火山引擎 DataLeap:「数据血缘」踩过哪些坑?来看看字节跳动内部进化史
动手点关注
干货不迷路
DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成、开发、运维、治理、资产、安全等全套数据中台建设,降低工作成本和数据维护成本、挖掘数据价值、为企业决策提供数据支撑。数据血缘是帮助用户找数据、理解数据以及使数据发挥价值的基础能力。基于字节跳动内部沉淀的数据治理经验,火山引擎 DataLeap 具备完备的数据血缘能力,本文将从数据血缘应用背景、发展概况、架构演讲以及未来展望四部分,为大家介绍数据血缘在字节跳动进化史。
背景介绍
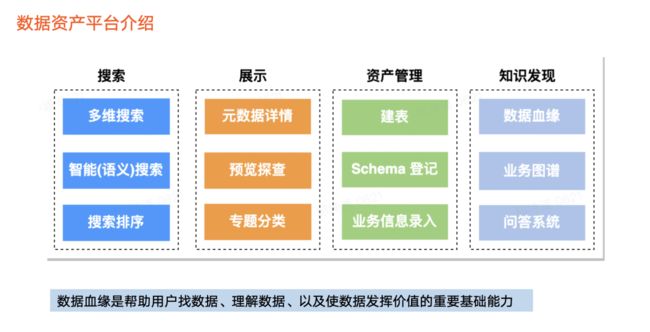
1. 数据血缘是数据资产平台的重要能力之一
在火山引擎 DataLeap 中,数据资产平台主要提供元数据搜索、展示、资产管理以及知识发现能力。在数据资产平台中,数据血缘是帮助用户找数据、理解数据以及使数据发挥价值的重要基础能力。
2. 字节跳动的数据链路情况
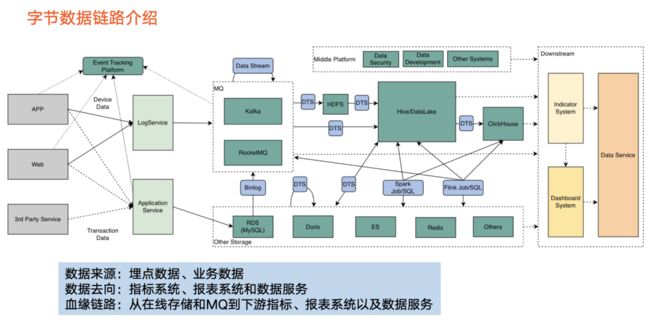
数据来源
在字节跳动,数据主要来源于以下两部分:
埋点数据:
主要来自 APP 端和 Web 端。经过日志采集后,这类数据最终进入到消息队列中。
业务数据:
该类数据一般以在线形式存储,如 RDS 等。
中间部分是以 Hive 为代表的离线数仓:
该类数据主要来自消息队列或者在线存储,经过数据集成服务把数据导入离线数仓。经过离线数仓的数据加工逻辑,流转到以 ClickHouse 为代表的 OLAP 引擎。
另外,在消息队列部分,还会通过 Flink 任务或者其他任务对Topic 分流,因此上图也展现了一个回指的箭头。
数据去向
主要以指标系统和报表系统为代表。指标系统包含重要且常用的业务指标,如抖音的日活等。报表系统是把指标以可视化形式展现出来。
数据服务
主要通过 API 提供数据,具体而言,从消息队列、在线存储、下游消费以及上图右侧所示的数据流转,都涵盖在数据血缘范围内。
血缘发展概况
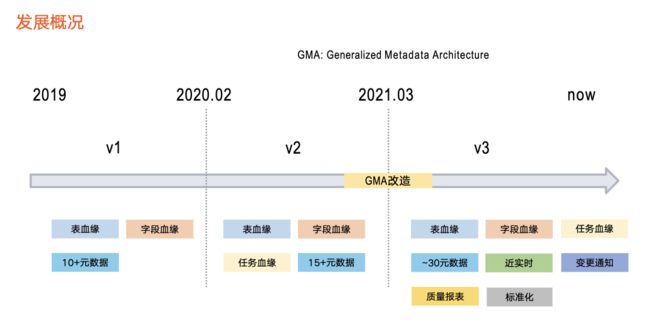
接下来介绍血缘在字节跳动的三个发展阶段。
第一阶段:2019 年左右开始
第一阶段主要提供数据血缘基础能力,以 Hive 和 ClickHouse 为代表,支持表级血缘、字段血缘,涉及10+元数据。
第二阶段:从 2020 年初开始
第二阶段引入了任务血缘,同时支持的元数据类型进行扩充,达到15+。
第三阶段:从 2021 年上半年至今
