过将内核解释为另一个空间中的点积更进一步。 这允许理论上合理的解释以及吸引人的封闭形式解。
下面我们将首先回顾 Fisher 的判别式,应用内核技巧,然后报告分类结果,最后给出我们的结论。 在本文中,我们将只关注二分类问题和特征空间中的线性判别式。
2. Fisher 的线性判别式
![]()
来自两个不同类别的样本,并且使用符号
![]()

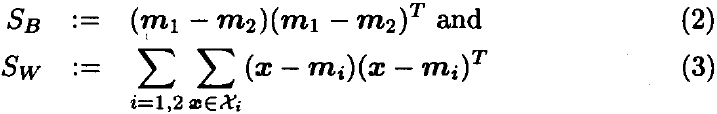
![]()
S_B 和 S_W 分别是类间和类内散点矩阵。最大化 J(w) 背后的直觉是找到最大化投影类别均值(分子)的方向,同时最小化该方向上的类别方差(分母)。 但是还有一个众所周知的统计方法来激发等式(1):
联系最优线性贝叶斯分类器:最优贝叶斯分类器比较所有类的后验概率,并为具有最大概率的类别分配一个图样。 然而,后验概率通常是未知的,必须从有限样本中估计。 对于大多数类别的分布来说,这是一项艰巨的任务,而且通常不可能获得封闭形式的估计。 然而,通过假设所有类都服从正态分布,可以得出二次判别分析(其本质上是测量一个模式到类中心的马氏距离)。 进一步简化问题并假设所有类别的协方差结构相同,二次判别分析变为线性。 对于二分类问题,很容易证明最大化等式(1)的向量 w 与相应贝叶斯最优分类器中的判别式方向相同。尽管依赖于在许多应用中并不真实的强假设,但 Fisher 的线性判别已被证明非常强大。 一个原因当然是线性模型对噪声相当稳健并且很可能不会过拟合。 然而,至关重要的是散点矩阵的估计,它可能存在很大偏差。 当样本数量与维度相比较小时,使用等式(2)中的简单 “插件” 估计,将导致高可变性。 已经提出了通过正则化来处理这种情况的不同方法,我们稍后会回到这个主题。
3. 特征空间中的 Fisher 判别式
显然,对于大多数真实世界的数据,线性判别式不够复杂。 为了增加判别式的表现力,我们可以尝试使用更复杂的分布来为最佳贝叶斯分类器建模,或者寻找非线性方向(或两者)。 如前所述,假设一般分布会引起麻烦。 在这里,我们通过首先将数据非线性映射到某个特征空间 F,并在那里计算 Fisher 线性判别式来限制我们寻找非线性方向,从而隐含地在输入空间中产生非线性判别式。
设 Φ 是到某个特征空间 F 的非线性映射。为了找到 F 中的线性判别式,我们需要最大化

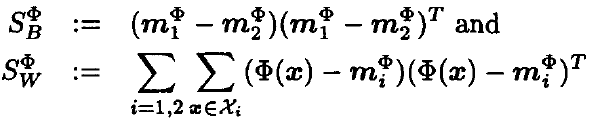
![]()
其中,ω ∈ F,S^Φ_B 和 S^Φ_W 是 F 中相应的矩阵。
引入核函数:显然,如果 F 的维数非常高,甚至是无限维,则无法直接求解。 为了克服这个限制,我们使用了与内核 PCA 或支持向量机中相同的技巧。 我们没有明确地映射数据,而是寻求一种仅使用训练图样点积 (Φ(x) · Φ(y)) 的算法。 由于我们随后能够有效地计算这些点积,因此我们无需显式映射到 F 即可解决原始问题。这可以使用 Mercer 内核来实现:这些内核 k(x, y) 计算一些特征空间 F 中的点积,即 k(x,y) = (Φ(x) · Φ(y)) 。k 的可能选择已被证明有用,例如,在支持向量机或内核 PCA 中是高斯 RBF
![]()
或多项式内核,k(x, y) = (x · y)^d,c 和 d 是正的常数 。
为了在特征空间 F 中找到 Fisher 判别式,我们首先需要根据输入图样的点积来公式化等式 (4),然后我们将其替换为某个核函数。 从复现核理论我们知道任何解决方案 ω ∈ F 必须位于 F 中所有训练样本的范围内。因此我们可以找到 w 的展开形式:

