【自监督论文阅读 3】DINOv1
文章目录
- 一、摘要
- 二、引言
- 三、相关工作
-
- 3.1 自监督学习
- 3.2 自训练与知识蒸馏
- 四、方法
-
- 4.1 SSL with Knowledge Distillation
- 4.2 教师网络
- 4.3 网络架构
- 4.4 避免坍塌
- 五、实验与评估
- 六、消融实验
-
- 6.1 不同组合的重要性
- 6.2 教师网络选择的影响
- 6.3 避免坍塌
- 6.4 在小batch上训练
- 七、结论
自监督论文阅读系列:
【自监督论文阅读 1】SimCLR
【自监督论文阅读 2】MAE
【自监督论文阅读 3】DINOv1
论文地址:https://arxiv.org/pdf/2104.14294.pdf
github地址:https://github.com/facebookresearch/dino
论文题目:Emerging Properties in Self-Supervised Vision Transformers
一、摘要
在这篇文章里,质疑了自监督学习是否为ViT提供了与卷积网络相比更加突出的新的属性。
然后就是除了自监督方法适用于这篇文章提出的架构是特别有效的之外,本文还进行了以下观察:
- 自监督的ViT特征包含了显著的语义分割的信息;
- 这些特征也是优秀的K-NN分类器,用一个小的Vit,就在ImageNet上取得了78.3%的top1准确率
这篇文章同样列出了以下几点的重要性:
- mementum encoder (动量编码器)
- multi-cop training (多尺度裁剪训练)
- the use of small patches with ViTs (带有Vits的小patch的使用)
本文方法实现为一个简单的自监督方法,叫做DINO(一定形式的无标签自蒸馏 self-distillation with no labels),本文展示了DINO和ViTs之间的协同作用, 在ImageNet上, 使用VIiT-Base的 linear评估达到80.1%的的top1准确率。
二、引言
Transformers最近在视觉识别领域,已经作为卷积网络的替代品出现。受NLP训练策略启发,Transformers在视觉领域的应用,也是对大量的数据进行预训练,然后在目标数据集上微调。
由此产生的ViT与卷积网络比,具有竞争力,但尚未出现明显的优势,如:
- 对计算要求更高
- 需要更多的数据
- 特征没有表现出独有的特性
这篇论文质疑了,Transformers在视觉领域的成功,是不是因为预训练中采用的是监督学习,动机如下:
- Transformer在NLP领域成功的最大因素之一是使用了自监督预训练;
- 自监督预训练目标使用句子中的单词来创建一个pretext任务,这个比每个句子预测单个标签的监督目标有更丰富的学习信号
- 图像类似,图像强监督的会将图中丰富的视觉信息简化成单一的概念
虽然在NLP领域使用的自监督前置任务是特定文本的,但许多现有的使用卷积网络的自监督方法已经展示出在图像上的潜力。它们通常具有相似的结构,但具有不同的组件,这样设计是为了避免模型坍塌或者提高性能。 受这些工作启发,这篇文章确定了几个有趣的属性,这些属性不会出现在受监督的 ViT 中,也不会出现在卷积网络中:
-
自监督 ViT 特征 明确包含场景布局,特别是 对象边界,如下图 所示。这些信息 可以在最后一个模块的自注意模块中 直接获取
-
自监督 ViT 功能 在基本的最近邻分类器 (k-NN) 上表现特别出色,无需任何微调、线性分类器或数据增强,在 ImageNet 上达到 78.3% 的 top-1 准确度

总的来说,这篇文章通过对这些组成部分的重要性的发现,设计了一种简单的自监督方法,然后解释为了一种 没有标签的知识蒸馏形式 ,成之为DINO。DINO简化了自监督训练,体现在以下几个方面: -
使用标准的交叉熵损失 直接预测教师网络
-
教师网络是通过使用动量编码器来构建
-
本文方法只能使用 教师输出的 中心化和锐化 来避免崩溃。而其他流行的组件,如预测器 、高级归一化或 对比损失在稳定性或性能方面几乎没有什么好处
-
框架非常灵活。可以在 convnets 和 ViTs 上工作,无需修改架构,也不需要调整内部的归一化
三、相关工作
3.1 自监督学习
大量关于自监督学习的工作 侧重于创造实例分类 的判别方法,该方法将每个图像视为不同的类别,并通过在不同的数据增强训练模型(区分它们)。然而,显式学习分类器以区分所有图像 并不能很好地适应图像数量。有文章建议 使用噪声对比估计 (NCE) 来比较实例,而不是对它们进行分类。这种方法的一个限制是 它需要同时比较大量图像的特征。实际上,这 需要大的batchsize 或内存库,还有几个变体允许以聚类的形式自动对实例进行分组。
最近的工作表明,可以在不区分图像的情况下学习无监督特征。特别有趣的是,其中有一种称为 BYOL 的度量学习公式,其中通过 将特征与使用动量编码器获得的表示相匹配 来训练特征。已经表明,像 BYOL 这样的方法即使没有动量编码器也能工作,但代价是性能下降。
其他几项工作也呼应了这个方向,表明可以训练与 l2 超球面 上的均匀分布相匹配的特征,或使用白化操作。
文章中的方法从 BYOL 中汲取灵感,但又有以下不同之处:
- 但使用不同的相似性匹配损失
- 为学生和教师使用完全相同的架构。
这样,我们的工作就完成了在 BYOL 中发起的对自监督学习的解释,作为一种没有标签的 Mean Teacher 自蒸馏 的形式。
3.2 自训练与知识蒸馏
