三、多层感知机及模型优化
文章目录
- 前言
- 一、多层感知机
-
- 1.1 隐藏层
-
- 1.1.1 什么叫隐藏层
- 1.1.2 为什么需要隐藏层
- 1.2 激活函数
-
- 1.2.1 ReLU函数
- 1.2.2 Sigmoid函数
- 1.2.3 tanh函数
- 1.3 多层感知机的代码实现
- 二、模型选择、欠拟合和过拟合
-
- 2.1 训练误差和泛化误差
- 2.2 模型选择
-
- 2.2.1 模型复杂性
- 2.2.2 验证集
- 2.2.3 K折交叉验证
- 2.3 欠拟合与过拟合
- 2.4. 多项式回归
- 三、权重衰减(L2正则化)
-
- 3.1 解释
- 3.2 高维线性回归
-
- 3.2.1 生成数据
- 3.2.2 从零开始实现
- 3.2.3 简洁实现
- 四、暂退法(Dropout)
-
- 4.1 重新审视过拟合
- 4.2 扰动的稳健性(鲁棒性)
- 4.3 手动实现暂退法
- 4.4 简洁实现
- 五、前向传播与反向传播
-
- 5.1 前向传播
- 5.2 反向传播
- 5.3 神经网络中前向传播与反向传播
- 六、数值稳定性和模型初始化
-
- 6.1 梯度消失和梯度爆炸
-
- 6.1.1 梯度消失
- 6.1.2 梯度爆炸
- 6.1.3 参数对称性
- 6.2 参数初始化
-
- 6.2.1 默认初始化
- 6.2.2 Xavier 初始化
- 七、环境和分布偏移
- 八、房价预测Kaggle实战
- 总结
前言
前面我们讲解了单层的神经网络,这章我们将开始探索深度神经网络。
一、多层感知机
1.1 隐藏层
1.1.1 什么叫隐藏层
在输入层与输出层之间的层被称为隐藏层,结构图如下:
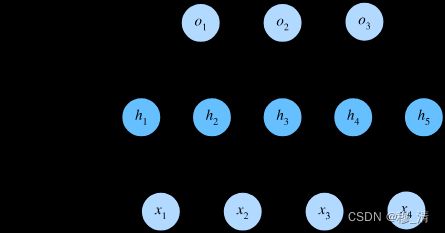
其中有4个输入,3个输出,隐藏层有5个隐藏单元。
1.1.2 为什么需要隐藏层
主要由以下原因:
-
学习非线性关系:隐藏层可以通过学习非线性一般性函数来学习数据的复杂关系。如果没有隐藏层,模型将只能学习到数据的线性关系。(通常要加激活函数)
-
增强模型健壮性: 如果没有隐藏层,模型可能过于简单,容易出现过度拟合的情况。隐藏层的存在可以帮助模型更好地适应数据,也能提高模型的健壮性。
-
提高精度: 隐藏层可以提高模型对输入特征的提取和抽象,从而提高模型的预测精度。
-
减少特征数量: 隐藏层可以对输入特征进行压缩和降维,将数据从高维度的输入转化为低维度的隐藏层特征,使得输入数据在模型计算时更显得具有可解释性和可处理。
因此,隐藏层在神经网络中扮演着关键的作用,它们可以帮助神经网络更好地学习数据,并提高模型的性能。
1.2 激活函数
激活函数(activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。 由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
1.2.1 ReLU函数
最受欢迎的激活函数是修正线性单元(Rectified linear unit,ReLU), 因为它实现简单,同时在各种预测任务中表现良好。 ReLU提供了一种非常简单的非线性变换。 给定元素,ReLU函数被定义为该元素与的最大值:
ReLU ( x ) = max ( x , 0 ) . \operatorname{ReLU}(x) = \max(x, 0). ReLU(x)=max(x,0).
import torch
from torch.nn as nn
from torch.nn.functional as F
torch.relu(x)
nn.ReLu() #定义relu函数 可直接放入Sequential中
y = F.relu(x)

使用ReLU的原因是,它求导表现得特别好:要么让参数消失,要么让参数通过。 这使得优化表现得更好,并且ReLU减轻了困扰以往神经网络的梯度消失问题(稍后将详细介绍)。
1.2.2 Sigmoid函数
对于一个定义域在中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
sigmoid ( x ) = 1 1 + exp ( − x ) . \operatorname{sigmoid}(x) = \frac{1}{1 + \exp(-x)}. sigmoid(x)=1+exp(−x)1.