在这一阶段,我们对整个元数据系统(即前文提到的资产平台)进行了 GMA 改造,同步对血缘架构进行全面升级,由此支持了更丰富的功能,具体包括:
首先, 元数据种类扩充到近 30 种且时效性提升。之前以离线方式更新血缘数据,导致数据加工逻辑变化的第二天,血缘才会产生变化。目前,基于近实时的更新方式,数据加工逻辑在 1 分钟内即在血缘中体现。
其次,新增血缘消费方式的变更通知。由于该版本支持实时血缘,业务方产生及时了解血缘变化的需求,变动通知功能就是把血缘变化情况以消息队列的形式告知业务方。
再次,支持评估血缘质量。新增一条链路,专门服务于血缘数据质量。
最后,引入标准化接入方式。为了减少重复工作、降低血缘接入成本,我们制定了详细的血缘接入标准,业务方数据均以标准化方式接入。
以上就是整体的发展情况,目前处于第三个版本当中。
数据血缘架构的演进
1. 第一版血缘架构:建立血缘基本能力,初探使用场景
血缘架构
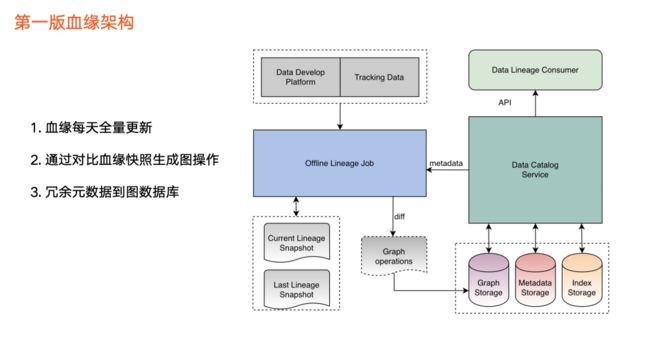
1. 在数据来源方面,目前血缘主要包括两个数据来源(见上图左上角):
-
第一,数据开发平台: 用户在开发平台写任务,并对数据加工,由此产生血缘数据。
第二,追踪数据: 第三方平台(即任务平台)对用户埋点等数据进行计算,也会产生血缘信息。
2. 在血缘加工任务方面(见上图中间部分):
这部分会对任务进行血缘解析,产生血缘快照文件。由于第一版采用离线方式运行,每天该血缘任务均会生成对应的血缘快照文件。我们通过对比前后两天的血缘快照文件,来获取血缘的变更情况,然后把这些变更加载到图中。
除此之外,血缘中涉及的元数据会冗余一份,并存储到图里。
3. 在血缘存储方面(见上图右边部分),除了应用于图数据库之外,血缘本身也会依赖元数据的存储,如 Mysql 以及索引类存储。
4. 在血缘消费层面,第一版只支持通过API 进行消费。
最后总结该版本的三个关键点:
血缘数据每天以离线方式全量更新。
通过对比图来判断血缘更新操作,后面将为大家详细解答为什么要通过对比的方式。
冗余一份元数据存储到图数据库中。
存储模型
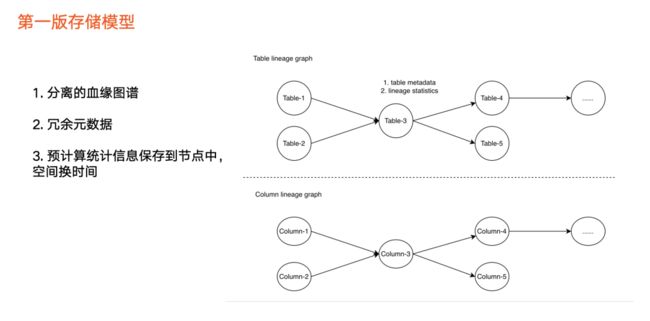
图中上半部分为表级血缘,只包括一种类型节点,即表节点,如说 Hive 表、 ClickHouse 表以及其他表。
图中下半部分为字段血缘图,第一版主要是提供构建血缘的基本能力,因此用彼此分离的两张图来实现。由于血缘中元数据进行了冗余,每个图里面的每个节点里面都存储表相关的元数据,包括业务信息以及其他信息。
除此之外,我们会预先计算一些统计信息,保存到图的节点中,如当前节点下游总节点数量、下游层级数量等。
