【自监督论文阅读 2】MAE
文章目录
- 一、摘要
- 二、引言
-
- 2.1 引言部分
- 2.2 本文架构
- 三、相关工作
-
- 3.1 Masked language modeling
- 3.2 Autoencoding
- 3.3 Masked image encoding
- 3.4 Self-supervised learning
- 四、方法
-
- 4.1 Masking
- 4.2 MAE encoder
- 4.3 MAE decoder
- 4.4 Reconstruction target
- 五、主要实验
-
- 5.1 不同mask比例下的效果
- 5.2 消融实验
- 5.3 训练时间
- 5.4 预训练轮数
- 5.5 和以前方法的精度比较
- 5.5 冻结多少层,进行微调最合适
- 5.6 迁移学习
- 六、结论
自监督论文阅读系列:
【自监督论文阅读 1】SimCLR
【自监督论文阅读 2】MAE
论文地址:https://arxiv.org/pdf/2111.06377.pdf
github代码地址:https://github.com/facebookresearch/mae
沐神B站视频讲解地址(看这个视频就够了):https://www.bilibili.com/video/BV1sq4y1q77t/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=e768911f41969985adfce85914bfde8f
论文题目:Masked Autoencoders Are Scalable Vision Learners
论文作者: Kaiming He, Xinlei Chen,Saining Xie, Yanghao Li, Piotr Doll´ar, Ross Girshick
一、摘要
这篇文章,展示了在计算视觉领域,masked的自编码器(简称MAE)是一个可拓展的自监督学习器。
MAE的架构是比较简单的:随机mask图像块,然后重构失去的图像块,主要由两个设计构成:
- 非对称的encoder-decoder架构,其中encoder仅用于可见的图像块,decoder则是轻量的,基于基于潜在表征和mask的token来重构原始输入图像
- 本文发现,遮住更多的图像块,比如75%,可以得到一个平凡但有意义的自监督任务
基于以上设计,可以高效且有效的训练大模型,结果如下:
- 加快了训练:3倍或者更多,同时提高了准确率
- 训练的方法,可以应用到各种高容量的模型中:比如Vit-Huge取得了87.8%的精度,在仅采用ImageNet-1K 的数据下。
- 还可以拓展到其他下游任务中:使用预训练模型应用在下游任务中时,性能优于监督学习。
二、引言
2.1 引言部分
深度学习架构、能力都在不断的增长,在硬件快速增长的帮助下,模型很容易拟合100万张图像,并且开始像数亿张图像进军,当然,这些图像通常是公开,且未标注的。
NLP在自监督学习领域取得巨大成功,比如GPT、BERT(masked 的自编码器)等等,在概念上都是比较简易的:移除一定概率的内容,学习预测这些内容。这些方法可以训练超过1000亿个参数的广义NLP模型。
由于BERT取得巨大成功,masked的自编码器(MAE)应用到图像领域也引起了极大的兴趣,但是,视觉领域的自编码方法的进展仍然落后NLP。
是什么导致MAE在视觉和语言任务上的不同?作者做如下解答:
- 1、架构不同:在视觉领域,卷积网络是主流,卷积在规律网格上操作,不直聚合提示器比如mask tokens或者位置编码;
- 2、信息密度不同:自然语言有着高语义和高密度信息,一个词就是一个语义的实体;图像相反,像素是冗余的,missing patch能够从相邻块还原;
- 3、自动编码码里的解码器不同:Bert用一个MLP即可对词预测,而图像解码器的设计在学习语义上的潜在表示起着关键作用(PS: 一个全连接显然还原不了图像)
2.2 本文架构
基于以上分析,本文提出了一个简单、有效、可拓展的masked 自编码器(MAE), 可以应用到视觉表征学习中,结构如下图所示:

- step1:随机大比例Mask图像块,约75%; (为了解决图像信息冗余的问题,本文选择mask掉更多比例的patches)
- step2:编码器仅应用在可见的图像块中; (双赢!即加快了计算速度,又提高的准确率。PS:掩码这么多都能还原,那表征信息肯定学的多呀)
- step3:可见块的编码信息与共享权重的mask的token结合,送入到轻量化的decoder(另外一个Vit模型)中,重构原始图像;(将mask tokens转移到小的decoder中可以大大减少计算)
- step3:仅将全部patch的编码器应用到下游任务中 (解码器后的信息丢弃)
下图展示了mask后的还原信息(PS: 这么少的图像patch, 都能有效还原,明显超过人类了)