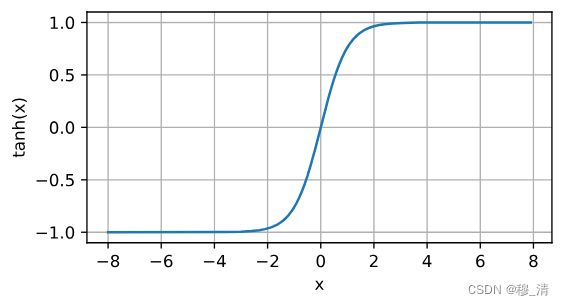
1.2.3 tanh函数
与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
tanh ( x ) = 1 − exp ( − 2 x ) 1 + exp ( − 2 x ) . \operatorname{tanh}(x) = \frac{1 - \exp(-2x)}{1 + \exp(-2x)}. tanh(x)=1+exp(−2x)1−exp(−2x).
1.3 多层感知机的代码实现
import torch
from torch import nn
from d2l import torch as d2l
# 获取数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
##定义模型
# PyTorch不会隐式地调整输入的形状。因此,
# 我们在线性层前定义了展平层(flatten),来调整网络输入的形状,softmax无需加
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
## 初始化参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 定义损失函数 已经融入softmax
loss = nn.CrossEntropyLoss(reduction="none")
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练
num_epochs = 10
if __name__ == "__main__":
for epoch in range(num_epochs):
acc = 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
trainer.zero_grad()
l.mean().backward() #反向传播只能对标量进行反向传播
trainer.step()
print(l.mean())
for X, y in test_iter: #测试
net.eval()
y_hat = net(X)
print(y_hat[0].reshape(1,-1).argmax(dim=1),y[0])
print(y_hat[1].reshape(1,-1).argmax(dim=1),y[1])
二、模型选择、欠拟合和过拟合
2.1 训练误差和泛化误差
在机器学习中,训练误差和泛化误差是两个非常重要的概念。
训练误差是指模型在训练数据集上的误差。当我们前向传播输入数据时,模型会根据目标和梯度下降算法对训练数据进行优化,从而在训练数据集上产生一个误差。这个误差可以用来评估模型对训练数据的匹配程度。
然而,模型在训练数据集上表现良好不一定意味着它在新数据集上也表现良好。在真实的情况下,我们希望模型可以推广到不包含在训练数据集中的新数据。泛化误差是指模型在新数据集上的误差。泛化误差往往是我们最关注的指标,因为它更接近实际情况。
通常,我们希望训练误差和泛化误差都足够低。但是,如果模型过度拟合训练数据集,它很可能会在新数据集上表现不佳。为了避免这种情况,我们需要注意控制模型的复杂性并使用一些常见的技术,例如交叉验证和正则化,来优化模型的泛化性能。
2.2 模型选择
2.2.1 模型复杂性
具有更多参数的模型可能被认为更复杂, 参数有更大取值范围的模型可能更为复杂。 通常对于神经网络,我们认为需要更多训练迭代的模型比较复杂, 而需要早停(early stopping)的模型(即较少训练迭代周期)就不那么复杂。
几个倾向于影响模型泛化的因素。
-
可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。
-
参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
-
训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
2.2.2 验证集
我们不能依靠测试数据进行模型的选择,因为那样容易过拟合测试数据,我们也不能仅依靠训练数据,因为我们无法估计训练数据的泛化误差。
解决方案:
增加一个验证数据集,也叫验证集。
2.2.3 K折交叉验证
当我们的训练数据太少,不足以构成一个合适的验证集时,我们可以采取K折交叉验证。
步骤:
- 将 原始数据分成K个不重叠的子集。
- 执行K次模型训练和验证,每次在K-1个子集中训练,剩下一个子集作验证。
- 取K次的实验结果取平均来估计训练和验证误差。
2.3 欠拟合与过拟合
- 欠拟合:训练误差和验证误差都很大,但是他们之间没啥差距,这意味着模型过于简单,无法充分捕获特征,这种现象称为欠拟合。
- 过拟合:当我们的训练误差明显低于验证误差时,我们称之为过拟合。过拟合并不总是一件坏事,我们主要关注验证误差,而不是训练误差与验证误差之间的差距。
影响两者的主要因素:
-
模型复杂度:

-
数据集大小:
对于同一模型来说,训练数据集中的样本越少,我们就越有可能(且更严重地)过拟合。 随着训练数据量的增加,泛化误差通常会减小。
