dom4j解析 mybatis config XML文件
pom.xml
4.0.0
com.wsd
parse-xml
1.0-SNAPSHOT
org.dom4j
dom4j
2.1.3
jaxen
jaxen
1.2.0
junit
junit
4.13.2
test
org.apache.maven.plugins
maven-compiler-plugin
3.1
17
17
dom4j是一个开源的Java XML解析库,它的主要作用是用于处理和操作XML文档。
以下是dom4j的一些主要作用和特性:
1. 解析和读取XML文档:dom4j提供了一个简单而强大的API,使得解析和读取XML文档变得容易。它可以将XML文档转换为类似于树形结构的对象模型,开发者可以通过该对象模型轻松地获取和操作XML文档中的元素、属性和文本内容。
2. 查询和筛选XML元素:dom4j支持使用XPath和自定义的查询方式来查询和筛选XML文档中的特定元素。开发者可以使用XPath表达式或者编程方式来根据条件筛选所需的XML元素,从而方便地进行数据的提取和操作。
3. 创建和生成XML文档:dom4j提供了创建和生成XML文档的功能。开发者可以使用dom4j的API来动态地构建XML文档结构,添加元素、属性和文本内容,并将最终的XML文档保存到文件或输出流中。
4. 支持XML文档的验证和验证:dom4j提供了验证XML文档的功能,可以通过指定DTD或XML Schema进行验证。这有助于确保所处理的XML文档符合预期的结构和规范。
5. 高性能和低内存占用:dom4j被设计为高性能和低内存占用的XML解析库。它使用了一些优化技术,如基于事件的解析模型,以提高解析性能和降低内存使用。
总的来说,dom4j是一个功能强大且易于使用的XML解析库,可以帮助开发者轻松地处理和操作XML文档,包括解析、读取、查询、创建和生成XML文档,以及验证等功能。它在Java开发中被广泛应用于处理和操作XML数据。
Jaxen是一个用于XPath查询的开源Java库,它的主要作用是提供一种简单而强大的方式来在XML文档中进行查询和筛选。
以下是Jaxen的一些主要作用和特性:
1. XPath查询:Jaxen实现了XPath标准,使得开发者可以使用XPath表达式在XML文档中定位和筛选特定的元素、属性或文本节点。XPath是一种基于路径表达式的查询语言,使用它可以非常灵活地定位和筛选XML文档中的数据。
2. 符合标准:Jaxen严格遵循XPath标准,并提供了一致的API和语法规则。开发者可以依赖Jaxen来执行各种XPath查询操作,而不需要关注不同XML解析库之间的差异和特性。
3. 跨平台支持:Jaxen是一个跨平台的Java库,可以在各种Java环境下使用,包括标准的Java SE、Java EE和Android等。这使得开发者可以在不同的平台和应用中灵活地使用Jaxen进行XPath查询。
4. 支持多种XML解析器:Jaxen提供了对多种XML解析器的支持,包括DOM、JDOM、dom4j和XPath的内置实现。开发者可以根据自己的需求和项目环境选择适合的XML解析器,而无需修改或适配现有的XPath查询代码。
5. 高性能和可扩展:Jaxen被设计为高性能和可扩展的XPath查询库。它使用了一些优化技术和算法,以提高查询性能,并提供了一些扩展点和API,以便开发者可以根据需要自定义和扩展Jaxen的功能。
综上所述,Jaxen是一个用于XPath查询的Java库,它提供了一种简单和强大的方式来在XML文档中进行查询和筛选。它的主要作用是帮助开发者方便地执行XPath查询,并从XML文档中获取所需的数据。Jaxen在Java开发中被广泛应用于处理和操作XML数据。
config.xml
CarMapper.xml
insert into t_car
(id,car_num,brand,guide_price,produce_time,car_type)
values
(null,#{carNum},#{brand},#{guidePrice},#{produceTime},#{carType})
test01:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
}
catch ( DocumentException e){
e.printStackTrace();
}
System.out.println( document );
}
}
在dom4j库中,SAXReader类是一个用于解析XML文档的工具类。它提供了多个读取和解析XML文档的方法,其中包括了`read(InputStream)`方法。
`read(InputStream)`方法用于从给定的输入流中读取并解析XML文档。下面是对这个方法的解析介绍:
方法签名:
public Document read(InputStream inputStream) throws DocumentException
参数:
- `inputStream`:要读取的XML文档的输入流。返回值:
- 解析后得到的Document对象,表示整个XML文档的根节点。异常:
- `DocumentException`:如果解析XML文档时发生了错误。方法功能:
- `read(InputStream)`方法通过使用SAX解析器,从输入流中读取XML文档的内容,并将其解析为一个dom4j的Document对象。
- SAX解析器是一种基于事件驱动的解析器,它在解析过程中逐行读取并处理XML数据,而不是将整个XML文档加载到内存中。解析过程:
1. `read(InputStream)`方法会创建一个SAX解析器对象,并设置解析器的配置选项。
2. 解析器会逐行读取输入流中的XML文档数据。
3. 当解析器读取到XML文档的各个节点(例如元素、属性、文本等)时,会触发相应的事件。
4. 解析器根据事件类型,通过回调方法将解析到的节点信息传递给SAXReader对象。
5. SAXReader对象将解析到的节点信息构建为一个dom4j的Document对象,并返回解析结果。使用示例:
```java
// 创建SAXReader对象
SAXReader reader = new SAXReader();// 从输入流中读取并解析XML文档
Document document = reader.read(inputStream);
```总结:
`read(InputStream)`方法通过使用SAX解析器,从输入流中读取并解析XML文档。它返回一个dom4j的Document对象,表示整个XML文档的根节点。这个方法在dom4j中是常用的解析XML文档的方式之一,适用于处理较大的XML文件,因为它可以边读取边解析,避免将整个XML文档加载到内存中。
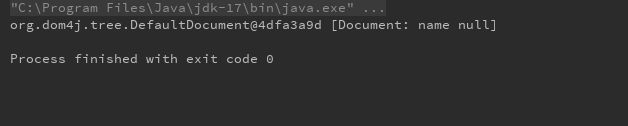
test02:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取根节点
Element rootElement = document.getRootElement();
System.out.println( rootElement );
String name = rootElement.getName();
System.out.println("rootElementName:" + name);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}