三、相关工作
3.1 Masked language modeling
masked 语言模型,比如Bert、GPT等,在NLP都取得了巨大的成功,并且是可拓展的,表明了预训练的表征可以应用到众多下游任务中。这些方法都是在输入队列中,移除一部分,然后预测消失的内容。
3.2 Autoencoding
自编码器是表征学习里很经典的方法:
- 1、对输入进行编码,生成 latent representation;
- 2、从 latent representation中解码,还原原始输入。
像PCA、K-means都是一定形式的自编码器, Denoising autoencoders (DAE) 是一个很典型的自编码器:在输入信号中添加噪声,然后重构原始输入,未损坏的信号。
本文方法也相当于一定形式的噪声,但是在很多方面与经典的DAE有所不同。
3.3 Masked image encoding
通过mask图像学习特征表示,比如DAE。 受NLP领域的成功,iGPT、BEiT等将Vit成功应用到视觉领域。与本文效果特别接近的是,BEiT提出学习一个离散的tokens,然后每个patch还原这些tokens.
这里MAE则是直接还原原始像素信息,更简单实现。
3.4 Self-supervised learning
自监督学习通常聚焦于不同的pretext任务。
最近对比学习比较火:通常是在两个或者更多的view上建模图像的相似度,然后对比学习非常依赖数据增强,这个本文的自动编解码,追求的是不同的方向。
四、方法
具体流程在 2.2中已经介绍,这里描述一下各个设计的意义:
4.1 Masking
随机大比例Mask图像块,约75%.
高比例随机采样patch的好处:
- 大大降低了图像的冗余;
- 创建了任务,不能被简单的从相邻的patch中推断出来的任务
- 均匀分布防止了潜在的中心偏差(中心偏差指在图像中心附近有更多的mask)
- 高度稀疏的输入为设计一个有效的编码器创造机
4.2 MAE encoder
编码器就是一个Vit模型,但是仅用于可见的图像块中(没有masked的),和标准的ViT模型一样, 本文的编码器也是经过一个线性头+位置编码得到编码向量,再送入到一系列的Transform 的Block中,得到潜在表征。
编码器仅应用在小比例的图像块中(大约25%),这个就使得,可以训练一些大的编码器。
4.3 MAE decoder
解码器输入由两部分组成:可见图像的编码信息和 mask的token
- 没有被mask的图像块,直接送入编码器中
- 被mask的图像块,通过一个共享的,可学习的向量表示
解码器就是一个新的Transform, 对mask的图像块加入了位置信息。(PS:论文中,对没有mask的图像块,并没有再次加入位置信息,我猜测可能编码的时候,已经有位置信息在里面了)
4.4 Reconstruction target
decoder的输出就是一个全连接,然后reshape成重建的图像,使用MSE损失,并且仅作用在被masked的图像块上。
实现方式:
- 首先对每个patch做线性投影+位置信息,生成token列表
- 随机打乱,对mask的区域用一个向量共享,然后通过unshuffle操作还原,并加上位置信息。
还强调了预测归一化后的像素是效果是最好的(即预测均值和方差)
五、主要实验
5.1 不同mask比例下的效果
可以看出,大约75%时的效果最好

5.2 消融实验
做了一些实验,所有层都微调 和冻结特征表征层,仅微调线性层,一些总结如下:
- 所有层都微调时,消融试验后的精度差不多
- 解码器深度为8时,精度最佳
- 解码器宽度为512时,精度最佳
- 编码器中,不加入被mask的块,比加入效果更好
- 重构目标时,重构像素且加上归一化效果最好 (PS:仅比BEiT高一点点,但方法更简单)
- 不是特别依赖数据增强
- 采样的方式:随机采样的效果是最好的

下图展示了不同采样方式

5.3 训练时间
官方代码是pytorch的,论文里用的TF

5.4 预训练轮数
1000个epochs后,还有拟合空间。

5.5 和以前方法的精度比较
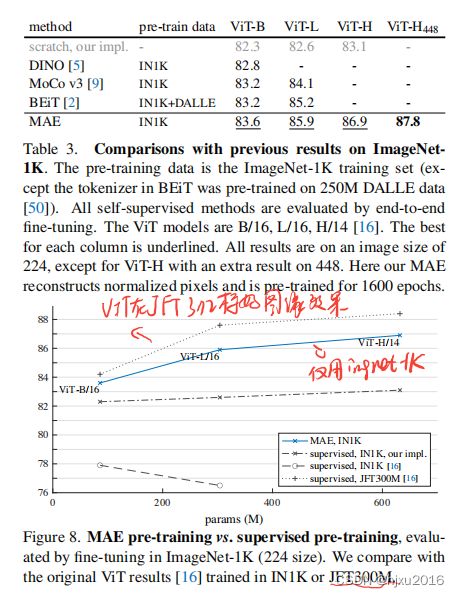
5.5 冻结多少层,进行微调最合适
这里是和MoCo V3比较的,从表上看,MAE在4层之前,效果就超过了全部微调的MoCoV3.

5.6 迁移学习
列了语义分割,目标检测、分类等下游任务,都是最佳。

六、结论
- 利用ViT, 根Bert一样进行自监督(在图像领域)
- 盖住更多的图像块,可以降低图像块之间的冗余度,使任务更加复杂
- 使用transform架构的解码器,直接还原原始像素信息,流程更加简单
- 加上Vit后的各种技术,使训练更加鲁棒