2.为什么选择RocketMQ?
1.Windows安装&启动
https://www.jianshu.com/p/4a275e779afa
1.修改配置文件
1)runbroker.sh
vi /usr/local/rocketmq/bin/runbroker.sh
需要根据内存大小进行适当的对JVM参数进行调整:
```
===================================================
开发环境配置 JVM Configuration
JAVAOPT="${JAVAOPT} -server -Xms256m -Xmx256m -Xmn128m" ```
```
修改磁盘是100了才报机器内存不足
set "JAVAOPT=%${JAVAOPT}% -Drocketmq.broker.diskSpaceWarningLevelRatio=1.0" ```
2)runserver.sh
vim /usr/local/rocketmq/bin/runserver.sh
JAVA_OPT="${JAVA_OPT} -server -Xms256m -Xmx256m -Xmn128m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=320m"
broker-a.properties
使用这个配置文件存储目录在bin目录下的store
```
所属集群名字
brokerClusterName=rocketmq-cluster
broker名字,注意此处不同的配置文件填写的不一样
brokerName=broker-a
0 表示 Master,>0 表示 Slave
brokerId=0
nameServer地址,分号分割 host文件中的域名
namesrvAddr=127.0.0.1:9876
在发送消息时,自动创建服务器不存在的topic,默认创建的队列数
defaultTopicQueueNums=4
是否允许 Broker 自动创建Topic,建议线下开启,线上关闭
autoCreateTopicEnable=true
是否允许 Broker 自动创建订阅组,建议线下开启,线上关闭
autoCreateSubscriptionGroup=true
Broker 对外服务的监听端口 同一台机器的端口号要保证不一样
listenPort=10911
删除文件时间点,默认凌晨 4点
deleteWhen=04
文件保留时间,默认 48 小时
fileReservedTime=120
commitLog每个文件的大小默认1G
mapedFileSizeCommitLog=100000
ConsumeQueue每个文件默认存30W条,根据业务情况调整
mapedFileSizeConsumeQueue=300000
destroyMapedFileIntervalForcibly=120000
redeleteHangedFileInterval=120000
检测物理文件磁盘空间
diskMaxUsedSpaceRatio=100
存储路径
storePathRootDir=D:\store
commitLog 存储路径
storePathCommitLog=D:\store\commitlog
消费队列存储路径存储路径
storePathConsumeQueue=D:\store\consumequeue
消息索引存储路径
storePathIndex=D:\store\index
checkpoint 文件存储路径
storeCheckpoint=D:\store\checkpoint
abort 文件存储路径
abortFile=D:\store\abort
限制的消息大小
maxMessageSize=65536
flushCommitLogLeastPages=4
flushConsumeQueueLeastPages=2
flushCommitLogThoroughInterval=10000
flushConsumeQueueThoroughInterval=60000
Broker 的角色
- ASYNC_MASTER 异步复制Master
- SYNC_MASTER 同步双写Master
- SLAVE
brokerRole=SYNC_MASTER
刷盘方式
- ASYNC_FLUSH 异步刷盘
- SYNC_FLUSH 同步刷盘
flushDiskType=SYNC_FLUSH
checkTransactionMessageEnable=false
发消息线程池数量
sendMessageThreadPoolNums=128
拉消息线程池数量
pullMessageThreadPoolNums=128
```
2.启动命令
在当前目录下rocketmq-all-4.3.0-bin-release下执行以下命令
start mqnamesrv.cmd
start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true 测试使用这个命令 指定配置文件启动 start mqbroker.cmd -n 127.0.0.1:9876 autoCreateTopicEnable=true -c broker-a.properties
在runborker.cmd增加以下配置:意思是磁盘的使用空间达到百分之99才会做拒绝写入并预警
set "JAVA_OPT=%JAVA_OPT% -Drocketmq.broker.diskSpaceWarningLevelRatio=0.99"
3.手动创建topic
注意是使用cmd 窗口打开
```
mqadmin updateTopic -b localhost:10911 -t tyrantor
tyrantor是topic名称 默认是创建读写队列各8个
TopicConfig [topicName=tyrantor, readQueueNums=8, writeQueueNums=8, perm=RW-, topicFilterType=SINGLE_TAG, topicSysFlag=0, order=false]
mqadmin updateTopic -b localhost:10911 -t tyrant
不行可以试试这个
./mqadmin updateTopic -b localhost:10911 -t tyrant ```
4.Docker安装运行
https://blog.csdn.net/fenglibing/article/details/92378090
2.为什么要用MQ
消息队列是一种“先进先出”的数据结构
其应用场景主要包含以下3个方面
应用解耦,降低系统之间的强依赖
系统的耦合性越高,容错性就越低。
一次性调用3个接口,如果一个接口有异常,则本次请求就异常了。
3个接口有一个失败了其余2个应该回滚或者失败的这个要做补偿。
以电商应用为例,用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障或者因为升级等原因暂时不可用,都会造成下单操作异常,影响用户使用体验。
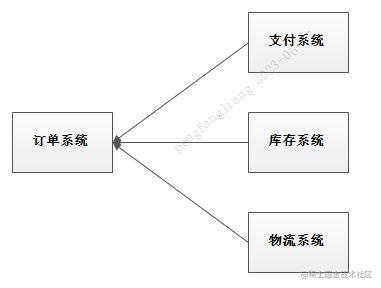
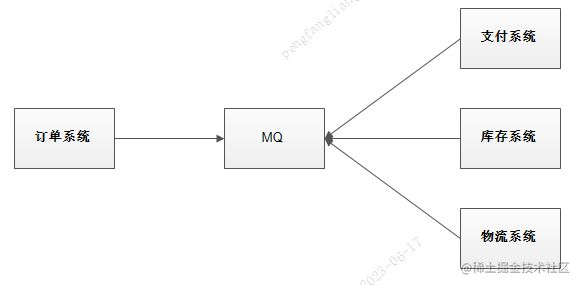
使用消息队列解耦合,系统的耦合性就会提高了。
比如物流系统发生故障,需要几分钟才能来修复,在这段时间内,物流系统要处理的数据被缓存到消息队列中,用户的下单操作正常完成。
当物流系统回复后,补充处理存在消息队列中的订单消息即可,终端系统感知不到物流系统发生过几分钟故障。
流量削峰,削峰填谷。
应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。

一般情况,为了保证系统的稳定性,如果系统负载超过阈值,就会阻止用户请求,这会影响用户体验,而如果使用消息队列将请求缓存起来,等待系统处理完毕后通知用户下单完毕,这样总不能下单体验要好。
为了业务数据直接打到数据库我把数据先存在Mq,然后消费端每次insert到数据库再通过定时器拉取这样可以吗?