test03:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
Node environments = document.selectSingleNode(xpath);
System.out.println(environments);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}

test04:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
System.out.println(def);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}

`document.selectSingleNode()`是dom4j库中用于查询XML文档中单个节点的方法。它根据给定的XPath表达式从XML文档中选择并返回匹配的第一个节点。
下面是一个具体的例子来详细解释`document.selectSingleNode()`方法的使用:
假设我们有一个名为"config.xml"的XML文档,其内容如下:
```xml
Value 1
Value 2
Value 3
```现在我们想通过XPath表达式来选择并获取"element2"节点的值。可以使用以下代码来实现:
```java
SAXReader reader = new SAXReader();
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = reader.read(xmlInputStream);Node node = document.selectSingleNode("/root/element2");
String value = node.getText();System.out.println(value);
```解析过程如下:
1. 创建一个SAXReader对象。
2. 通过资源加载器获取名为"config.xml"的XML文件的输入流。
3. 使用SAXReader的`read()`方法将输入流解析为一个Document对象。
4. 使用`document.selectSingleNode()`方法,传入XPath表达式"/root/element2",来选择匹配的第一个节点。
5. 通过`getText()`方法获取选定节点的文本内容("Value 2")。
6. 将节点的值打印输出。上述代码中,XPath表达式"/root/element2"选择了根节点下的"element2"子节点。由于使用了`selectSingleNode()`方法,它只会返回匹配的第一个节点(如果有多个匹配,只返回第一个)。使用`getText()`方法获取节点的文本内容,最后输出"Value 2"。
总结:
`document.selectSingleNode()`方法通过XPath表达式选择匹配的第一个节点,并返回该节点。你可以使用此方法来从XML文档中选择并获取你感兴趣的节点,进而操作节点的属性、文本内容等信息。XPath表达式 :
XPath(XML Path Language)表达式是一种用于在XML文档中定位、选择和操作节点的语言。它是一种基于树结构的路径表达语言。
XPath表达式可以使用不同的语法形式,但最常见的形式是使用斜杠(/)分隔节点层级的路径。下面是XPath表达式的一些常见使用方式:
- `/`:表示根节点。例如,`/root`表示选择文档的根元素为root的节点。
- `//`:表示从根节点开始的全局搜索。例如,`//element`表示搜索文档中所有名为element的节点。
- `element`:表示选择指定名称的元素节点。例如,`element`表示选择所有名为element的节点。
- `@attribute`:表示选择节点的属性。例如,`@id`表示选择具有id属性的节点。
- `[predicate]`:表示使用谓词进行条件选择。例如,`element[@attr='value']`表示选择具有attr属性且属性值为"value"的element节点。XPath还支持其他功能,如选择子节点、选择父节点、选择兄弟节点、选择前后节点等。它提供了丰富的选择器和操作符,使得在XML文档中选择和定位节点更加灵活和精确。
XPath表达式在许多XML处理库、工具和技术中都得到了广泛应用,包括dom4j、XPath语法、XSLT转换、XQuery等。通过使用XPath表达式,你可以快速而准确地定位和选择XML文档中的节点,以满足你的需求。
test05:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
//environments 下的 id= def 的 environment标签
xpath = "/configuration/environments/environment[@id='" + def + "']";
Element environment = (Element) document.selectSingleNode(xpath);
System.out.println(environment);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}

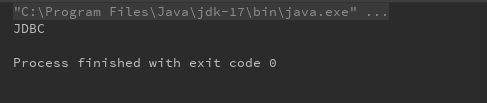
test06:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
//environments 下的 id= def 的 environment标签
xpath = "/configuration/environments/environment[@id='" + def + "']";
Element environment = (Element) document.selectSingleNode(xpath);
// 获取 transactionManager 子节点
Element transactionManager = environment.element("transactionManager");
//获取 type 属性
String transactionManagerType = transactionManager.attributeValue("type");
System.out.println(transactionManagerType);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}
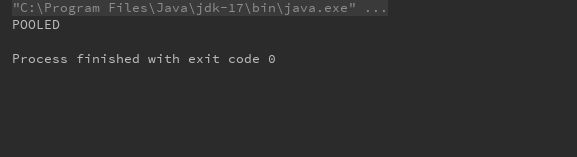
test07:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
//environments 下的 id= def 的 environment标签
xpath = "/configuration/environments/environment[@id='" + def + "']";
Element environment = (Element) document.selectSingleNode(xpath);
// 获取 transactionManager 子节点
Element transactionManager = environment.element("transactionManager");