采用预先计算的目的是为了“用空间换时间”,在产品对外展示的功能上可能要露出数据信息,如果从图里实时查询可能影响性能,因此采用空间换时间的方式来支持产品的展示。
2. 第二版血缘架构:血缘价值逐步体现,使用场景拓宽
血缘架构
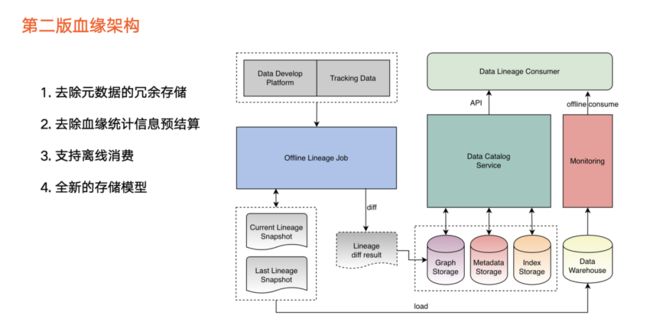
经过1年的使用,血缘在数据资产中的价值逐步体现,且不断有应用场景落地,由此我们进行了第二版本升级。升级点具体包括:
第一,去除第一版本中元数据冗余。元数据冗余在图提升了性能,但是可能导致 Metadata Store 的元数据不一致,给用户带来困扰。
第二,去掉了预计算的统计信息。随着血缘的数据量增多,预计算的信息透出不能给很好辅助用户完成业务判断,且导致任务负担重。比如,即使知道某一节点的下游数据量,还是要拉出所有节点才能进一步分析或决策。
第三,支持一条全新链路,在新增链路上,我们把血缘快照文件导入离线数仓,主要应用于两个场景:
离线分析场景或全量分析场景。
基于离线数仓的血缘数据实现数据
监控
,尽早发现血缘异常情况。
因此,从第二版开始,数据血缘新增了很多离线消费方式。
存储模型
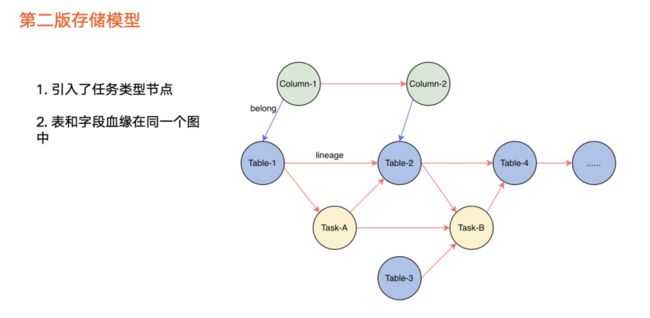
第二个版本引入了全新血缘存储模型(如上图所示),并将第一个版本两张图融合成一张图,解决了无法通过表遍历字段血缘的问题。
除此之外,第二个版本还引入了任务类型节点,服务于以下三种遍历场景:
单纯遍历数据血缘
,即从数据节点到数据节点。
数据血缘和任务血缘混合方式
。
单纯
任务之间血缘关系
。
3. 第三版血缘架构:血缘成为数据发挥价值的重要基础能力
血缘架构
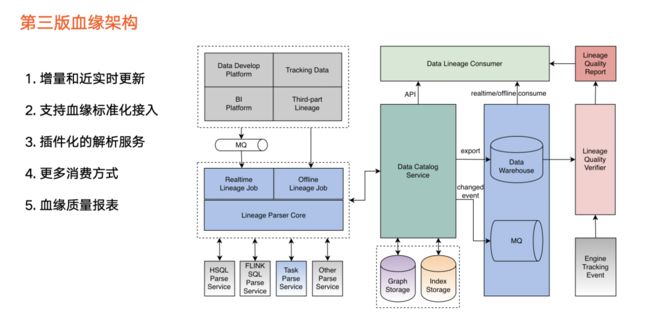
2021年初,火山引擎DataLeap数据血缘迭代到第三版,也成为公司内部数据发挥价值的重要基础能力。
服务于业务方对数据高质量要求,第三版升级点如下:
血缘数据来源: 除了支持两个平台之外,还支持包括报表、第三方用户画像等其他平台 。
血缘任务: 之前版本只支持每天定时运行的离线调度方式,第三版引入实时消费方式,支持实时解析血缘,并提取通用逻辑,复用离线血缘任务和实时血缘任务。
血缘解析:不同类型任务需要使用不同解析逻辑。在之前版本中,Hive SQL 任务和Flink SQL任务的解析逻辑是集成到血缘任务中。从第三版开始,我们把解析服务拆解成可配置的插件,实现了插件化。当某一种任务类型的血缘解析逻辑需要调整的时候,只用改动其中一个解析服务,其他解析服务不受影响,同时也让血缘任务更好维护。