处于经济考量目的:
业务系统正常时段的QPS如果是1000,流量最高峰是10000,为了应对流量高峰配置高性能的服务器显然不划算,这时可以使用消息队列对峰值流量削峰
数据分发,降低耦合度
原来是需要A系统分别调用B C D 系统。现在如果新增E那么需要修改代码,需要在A系统调用E系统
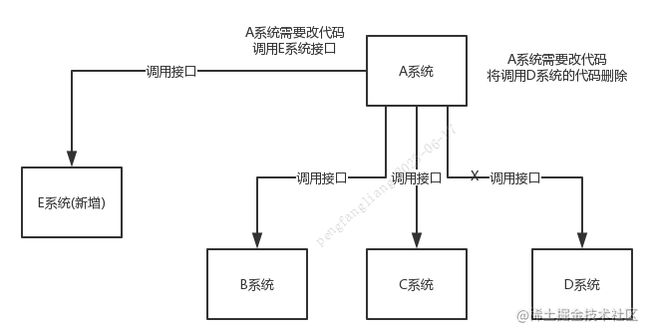
通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可
异步调用,提高响应时间
不需要同步执行的远程调用可以有效提高响应时间
总结
```md 1.解耦:系统耦合度降低,没有强依赖关系
2.异步:不需要同步执行的远程调用可以有效提高响应时间
3.削峰:请求达到峰值后,后端service还可以保持固定消费速率消费,不会被压垮
4.数据分发:通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可 ```
MQ的优点和缺点
优点:解耦、削峰、数据分发
缺点包含以下几点:
系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。
如何保证MQ的高可用?
系统复杂度提高
MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。
如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
一致性问题
A系统处理完业务,通过MQ给B、C、D三个系统发消息数据,如果B系统、C系统处理成功,D系统处理失败。
如何保证消息数据处理的一致性?
重试 + 幂等
3.各种MQ产品的比较
常见的MQ产品包括Kafka、ActiveMQ、RabbitMQ、RocketMQ。
RabbitMQ
RabbitMQ 对消息堆积的支持并不好,在它的设计理念里面,消息队列是一个管道,大量的消息积压是一种不正常的情况,应当尽量去避免。
消息积压,性能下降
当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。
性能差
RabbitMQ 的性能是我们介绍的这几个消息队列中最差的,根据官方给出的测试数据综合我们日常使用的经验,依据硬件配置的不同,它大概每秒钟可以处理几万到十几万条消息。
编程语言 Erlang
RabbitMQ 使用的编程语言 Erlang,这个编程语言不仅是非常小众的语言,如果你想基于 RabbitMQ 做一些扩展和二次开发什么的,建议你慎重考虑一下可持续维护的问题。
容量受限
rabbitMq有两种集群模式:1、一台存全部数据,另外几台存元数据(数据存储服务器ip)2、所有服务器存储全部数据。rabbitmq不分主从,所有节点都是等价的。造成的问题是所有服务器存储全部数据对服务器磁盘有压力。
rabbitmq只是集群高可用 没有分布式存储,因为集群中每台机器存储的数据量是一样的只能垂直的扩展没能水平扩展,kafka和rocketmq都是讲消费拆分后存储到不同的消息然后每个消息对应一个主节点 其他机器存储副本
集群扩展麻烦
RocketMQ
消息零丢失
集群扩展方便
RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。
RocketMQ 的性能比 RabbitMQ 要高一个数量级,每秒钟大概能处理几十万条消息。
RocketMQ 有非常活跃的中文社区,大多数问题你都可以找到中文的答案,也许会成为你 选择它的一个原因。
Java语言开发,方便二次扩展
另外,RocketMQ 使用 Java 语言开发,它的贡献者大多数都是中国 人,源代码相对也比较容易读懂,你很容易对 RocketMQ 进行扩展或者二次开发。
Kafka
Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所 有的相关开源软件系统都会优先支持Kafka。
Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。
Kafka 的性能,尤其是异步收发的性能,是三者中最好的,但与 RocketMQ 并没有量级上的差异,大约每秒钟可以处理几十万条消息。
我曾经使用配置比较好的服务器对 Kafka 进行过压测,在有足够的客户端并发进行异步批 量发送,并且开启压缩的情况下,Kafka 的极限处理能力可以超过每秒 2000 万条消息。
延迟较高,不适合在线业务
但是 Kafka 这种异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因 为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发 送,在它的 Broker 中,很多地方都会使用这种“先攒一波再一起处理”的设计。
当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka的时延反而会比较高。所以,Kafka 不太适合在线业务场景。 主要用于日志传输大数据等方面