通常简单的数据我们采用简单的模型,复杂的数据采用复杂的模型,更多的数据一般不会有什么坏处。
2.4. 多项式回归
import torch
import numpy as np
import math
from torch import nn
from d2l import torch as d2l
'''
生成数据集
'''
max_degree = 20 #多项式的最大阶数
n_train, n_test = 100, 100 #训练集 测试集数量
true_w = np.zeros(max_degree)
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
features = np.random.normal(size=(n_train+n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1)) #平方
for i in range(max_degree): #把阶乘纳入到自变量中 以防止自变量过大
poly_features[:, i] /= math.gamma(i + 1)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape) #加入高斯噪声
'''
转换数据类型到tensor
'''
true_w, features, poly_features, labels = [torch.tensor(x, dtype=torch.float32)
for x in [true_w, features, poly_features, labels]]
poly_features
'''
评估损失函数
'''
def evaluate_loss(net, data_iter, loss): #@save
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
'''
训练函数
'''
def train(train_features, test_features, train_labels, test_labels, num_epochs = 400):
loss = nn.MSELoss(reduction='none') #定义损失函数
input_shape = train_features.shape[-1] #定义模型
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)), batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)), batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=0.01) #定义优化器
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
-
正常情况:
''' 正常情况 ''' train(poly_features[:n_train,:4], poly_features[n_test:, :4], labels[:n_train], labels[n_train:])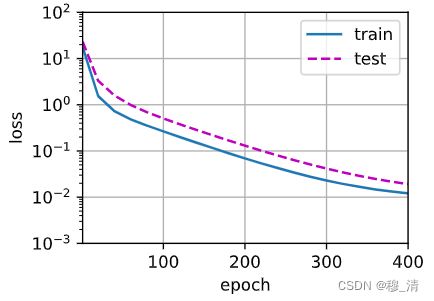
-
欠拟合:
train(poly_features[:n_train, :2], poly_features[n_train:, :2], labels[:n_train], labels[n_train:])
模型过于简单(参数少),导致学不全。- 过拟合:
# 从多项式特征中选取所有维度 train(poly_features[:n_train, :], poly_features[n_train:, :], labels[:n_train], labels[n_train:], num_epochs=400)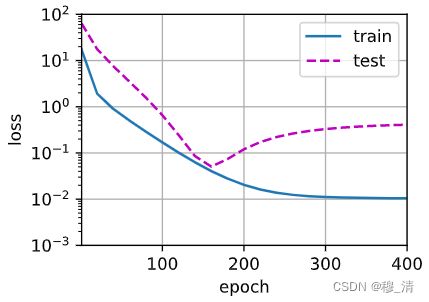
上面就是模型复杂(参数多),数据简单而导致的过拟合,它把很多噪声给学走了。
三、权重衰减(L2正则化)
3.1 解释
权重衰减也被称为 L2 正则化。它通过添加一个惩罚项 (通常是权重的平方和乘以一个常数) 到损失函数中来限制模型的复杂度,避免过拟合现象的出现。权重衰减通过限制参数的大小,使得模型更加平滑和简单,以此来降低模型对训练数据的过拟合程度。
-
硬性限制:
min ℓ ( w , b ) subject to ∥ w ∥ 2 ≤ θ \min\ell(\mathbf{w},b)\quad\text{subject to}\quad\|\mathbf{w}\|^2\leq\theta minℓ(w,b)subject to∥w∥2≤θ
通常不会去限制b(没啥用)
小的 θ \theta θ 意味着更强的正则项 -
柔性限制:
L ( w , b ) + λ 2 ∥ w ∥ 2 , L(\mathbf{w}, b) + \frac{\lambda}{2} \|\mathbf{w}\|^2, L(w,b)+2λ∥w∥2,