元数据存储统一:只依赖图数据库和索引存储,同时支持从系统中把所有相关的数据导出离线数仓。
实时消费: 血缘发生变更的信息会被同步到消息队列。
血缘的验证模块: 使用方对血缘数据质量有高要求,因此第三版引入新的血缘的验证模块。
验证的前提是要有引擎埋点数据,该埋点数据能清楚知道某一个任务具体读取数据情况、写入数据情况
在离线数仓中,通过埋点数据与血缘数据中对比,生成血缘数据质量报表。
数据质量报表对血缘消费者开放,消费者能够清晰了解每个血缘链路准确性和覆盖情况。
血缘标准化接入: 即让用户快速接入数据,不用每一种血缘接入都重复写逻辑。
存储模型
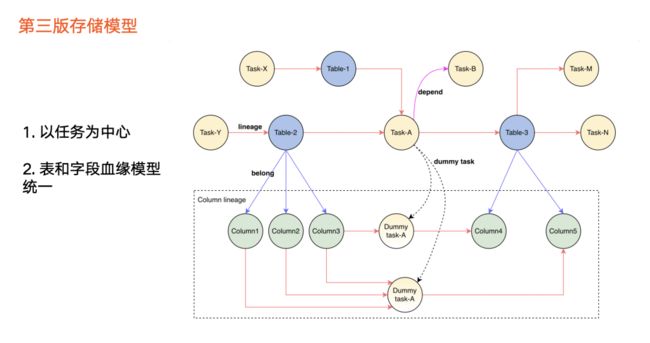
第三版血缘存储模型相对于前两版的升级点如下:
以任务为中心
。黄色圆圈为任务节点,数据加工逻辑产生血缘,因此我们把数据加工逻辑抽象为任务节点,血缘的建立则以任务为媒介,任务成为血缘中心。也就是说,表1、表2、表3之间的血缘,是通过任务 a 完成构建。假设没有任务 a ,则三个表之间的血缘也不存在。
表血缘和字段血缘模型统一
,在字段血缘之间没有具体任务的情况下,我们会抽象出虚拟的任务来统一模型。由此,任务和任务之间的血缘采用新的边来表示依赖关系。
重要特性
增量更新
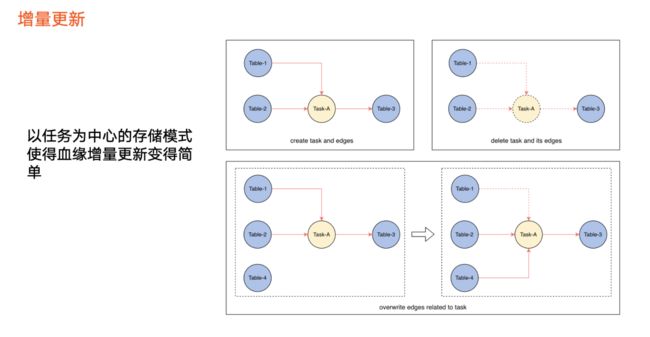
在实时血缘基础上,我们还支持增量更新能力,即当某一个任务的加工逻辑发生变化时,只需要更新图中一小部分。
血缘创建: 数据加工逻辑上线或开始生效,将被抽象为图数据库的操作,即创建一个任务节点和对应的数据节点,并创建两者之间的边。上图例子为表1、表2和任务的边,以及任务和表3之间的边。
血缘删除:数据的加工逻辑发生了下线、删除或不生效。 先在图里面查询该任务节点,把任务节点以及关联血缘相关的边删除。血缘存储模型以任务为中心,因此表1、表2和表3之间的血缘关系也同步消失,这部分血缘即被删除。
血缘更新:任务本身没有发生上线或下线,但计算逻辑发生变化。 例如,原本血缘关系是表1、表2生成表3,现在变成了表2、表4生成表3。我们需要做的如下:
解析出最新血缘状态,即表2、表4到表3的血缘关系,与当前血缘状态做对比(主要对比该任务 a 相关的边),上图例子是入边发生变化,那么删除其中一条边,构建另外一条边,即可完成该任务节点的血缘更新。
如果面临以上血缘关系变化,但是没有该任务节点,应该执行哪些操作来更新血缘?由于只有血缘最新状态和当前状态,没有任务节点去获取最小单位的血缘关系,所以只能进行全量血缘或全图对比,才能得出边的变化情况,再更新到图数据库中。如果不进行全量血缘或全图对比,无法知晓如何删除条和创建条,导致血缘无法更新。这也是前两个版本需要进行血缘快照对比的原因。
