应用之元数据血缘分析的银行业务做法
今天就来详细聊聊元数据应用中的血缘分析,也就是数据的“家庭背景”在银行业务中是怎么实现价值的。
数据血缘从哪里出现?
在切入正题之前,我们先设想几个场景:
1. 业务部门的小A拿到了一张报表,发现当月利息收入与预想的差距甚大,明明刚批了几个大额贷款,为何利息收入没有增加?小A一个电话打给了报表项目组的开发人员小B。
小A:你们开发的报表是不是有问题,利息收入不对啊!
小B:不可能不对,这个报表系统用了几个月了,天天跑批,以前都没出过问题啊。
小A:可是这个月的数据就是不对,出入很大,肯定是你们代码逻辑有问题或者数据哪里出问题了,快帮我查查。
小B:这个报表数据流转几十个系统,代码几万行,给你查完明年的报表都做出来了。
小A挂了电话,却毫无办法,只能期待下月的报表不出问题。
2. 业务部门的小C想要对本月营收状况做一下分析,走了很长的流程才把数据借到,可是当他打开数据,却发现自己很难理解这些数据的意义,系统里的“存款类资产”一项到底是怎么定义计算出来的,“非存款类资产”又是如何得到的,都不得而知。为了完成任务,只能打电话一个个去询问,大大影响了工作效率。
3. 小D是开发中心的一名数据开发工程师,突然收到了一个表结构变更需求,废了好大的劲才找到了调用这张表的下游表,通知完相应人员后,满心欢喜的做了表结构变更,可是没一会就接到了同事的电话,“这张表的xxx字段怎么没了!正准备上线的报表,业务部门的老师都急死了!”,小D一查,果然漏了一张下游表没有查到。
诸如此类的场景时常会在银行工作中发生,存在于各类系统中的海量数据,对于各大银行来说,既是资产,也是减缓、阻碍其前进步伐的沼泽。如何理顺这些庞大的数据,让他们同血管般流转通畅且井井有条?数据血缘分析或许是一个很好的方法。
血缘分析如何实现?
数据血缘分析是元数据管理的重要应用之一,梳理系统、表、视图、字段等之间的关系,并采用DAG(有向无环图)的模式进行可视化展现。简单地说就是可视化地展示这个数据是怎么来的,经过了哪些过程和阶段。
从技术角度讲,数据a通过ETL处理生成了数据b,那么我们就说数据a与b有着血缘关系,且数据a是数据b的上游数据,同时数据b是数据a的下游数据。按血缘对象来分,可分为系统级血缘、表级血缘、字段(列)级血缘。
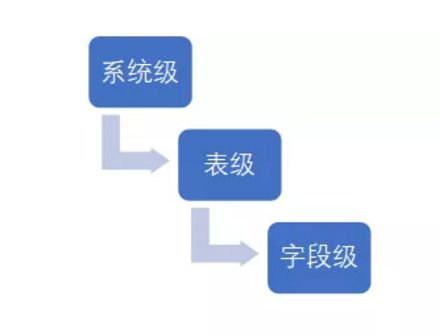
了解了什么是数据的血缘,下面我们将更深一步地了解该如何去梳理数据血缘。
梳理数据血缘的方法主要可以归为三类:
1. 自动解析:通过解析数据加工流转中的SQL语句、存储过程、ETL过程等,举个简单的例子
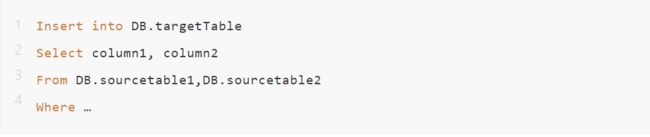
程序自动解析这段sql语句,通过from、into等关键字,判断出targetTable是由sourcetable1和sourcetable2生成而来的,同样column1和column2又是从哪几个字段运算得出的。
2. 系统跟踪:这种方法是根据一定规则,在数据加工流转过程中直接由加工主体完成血缘关系的映射,这种方法效率最高,但是开发难度也较高。
3. 手工梳理:是指技术人员手工对血缘关系进行梳理,效率比较低而且难度比较高。但却也是血缘分析中必不可少的一种方法。
当然,对于现在成熟的企业来说,光系统就动辄几十,上百个,靠纯手工梳理如同愚公移山,不现实。因此血缘关系的自动解析就显得尤为重要。现在已有很多成熟的方案,这里简单介绍一个工具:
亿信华辰的元数据管理内置丰富的采集适配器,端到端的自动化采集,一键元数据分析,快速理清数据资源,了解数据来龙去脉,构建数据地图,为数据标准建设和数据质量提供基础支撑。

平台内置丰富的适配器,全面保障各类源头的元数据自动化采集,一键采集对接,同时可支持适配器快速扩展。

血缘分析的价值
现在,我们已经了解了梳理数据血缘的方法,但其实在实际工作中,这部分工作是由技术部门来实现的。那实现了数据血缘,对于业务人员又有什么实际的好处呢?
我们回到开头的场景,有了血缘分析,小B可以快速地了解出错的数据是经过哪些系统,哪些字段生成的,从而快速定位到是哪个环节导致的数据不正确;而小C也可以通过血缘分析(如下图所示)了解数据的来龙去脉,快速便捷地理解数据,简化工作流程。

(“存款类资产”及“非存款类资产”等信息的数据血缘)
工程师小D也能快速而又准确的找到自己变更表所影响的下游表,及时通知相关用户。这些场景其实分别对应了数据血缘应用中的的异常定位、血缘跟踪和影响分析。当然,数据血缘的应用场景远不止如此,在监管报送、质量检验、评估数据价值等方面也都有着广泛的应用。
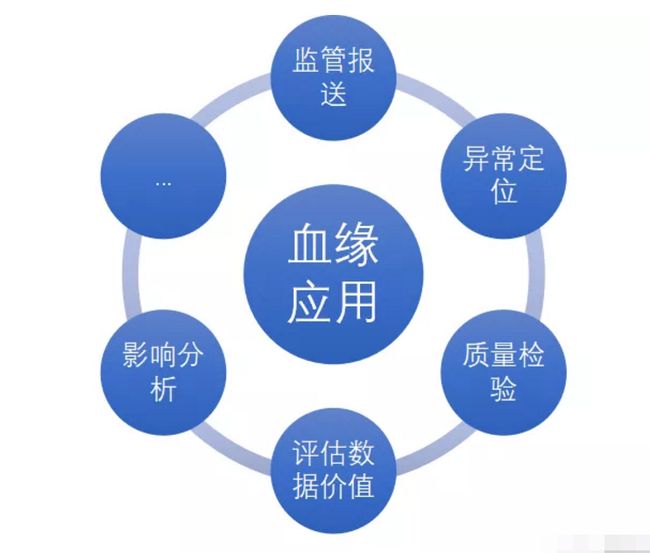
(血缘分析的应用)
我们生活在一个数据的时代,我们产生数据,同时也依赖数据。面对这海量的、质量参差不齐的数据,元数据管理便显得尤为重要,而数据血缘分析作为元数据应用之一,也同样需要我们重视并利用起来。因此,对于数据的血缘关系,我们要确保每个环节都注意数据质量的检测和处理,让数据为我们更好地服务、创造价值,华宇智能数据(www.thunidata.com)为你全面提供银行业的的数据治理解决方案。