可通过拉格朗日乘数法来证明
λ = 0 \lambda=0 λ=0:无作用
若改成柔性限制,那么优化算法中的式子将会变化:
- 计算梯度:
∂ ∂ w ( ℓ ( w , b ) + λ 2 ∥ w ∥ 2 ) = ∂ ℓ ( w , b ) ∂ w + λ w \frac{\partial}{\partial\mathbf{w}}\left(\ell(\mathbf{w},b)+\frac{\lambda}{2}\|\mathbf{w}\|^2\right)=\frac{\partial\ell(\mathbf{w},b)}{\partial\mathbf{w}}+\lambda\mathbf{w} ∂w∂(ℓ(w,b)+2λ∥w∥2)=∂w∂ℓ(w,b)+λw - 迭代梯度:
w t + 1 = ( 1 − η λ ) w t − η ∂ ℓ ( w t , b t ) ∂ w t \mathbf{w}_{t+1}=(1-\eta\lambda)\mathbf{w}_t-\eta\frac{\partial\ell(\mathbf{w}_t,b_t)}{\partial\mathbf{w}_t} wt+1=(1−ηλ)wt−η∂wt∂ℓ(wt,bt)
由于迭代的途中梯度会变小(通常 η λ < 1 \eta\lambda < 1 ηλ<1),故称为梯度衰减。
3.2 高维线性回归
生成公式如下:
y = 0.05 + ∑ i = 1 d 0.01 x i + ϵ where ϵ ∼ N ( 0 , 0.0 1 2 ) . y = 0.05 + \sum_{i = 1}^d 0.01 x_i + \epsilon \text{ where } \epsilon \sim \mathcal{N}(0, 0.01^2). y=0.05+i=1∑d0.01xi+ϵ where ϵ∼N(0,0.012).
为了使过拟合效果更佳,我们使d=200,同时我们让测试集数量变少,让模型关注噪点,从而实现更加明显的过拟合。
3.2.1 生成数据
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2l
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
3.2.2 从零开始实现
'''
初始化模型参数
'''
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
'''
定义惩罚项
'''
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2
'''
训练
'''
def train(lambd):
w, b = init_params()
net, loss = lambda X : d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward()
d2l.sgd([w, b], lr, batch_size)
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数是:', torch.norm(w).item())
- 不加正则项:
'''
忽略正则项
'''
train(lambd=0)

- 添加正则项:
'''
添加正则项
'''
train(lambd=10)

3.2.3 简洁实现
def train_concise(wd):
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 偏置参数没有衰减
trainer = torch.optim.SGD([
{"params":net[0].weight,'weight_decay': wd},
{"params":net[0].bias}], lr=lr)
animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log',
xlim=[5, num_epochs], legend=['train', 'test'])
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
if (epoch + 1) % 5 == 0:
animator.add(epoch + 1,
(d2l.evaluate_loss(net, train_iter, loss),
d2l.evaluate_loss(net, test_iter, loss)))
print('w的L2范数:', net[0].weight.norm().item())
效果如上。
pytorch把权重衰减加到了优化算法中,他能与任何损失函数结合,并且能够不增加额外的计算开销。
四、暂退法(Dropout)
4.1 重新审视过拟合
当面对更多特征而样本不足时,线性模型往往会过拟合。而更多样本少特征,线性模型往往不会过拟合。
即使我们有比特征多得多的样本,深度神经网络也有可能过拟合。
4.2 扰动的稳健性(鲁棒性)
什么是一个好的预测模型?