血缘标准化
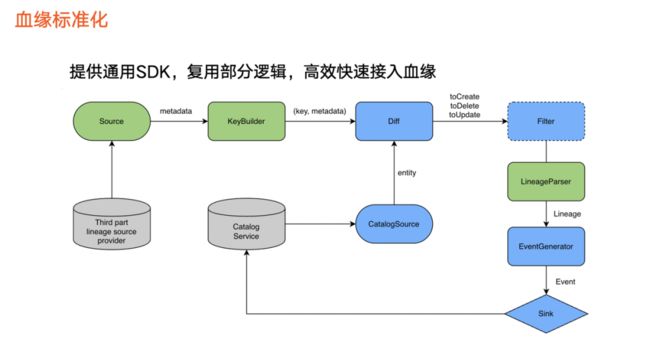
在火山引擎DataLeap中,通常把血缘数据接入抽象成一个 ETL 。
首先,血缘数据来源,即第三方平台血缘相关的数据,通常是一个数据加工逻辑或者称为任务。接着,对这些任务完成 KeyBy 操作,并与数据资产平台的任务信息做对比,确定如何进行任何创建、删除和更新。
在再完成过滤操作之后, 由Lineage Parser 对创建、更新等任务进行血缘解析,得出血缘结果之后会生成表示图相关操作的Event,最终通过Sink 把数据写入到数据资产平台中。
上图绿色和蓝色分别表示:
蓝色:对不同血缘接入过程的逻辑一致,可抽象出来并复用。
绿色:不同血缘的实现情况不一样。例如,某一个平台为拉取数据,另外一个平台通过其他方式获取数据,导致三个部分不一样,因此我们抽取特殊部分,复用共同部分。除此之外,我们还提供通用 SDK,串联整个血缘接入流程,使得接入新的血缘时,只需要实现绿色组件。
目前,字节跳动内部业务已经可以使用 SDK 轻松接入血缘。
数据血缘质量-覆盖率

当血缘发展到一定阶段,业务方不止关心血缘覆盖情况、支持情况,还关心血缘数据质量情况。因此,第三版本透出血缘质量相关指标——覆盖率和准确率。
覆盖率:血缘覆盖的数据资产数占关注的资产数量占比。
关注的数据资产一般指,有生产任务或有生产行为的资产。上图虚线圆圈,如 Table 9,用户创建该表后没有生产行为,因此也不会产生血缘,在计算中将被剔除掉。上图实线圆圈,表示有生产行为或有任务读取,则被认为是关注的资产。关注的数据资产被血缘覆盖的占比,即覆盖率。
以上图为例,在10张表中,由于有任务与Table 1 ~ 8关联,因此判定有血缘。Table 10,它与Task-D之间的连线是虚线,表示本来它应该有血缘,但是实际上血缘任务没把这个血缘关系解析出来,那么我们就认为这个 Table 10是没有被血缘覆盖的。整体上被血缘覆盖的资产就是表1 ~ 8。除了Table 9之外,其他的都是关注的资产,那么血缘覆盖的资产占比就是8/9。也就是图上蓝色的这第8个除以蓝色的8个加上 Table 10,就是9个,所以这个覆盖率就是88%。
数据血缘质量-准确率
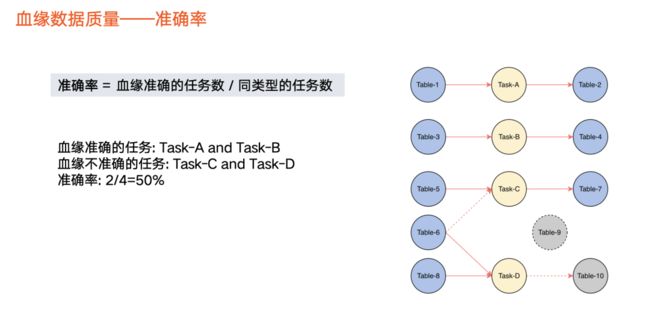
覆盖血缘不一定是正确的,所以我们还定义了准确率指标,即血缘准确的任务数/同类型的任务数。
举个例子,假设任务 c的血缘应该是 Table 5、Table6生成 Table 7,但实际上被遗漏,没有被解析(虚线表示),导致任务 c 的血缘不准确。也存在其他情况缺失或多余情况,导致血缘不准确。