使用展开式 (5) 和 m^Φ_i 的定义,则有
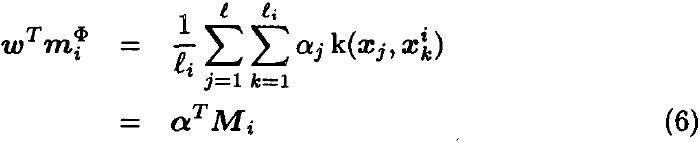
![]()
现在考虑等式(4)的分子。 使用 S^Φ_B 和等式 (6) 的定义可将其重写为
![]()
![]()
考虑等式(4)的分母,则有
![]()
![]()
![]()
![]()
![]()
I 是单位阵(Identity)。
结合等式 (7) 和 (8),我们可以通过最大化等式(9)找到 F 中的 Fisher 线性判别式

这个问题可以通过找到 (N^(-1))M 的主要特征向量来解决(类似于输入空间中的算法)。 我们将这种方法称为(非线性)Kernel Fisher Discriminant (KFD)。 新图样 x 到 w 的投影由下式给出
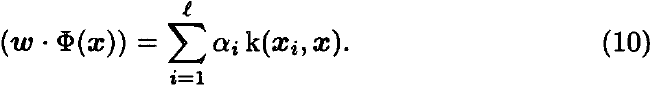
数值问题和正则化:显然,所提出的设置是病态的:我们正在从 t 个样本中估计 L 维协方差结构。 除了导致矩阵 N 不是正数的数值问题外,我们还需要在 F 中进行容量控制。为此,我们只需将单位阵的倍数添加到 N 即可,即,将 N 替换为
![]()
这可以用不同的方式来看待:(i)它显然使问题在数值上更稳定,因为 p 足够大时,N_μ 将变为正定的; (ii) 它可以减少基于样本的特征值估计中的偏差; (iii) 它对 ||α||^2 施加正则化(记住我们正在最大化等式 (9)),有利于使用小展开系数的解决方案。 虽然这种正则化设置的真正影响尚未完全了解,但它显示了与支持向量机中使用的那些的联系。 此外,人们可能会对 N 使用其他正则化类型的添加,例如,类似于 SVM 惩罚 ||ω||^2 (通过添加完整的内核矩阵 K_ij = k(x_i, x_j))。
4. 实验
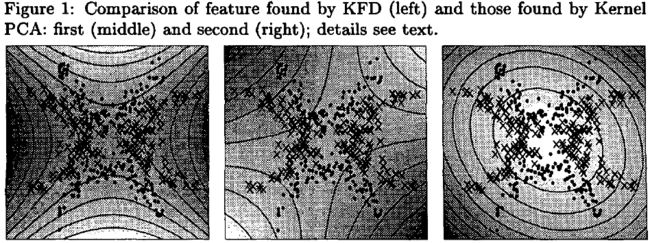
图 1 显示了在玩具数据集上 KFD 发现的特征与 Kernel PCA 发现的第一个和第二个(非线性)特征的比较。 对于两者,使用二阶多项式核,对于 KFD,正则化类内散点图,其中 μ = 10^(-3)。描述了两个类(十字和点)、特征值(由灰度级表示)和相同特征的等高线。 每个类别都包含两个分别在 x 轴和 y 轴镜像的嘈杂抛物线形状。 我们看到,KFD 特征以近乎最佳的方式区分这两个类,而 Kernel PCA 特征虽然描述了数据集的有趣属性,但并没有很好地区分这两个类(尽管更高阶的 Kernel PCA 特征可能具有区分性, 也)。
为了评估我们新方法的性能,我们与其他最先进的分类器进行了广泛的比较。我们将 Kernel Fisher 判别式与 AdaBoost、正则化 AdaBoost 和支持向量机(具有高斯核)进行了比较。 对于 KFD,我们也使用了高斯核,正则化类内散点。 在找到最佳方向 ω ∈ F 后,我们使用等式 (10) 计算了它的投影。 为了估计提取特征的最佳阈值,可以使用任何分类技术,例如,就像拟合 sigmoid 一样简单。 这里我们使用了线性 SVM(通过梯度下降优化,因为我们只有 1 维样本)。 然而,这样做的一个缺点是我们要控制另一个参数,即 SVM 中的正则化常数。
我们使用来自 UCI、DELVE 和 STATLOG 基准存储库的 13 个人工和真实世界的数据集(香蕉除外)。非二元问题被划分为两类问题。 然后生成 100 个分区到测试和训练集(大约 60%:40%)。 在这些数据集的每一个上,我们训练和测试了所有分类器。 表 1 中的结果显示了这 100 次运行的平均测试误差和标准偏差。 为了估计必要的参数,我们对训练集的前五个实现进行了 5 折交叉验证,并将模型参数作为五个估计值的中值。