模型以简单为目标,简单性以较小维度形式以及平滑性所体现,不应该对输入微小的变化敏感。
解决办法:手动对层加入噪声而其期望,而该层的总体期望不变进行训练,该法称为暂退法。
h ′ = { 0 概率为 p h 1 − p 其他情况 \begin{split}\begin{aligned} h' = \begin{cases} 0 & \text{ 概率为 } p \\ \frac{h}{1-p} & \text{ 其他情况} \end{cases} \end{aligned}\end{split} h′={01−ph 概率为 p 其他情况
E [ h ′ ] = h E[h'] = h E[h′]=h 即期望值不变。

h = σ ( W 1 x + b 1 ) h ′ = d r o p o u t ( h ) o = W 2 h ′ + b 2 y = softmax ( o ) \begin{aligned} & \textbf{h}=\sigma(\textbf{W}_1\textbf{x}+\textbf{b}_1) \\ &\mathbf{h}'=\mathsf{dropout(h)} \\ &\textbf{o}=\textbf{W}_2\textbf{h}'+\textbf{b}_2 \\ &\textbf{y}=\textsf{softmax}(\textbf{o}) \\ & \end{aligned} h=σ(W1x+b1)h′=dropout(h)o=W2h′+b2y=softmax(o)
4.3 手动实现暂退法
import torch
import torch.nn as nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float() #创建一个掩膜
return mask * X / (1.0 - dropout) #以概率p过滤掉部分像素 剩下像素进行增强
'''
定义模型参数
'''
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
'''
定义模型
'''
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
if self.training == True: #只有训练模式才进行dropout
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
'''
训练
'''
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

4.4 简洁实现
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

五、前向传播与反向传播
5.1 前向传播
前向传播(forward propagation或forward pass) 指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
-
初始:
z = W ( 1 ) x \mathbf{z}= \mathbf{W}^{(1)} \mathbf{x} z=W(1)x -
加激活函数:
h = ϕ ( z ) . \mathbf{h}= \phi (\mathbf{z}). h=ϕ(z). -
第二个线性变换:
o = W ( 2 ) h . \mathbf{o}= \mathbf{W}^{(2)} \mathbf{h}. o=W(2)h. -
损失函数:
L = l ( o , y ) . L = l(\mathbf{o}, y). L=l(o,y). -
L2正则化:
s = λ 2 ( ∥ W ( 1 ) ∥ F 2 + ∥ W ( 2 ) ∥ F 2 ) , s = \frac{\lambda}{2} \left(\|\mathbf{W}^{(1)}\|_F^2 + \|\mathbf{W}^{(2)}\|_F^2\right), s=2λ(∥W(1)∥F2+∥W(2)∥F2), -
最终目标函数:
J = L + s . J = L + s. J=L+s.
前向传播计算图:
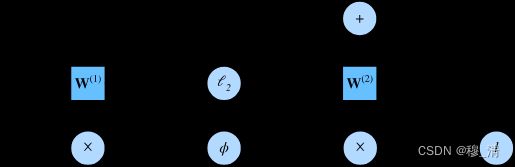
5.2 反向传播
反向传播(backward propagation或backpropagation) 指的是计算神经网络参数梯度的方法。 简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。 该算法存储了计算某些参数梯度时所需的任何中间变量(偏导数)。
在上述计算图中,我们反向传播的目的是为了计算 ∂ J / ∂ W ( 1 ) \partial J/\partial \mathbf{W}^{(1)} ∂J/∂W(1)与 ∂ J / ∂ W ( 2 ) \partial J/\partial \mathbf{W}^{(2)} ∂J/∂W(2)。
-
计算目标函数 J = L + s J = L + s J=L+s相对于L与s的梯度:
∂ J ∂ L = 1 and ∂ J ∂ s = 1. \frac{\partial J}{\partial L} = 1 \; \text{and} \; \frac{\partial J}{\partial s} = 1. ∂L∂J=1and∂s∂J=1. -
根据链式求导法则计算o的梯度(其中的prod是一种调整(换位和交换)后再相乘的运算):
∂ J ∂ o = prod ( ∂ J ∂ L , ∂ L ∂ o ) = ∂ L ∂ o ∈ R q . \frac{\partial J}{\partial \mathbf{o}} = \text{prod}\left(\frac{\partial J}{\partial L}, \frac{\partial L}{\partial \mathbf{o}}\right) = \frac{\partial L}{\partial \mathbf{o}} \in \mathbb{R}^q. ∂o∂J=prod(∂L∂J,∂o∂L)=∂o∂L∈Rq. -
计算正则项的两个参数梯度:
∂ s ∂ W ( 1 ) = λ W ( 1 ) and ∂ s ∂ W ( 2 ) = λ W ( 2 ) . \frac{\partial s}{\partial \mathbf{W}^{(1)}} = \lambda \mathbf{W}^{(1)} \; \text{and} \; \frac{\partial s}{\partial \mathbf{W}^{(2)}} = \lambda \mathbf{W}^{(2)}. ∂W(1)∂s=λW(1)and∂W(2)∂s=λW(2). -