在上图中,同类型任务包含4个,即 a、b、c、d。那么,准确的血缘解析只有 a、b,因此准确率占比为2/4 = 50%。
在火山引擎DataLeap中,由于血缘来源是任务,因此我们以任务的视角来看待血缘准确率。
血缘质量-字节现状
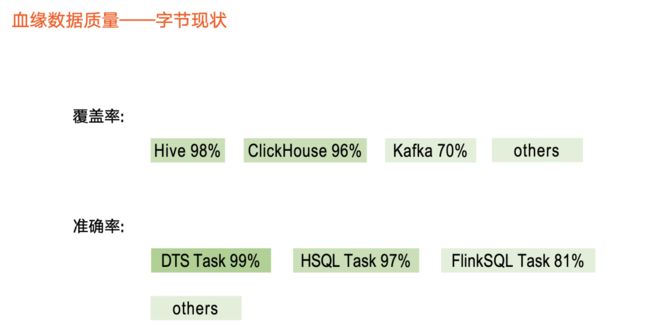
在覆盖率部分,目前 Hive 和 ClickHouse 元数据覆盖度较高,分别达到98%、96%。对于实时元数据,如Kafka ,相关 Topic覆盖70%,其他元数据则稍低。
在准确率部分,我们区分任务类型做准确性解析。如 DTS 数据集成任务达到99%以上,Hive SQL 任务、 Flink SQL 任务是97%、81% 左右。
血缘架构对比
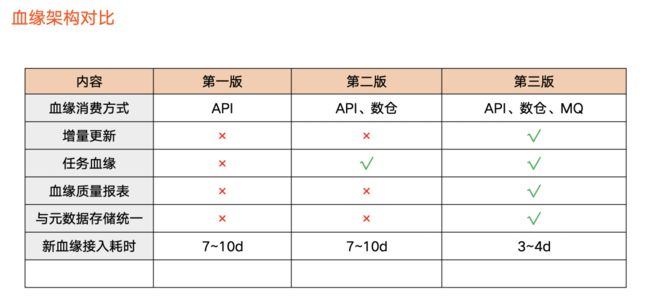
上图为三个版本对比情况:
血缘的消费方式
:第一版只支持 API 的方式,用户需要在数据资产平台上查看血缘信息;第二版支持离线数仓,让用户可以全量分析血缘;第三版支持消息队列,使用户可以获取血缘增量的变化。
增量更新:
第三版开始支持增量更新。
血缘任务:
第二个版本开始支持任务血缘,第三个版本支持数据质量。
元数据存储统一:
第三版进行了元数据架构升级,使得元数据和血缘存储在同一个地方。
新血缘接入耗时:
前两个版本大概需要花费 7-10 天左右。第三版本引入标准化,外部业务方或字节内部用标准化流程,实现 3、4 天左右完成开发、测试、上线。
未来展望
第一,持续对架构和流程进行精简。 目前,血缘任务分为离线和实时两部分,但没有完全统一。在插件化、横向扩展等方面也需要加强。
第二,生态化支持。 目前支持公司内部的元数据,未来计划拓展对开源或外部元数据的支持。在血缘标准化方面,提供一站式数据血缘能力,作为基础能力平台为业务方提供服务。
第三,提升数据质量。 除了血缘数量,还需要持续提升质量。同时由于数据链路复杂,导致链路问题排查异常困难,未来我们也会支持快速诊断。
最后,支持智能化场景。 结合元数仓等数据,提供包含关键链路梳理在内的智能化能力。目前,当业务方发现数据有问题之后,主要通过按照血缘数据一个一个排查方式解决,导致效率低下。未来,我们将考虑透出血缘关键链路,提升排查效率。
以上介绍的数据血缘能力和实践,目前大部分已通过火山引擎 DataLeap 对外提供服务,欢迎大家点击阅读原文体验。

添加小助手企业微信,回复“数据血缘”,领取本次分享 PPT
 阅读原文,立即体验!
阅读原文,立即体验!