- 自训练: 通过将一小部分初始注释 传播到大量未标记实例 来提高特征质量。这种传播可以 通过标签的硬分配 或 软分配 来完成。
- 当使用软标签时,该方法通常被称为知识蒸馏 ,主要设计用于 训练小型网络 以模仿大型网络的输出 以压缩模型。
- 蒸馏可用于 将 软伪标签 传播到自训练流程中的 未标记数据,从而在自训练和知识蒸馏之间建立了本质联系。
这篇文章的工作的正是建立在这种联系之上,并且将知识蒸馏扩展到没有标签可用的情况。
以前的工作还结合了自监督学习和知识蒸馏,实现了 自监督模型压缩 和性能提升。然而,这些作品依赖于 预训练的固定教师,而本文方法是:
- 教师网络是在训练期间动态构建的,这样,知识蒸馏就不会被用作自监督预训练的后处理步骤,而是直接被用作自监督目标
- 我们的工作还与协同蒸馏codistillation 有关,其中 学生和教师具有相同的架构, 并 在训练期间使用蒸馏。然而,codistillation 中的 teacher 也是从 student 中蒸馏出来的,而 在我们的工作中 它是用 student 的动量平均值更新的。
四、方法
4.1 SSL with Knowledge Distillation
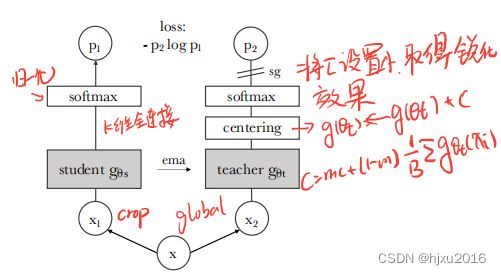
DINO框架 与最近的自监督方法具有相同的整体结构。然而,DINO也与知识蒸馏 有相似之处,这篇文章主要从知识蒸馏的角度来介绍它。下图说明了 DINO,还有一个伪代码的实现:

-
输入 x x x 为原始图像,经过两种数据增强方式得到 x 1 x_1 x1和 x 2 x_2 x2,分别送入到学生网络 g ( θ s ) g(θ_s) g(θs)和教师网络 g ( θ t ) g(θ_t) g(θt)中。需要注意的是,数据增强里组合里有local views和global views,
所有的local crop都送入到学生网络中,教师网络仅输入global views。 主要用来鼓励 局部到全局的通信。 -
教师网络不参与反向传播,参数通过exponential moving average (EMA),从学生网络的参数更新,更新规则如下:
θ t ← λ θ t + ( 1 − λ ) θ s , θ_t ← λθ_t + (1 − λ)θ_s, θt←λθt+(1−λ)θs, 其中,λ在训练期间,遵循一个余弦规则表,从0.996到1。 -
教师网络和学生网络的输出 P s P_s Ps和 P t P_t Pt,都表示 K K K维的概率分布。 概率 P P P说白了,就是网络最后一层的全连接的预测头后,再接一个SoftMax, 只不过这里的Softmax带有一个控制输出分布锐度的温度参数
-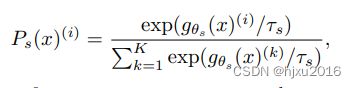 - 教师网络输出后,接一个centering操作,用来防止一个维度占主导地位,使鼓励崩塌到均匀分布。centering操作可以看成 教师网络的输出再加上一个偏置项:
- 教师网络输出后,接一个centering操作,用来防止一个维度占主导地位,使鼓励崩塌到均匀分布。centering操作可以看成 教师网络的输出再加上一个偏置项:g t ( x ) ← g t ( x ) + c g_t(x) ← g_t(x) + c gt(x)←gt(x)+c.
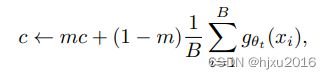
-
锐化操作紧接着centering后:就是将softmax中的温度参数设置为一个较小的值。
-
损失函数就是交叉熵损失函数,用来衡量向量之间的一致性
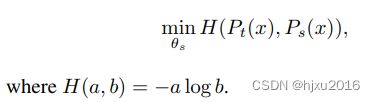
4.2 教师网络
4.1已经介绍过,这里总结如下:
- 和知识蒸馏不一样,没有先验的参数,通过上一个iter的学生网络的参数进行迭代
- 教师网络的参数被冻结,不参与反向传播
- 学生权重使用EMA来激活教师权重,如果直接复制学生网络的参数无法收敛
4.3 网络架构
神经网络 g g g 由backbone f f f(Vit或者ResNet等)和投影头 h h h组成: g = h ◦ f g=h ◦ f g=h◦f
使用 f f f 作为下游任务中的特征。
- 投影头 h h h:3层的MLP,隐藏维度为2048(遵循L2 normalization)和一个K维归一化的全连接。
- backbone h h h:Vit或者ResNet, 可应用于下游任务
值得注意的一个现象是,与标准的对流网络不同,ViT架构在默认情况下不使用批处理规范化(BN)。因此,当将DINO应用于ViT时,我们也不会在投影头中使用任何BN,从而使系统完全没有BN。
4.4 避免坍塌
现有的自监督方法避免坍塌有着不同的方法,比如对比损失、聚类约束、预测或者批量归一化。
虽然本文方法可以通过多次归一化来确定,但也可以通过对动量老师的输出进行centering居中和sharping锐化来避免模型坍塌。
居中 防止一个维度占主导地位,但 鼓励崩溃到均匀分布,而 锐化具有相反的效果。应用这两种操作平衡了它们的效果,这足以避免在有动量老师的情况下模型发送坍塌。
五、实验与评估
六、消融实验
6.1 不同组合的重要性
6.2 教师网络选择的影响
6.3 避免坍塌
6.4 在小batch上训练
七、结论
- 展示了自监督预训练Vit模型的潜力
- KNN分类中特征质量有在图像检索中的潜力
- 特征中场景布局信息的存在,有利于弱监督图像分割
- 自监督学习可能是发展BERT-Like的key