计算 ∂ J / ∂ W ( 2 ) ∈ R q × h \partial J/\partial \mathbf{W}^{(2)} \in \mathbb{R}^{q \times h} ∂J/∂W(2)∈Rq×h:
∂ J ∂ W ( 2 ) = prod ( ∂ J ∂ o , ∂ o ∂ W ( 2 ) ) + prod ( ∂ J ∂ s , ∂ s ∂ W ( 2 ) ) = ∂ J ∂ o h ⊤ + λ W ( 2 ) . \frac{\partial J}{\partial \mathbf{W}^{(2)}}= \text{prod}\left(\frac{\partial J}{\partial \mathbf{o}}, \frac{\partial \mathbf{o}}{\partial \mathbf{W}^{(2)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \mathbf{W}^{(2)}}\right)= \frac{\partial J}{\partial \mathbf{o}} \mathbf{h}^\top + \lambda \mathbf{W}^{(2)}. ∂W(2)∂J=prod(∂o∂J,∂W(2)∂o)+prod(∂s∂J,∂W(2)∂s)=∂o∂Jh⊤+λW(2). -
计算 ∂ J / ∂ h ∈ R h \partial J/\partial \mathbf{h} \in \mathbb{R}^h ∂J/∂h∈Rh:
∂ J ∂ h = prod ( ∂ J ∂ o , ∂ o ∂ h ) = W ( 2 ) ⊤ ∂ J ∂ o . \frac{\partial J}{\partial \mathbf{h}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{o}}, \frac{\partial \mathbf{o}}{\partial \mathbf{h}}\right) = {\mathbf{W}^{(2)}}^\top \frac{\partial J}{\partial \mathbf{o}}. ∂h∂J=prod(∂o∂J,∂h∂o)=W(2)⊤∂o∂J. -
由于激活函数是按元素计算的, 计算中间变量的梯度需要使用按元素乘法运算符,我们用表示:
∂ J ∂ z = prod ( ∂ J ∂ h , ∂ h ∂ z ) = ∂ J ∂ h ⊙ ϕ ′ ( z ) . \frac{\partial J}{\partial \mathbf{z}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{h}}, \frac{\partial \mathbf{h}}{\partial \mathbf{z}}\right) = \frac{\partial J}{\partial \mathbf{h}} \odot \phi'\left(\mathbf{z}\right). ∂z∂J=prod(∂h∂J,∂z∂h)=∂h∂J⊙ϕ′(z). -
计算 ∂ J / ∂ W ( 1 ) ∈ R h × d \partial J/\partial \mathbf{W}^{(1)} \in \mathbb{R}^{h \times d} ∂J/∂W(1)∈Rh×d:
∂ J ∂ W ( 1 ) = prod ( ∂ J ∂ z , ∂ z ∂ W ( 1 ) ) + prod ( ∂ J ∂ s , ∂ s ∂ W ( 1 ) ) = ∂ J ∂ z x ⊤ + λ W ( 1 ) . \frac{\partial J}{\partial \mathbf{W}^{(1)}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{z}}, \frac{\partial \mathbf{z}}{\partial \mathbf{W}^{(1)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \mathbf{W}^{(1)}}\right) = \frac{\partial J}{\partial \mathbf{z}} \mathbf{x}^\top + \lambda \mathbf{W}^{(1)}. ∂W(1)∂J=prod(∂z∂J,∂W(1)∂z)+prod(∂s∂J,∂W(1)∂s)=∂z∂Jx⊤+λW(1).
5.3 神经网络中前向传播与反向传播
在神经网络中前向传播的模型参数依赖与反向传播所更新的值,而反向传播又依赖前向传播的变量值。
注:反向传播会重复利用前向传播中存储的中间值,以避免重复计算,因此也会占用更多的内存。
理解:在深度学习中,训练神经网络时通常使用反向传播算法来更新网络中的权重参数,从而最小化损失函数。反向传播算法需要计算损失函数对权重参数的导数,以此来更新权重参数。而这个导数的计算过程中,需要利用前向传播过程中的中间值,尤其是各个层的节点输入和节点输出。
因为前向传播过程中每个神经元的输入和输出都已经被计算出来了,所以这些值可以直接用来计算反向传播中的导数。这样就可以避免反向传播中重复计算一些相同的值,节省了计算时间,提高了效率。
因此,反向传播会重复利用前向传播中存储的中间值,这也是反向传播算法在深度学习中被广泛应用的原因之一。
六、数值稳定性和模型初始化
初始化模型参数很重要,我们前面的例子中基本上都是用某个分布来初始化参数,它的选择通常和激活函数的选择结合在一起,合理的选择两者,能够有效的提升优化算法收敛的速度,而糟糕的选择可能会导致梯度爆炸火梯度消失。
6.1 梯度消失和梯度爆炸
考虑一个具有L层,输入x和输出o的深层网络,其中隐藏h。因此网络可以表示为:
h ( l ) = f l ( h ( l − 1 ) ) 因此 o = f L ∘ … ∘ f 1 ( x ) . \mathbf{h}^{(l)} = f_l (\mathbf{h}^{(l-1)}) \text{ 因此 } \mathbf{o} = f_L \circ \ldots \circ f_1(\mathbf{x}). h(l)=fl(h(l−1)) 因此 o=fL∘…∘f1(x).