此外,我们在 USPS 手写数字数据集上使用 KFD 进行了初步实验,我们将等式 (5) 中 w 的展开限制为仅在前 3000 个训练样本上运行。 我们使用宽度为 0.3 x 256 的高斯核实现了 3.7% 的 10 类别误差,这略优于具有高斯核的 SVM (4.2%)。
实验结果:实验表明,Kernel Fisher 判别法(加上用于估计阈值的支持向量机)在几乎所有数据集(图像除外)上都具有竞争力,或者在某些情况下甚至优于其他算法。 有趣的是,SVM 和 KFD 都在 F 中构造了一个(在某种意义上)最优超平面,而我们注意到 KFD 的解 w 给出的超平面通常优于 SVM 的解。
5. 讨论和结论
Fisher 判别式是统计数据分析中的标准线性技术之一。 然而,线性方法通常过于有限,过去有几种方法可以推导出更通用的类别可分离性标准。 我们的方法非常符合这种精神,但是,由于我们在某些特征空间 F(与输入空间非线性相关)中计算判别函数,我们仍然能够找到封闭形式的解并保持 Fisher 判别分析的理论之美。 此外,由于可能的非线性范围很广,不同的内核允许高度的灵活性。
我们的实验表明,KFD 与其他最先进的分类技术相比具有竞争力。 此外,由于线性判别分析是一个深入研究的领域,并且以前在输入空间中开发的许多想法都可以转移到特征空间,因此仍有很大的扩展空间和进一步的理论。
请注意,虽然 SVM 的复杂性与支持向量的数量成比例,但 KFD 没有 SV 的概念,其复杂性与训练图样的数量成比例。 另一方面,我们推测,KFD 优于 SVM 的某些性能可能与以下事实有关,即 KFD 在解决方案中使用所有训练样本,而不仅仅是困难的样本,即,Support Vectors。
未来的工作将致力于寻找合适的近似方案和数值算法来获得大型矩阵的主要特征向量。 进一步的研究领域将包括多类别判别式的构建、KFD 泛化误差界的理论分析以及 KFD 与支持向量机之间联系的调查。
参考
Mika S, Ratsch G, Weston J, et al. Fisher discriminant analysis with kernels[C]//Neural networks for signal processing IX: Proceedings of the 1999 IEEE signal processing society workshop (cat. no. 98th8468). Ieee, 1999: 41-48.
S. 总结
S.1 主要思想
对于大多数真实世界的数据分类,线性判别不够复杂。 为了增加判别的表现力,可以使用更复杂的分布来为最佳贝叶斯分类器建模,或者寻找非线性方向(或两者)。
线性模型对噪声相当稳健并且很可能不会过拟合,但至关重要的散点矩阵的估计可能存在很大偏差,尤其是当样本数量与维度相比较小时。
S.2 方法
首先将数据非线性映射到某个特征空间 F,并在那里计算 Fisher 线性判别式来寻找非线性方向,从而隐含地在输入空间中产生非线性判别式。
作者没有明确地映射数据,而是寻求一种仅使用训练图样(pattern)点积 (Φ(x) · Φ(y)) 的算法,Φ 是到某个特征空间 F 的非线性映射。 由于能够有效地计算这些点积,因此无需显式映射到 F 即可解决原始问题。这可以使用 Mercer 内核来实现:这些内核 k(x, y) 计算一些特征空间 F 中的点积,即 k(x,y) = (Φ(x) · Φ(y)) 。
核函数 k,例如,在支持向量机或内核 PCA 中是高斯 RBF
![]()
或多项式内核,k(x, y) = (x · y)^d,c 和 d 是正的常数 。