//获取 type 属性
String transactionManagerType = transactionManager.attributeValue("type");
//获取 dataSource 子节点
Element dataSource = environment.element("dataSource");
//获取 type属性
String dataSourceType = dataSource.attributeValue("type");
System.out.println(dataSourceType);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}
test08:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
//environments 下的 id= def 的 environment标签
xpath = "/configuration/environments/environment[@id='" + def + "']";
Element environment = (Element) document.selectSingleNode(xpath);
// 获取 transactionManager 子节点
Element transactionManager = environment.element("transactionManager");
//获取 type 属性
String transactionManagerType = transactionManager.attributeValue("type");
//获取 dataSource 子节点
Element dataSource = environment.element("dataSource");
//获取 type属性
String dataSourceType = dataSource.attributeValue("type");
//获取 dataSource 下的所有子节点
List dataSourcePropertyElements = dataSource.elements();
//获取 property 标签的属性值
dataSourcePropertyElements.forEach(property -> {
String name = property.attributeValue("name");
String value = property.attributeValue("value");
System.out.println(name + " = " + value);
});
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}
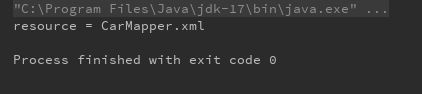
test09:
package com.wsd;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
/**
* @program: spring_learn
* @description:
* @author: Mr.Wang
* @create: 2023-06-20 21:48
**/
public class TestXml {
@Test
public void testParseConfigXml(){
// 创建 SAXReader 对象
SAXReader xReader = new SAXReader();
//获取xml文件的输入流
InputStream xmlInputStream = ClassLoader.getSystemClassLoader().getResourceAsStream("config.xml");
Document document = null;
try{
//利用xml的输入流来解析xml文件,返回Document对象
document = xReader.read(xmlInputStream);
//获取environments 标签
String xpath = "/configuration/environments";
/*selectSingleNode 返回类型为 Node,
将其强转为 Element(Element 是 Node 的子类),为了使用Element更多的方法
*/
Element environments = (Element) document.selectSingleNode(xpath);
//获取属性值
String def = environments.attributeValue("default");
//environments 下的 id= def 的 environment标签
xpath = "/configuration/environments/environment[@id='" + def + "']";
Element environment = (Element) document.selectSingleNode(xpath);
// 获取 transactionManager 子节点
Element transactionManager = environment.element("transactionManager");
//获取 type 属性
String transactionManagerType = transactionManager.attributeValue("type");
//获取 dataSource 子节点
Element dataSource = environment.element("dataSource");
//获取 type属性
String dataSourceType = dataSource.attributeValue("type");
//获取 dataSource 下的所有子节点
List dataSourcePropertyElements = dataSource.elements();
//获取 property 标签的属性值
dataSourcePropertyElements.forEach(property -> {
String name = property.attributeValue("name");
String value = property.attributeValue("value");
//System.out.println(name + " = " + value);
});
//mapper 标签
xpath = "//mapper";
//获取所有mapper标签
List mapperNodes = document.selectNodes(xpath);
//遍历获取mapper的属性
mapperNodes.forEach(
mapper -> {
Element mapperElement = (Element) mapper;
String resource = mapperElement.attributeValue("resource");
System.out.println("resource = " + resource);
}
);
}
catch ( DocumentException e){
e.printStackTrace();
}
}
}