我们可以将 o \mathbf{o} o关于任何一组参数的 W ( l ) \mathbf{W}^{(l)} W(l)梯度写为下式:
∂ W ( l ) o = ∂ h ( L − 1 ) h ( L ) ⏟ M ( L ) = d e f ⋅ … ⋅ ∂ h ( l ) h ( l + 1 ) ⏟ M ( l + 1 ) = d e f ∂ W ( l ) h ( l ) ⏟ v ( l ) = d e f . \partial_{\mathbf{W}^{(l)}} \mathbf{o} = \underbrace{\partial_{\mathbf{h}^{(L-1)}} \mathbf{h}^{(L)}}_{ \mathbf{M}^{(L)} \stackrel{\mathrm{def}}{=}} \cdot \ldots \cdot \underbrace{\partial_{\mathbf{h}^{(l)}} \mathbf{h}^{(l+1)}}_{ \mathbf{M}^{(l+1)} \stackrel{\mathrm{def}}{=}} \underbrace{\partial_{\mathbf{W}^{(l)}} \mathbf{h}^{(l)}}_{ \mathbf{v}^{(l)} \stackrel{\mathrm{def}}{=}}. ∂W(l)o=M(L)=def ∂h(L−1)h(L)⋅…⋅M(l+1)=def ∂h(l)h(l+1)v(l)=def ∂W(l)h(l).
因为是乘积所以会导致梯度很大,也可能很小。而不稳定的梯度威胁到我们优化算法的稳定性。要么是梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛; 要么是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
6.1.1 梯度消失
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))
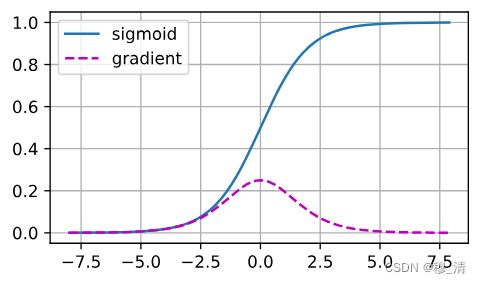
当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。因此,更稳定的ReLU系列函数已经成为从业者的默认选择。
6.1.2 梯度爆炸
相反,梯度爆炸可能同样令人烦恼。 为了更好地说明这一点,我们生成100个高斯随机矩阵,并将它们与某个初始矩阵相乘。 对于我们选择的尺度(方差 σ 2 = 1 \sigma^2=1 σ2=1),矩阵乘积发生爆炸。 当这种情况是由于深度网络的初始化所导致时,我们没有机会让梯度下降优化器收敛。
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)
结果:
一个矩阵
tensor([[ 1.1677, 0.3804, -0.7343, -1.8798],
[ 0.5325, -2.4282, 0.2886, 0.0961],
[-0.6474, -1.2622, -0.0183, -0.0958],
[-0.9811, 0.9840, -1.4430, 0.1905]])
乘以100个矩阵后
tensor([[-2.0338e+22, -1.2461e+21, 1.6642e+22, 1.4078e+21],
[ 1.4095e+22, 8.6345e+20, -1.1534e+22, -9.7620e+20],
[ 3.1960e+22, 1.9580e+21, -2.6153e+22, -2.2129e+21],
[ 9.7268e+21, 5.9587e+20, -7.9593e+21, -6.7356e+20]])
6.1.3 参数对称性
在神经网络中,参数对称性指的是网络中两个或多个参数具有相同的取值,这会导致网络的重复性和冗余性。在训练神经网络时,如果存在参数对称性,可能会导致梯度更新相互抵消,从而导致网络训练缓慢或无法收敛。因此,为了避免参数对称性,通常会使用一些技巧,例如随机初始化权重,使用不同的激活函数等。这些技巧可以帮助网络更快地学习特征,并且能够更好地区分不同的类别。
6.2 参数初始化
解决参数对称性的一个方案就是参数初始化。
6.2.1 默认初始化
在前面的案例中我们常常使用正态分布来初始化参数。如果我们在模型中不指定初始化方法,框架将会 使用默认的随机初始化方法,对于中等难度的问题,这种方法很有效。
6.2.2 Xavier 初始化
- 将每一层的输出和梯度都看作随机变量
- 让他们的均值和方差都保持一致
具体来说:
- 正向:
E [ h i t ] = 0 Var [ h i t ] = a \begin{aligned} \mathbb{E}[h_i^t]& =0 \\ \text{Var}[h_i^t]& =a \end{aligned} E[hit]Var[hit]=0=a - 反向:
E [ ∂ ℓ ∂ h i t ] = 0 Var [ ∂ ℓ ∂ h i t ] = b ∀ i , t \mathbb{E}\left[\frac{\partial\ell}{\partial h_i^t}\right]=0\quad\text{Var}\left[\frac{\partial\ell}{\partial h_i^t}\right]=b\quad\forall i,t E[∂hit∂ℓ]=0Var[∂hit∂ℓ]=b∀i,t
其中t表示层数,i表示该层的任意一个值,用 h i h_i hi表示该层随机变量。
假设第i层的输出公式如下:
o i = ∑ j = 1 n i n w i j x j . o_{i} = \sum_{j=1}^{n_\mathrm{in}} w_{ij} x_j. oi=j=1∑ninwijxj.
那么其均值与方差如下:
E [ o i ] = ∑ j = 1 n i n E [ w i j x j ] = ∑ j = 1 n i n E [ w i j ] E [ x j ] = 0 , V a r [ o i ] = E [ o i 2 ] − ( E [ o i ] ) 2 = ∑ j = 1 n i n E [ w i j 2 x j 2 ] − 0 = ∑ j = 1 n i n E [ w i j 2 ] E [ x j 2 ] = n i n σ 2 γ 2 . \begin{split}\begin{aligned} E[o_i] & = \sum_{j=1}^{n_\mathrm{in}} E[w_{ij} x_j] \\&= \sum_{j=1}^{n_\mathrm{in}} E[w_{ij}] E[x_j] \\&= 0, \\ \mathrm{Var}[o_i] & = E[o_i^2] - (E[o_i])^2 \\ & = \sum_{j=1}^{n_\mathrm{in}} E[w^2_{ij} x^2_j] - 0 \\ & = \sum_{j=1}^{n_\mathrm{in}} E[w^2_{ij}] E[x^2_j] \\ & = n_\mathrm{in} \sigma^2 \gamma^2. \end{aligned}\end{split} E[oi]Var[oi]=j=1∑ninE[wijxj]=j=1∑ninE[wij]E[xj]=0,=E[oi2]−(E[oi])2=j=1∑ninE[wij2xj2]−0=j=1∑ninE[wij2]E[xj2]=ninσ2γ2.
若要其方差保持不变,则 n i n σ 2 = 1 n_\mathrm{in} \sigma^2 = 1 ninσ2=1且 n o u t σ 2 = 1 n_\mathrm{out} \sigma^2 = 1 noutσ2=1,我们可令:
1 2 ( n i n + n o u t ) σ 2 = 1 或等价于 σ = 2 n i n + n o u t . \begin{aligned} \frac{1}{2} (n_\mathrm{in} + n_\mathrm{out}) \sigma^2 = 1 \text{ 或等价于 } \sigma = \sqrt{\frac{2}{n_\mathrm{in} + n_\mathrm{out}}}. \end{aligned} 21(nin+nout)σ2=1 或等价于 σ=nin+nout2.
通常我们可以采用指定高斯分布来初始化参数:
μ = 0 , σ 2 = 2 n i n + n o u t \mu = 0,\sigma^2 = \frac{2}{n_\mathrm{in} + n_\mathrm{out}} μ=0,σ2=nin+nout2
也可采用均匀分布U(-a, a)的方差为 a 2 3 \frac{a^2}{3} 3a2,令其等于 σ 2 \sigma^2 σ2,解出a,即:
U ( − 6 n i n + n o u t , 6 n i n + n o u t ) . U\left(-\sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}, \sqrt{\frac{6}{n_\mathrm{in} + n_\mathrm{out}}}\right). U(−nin+nout6,nin+nout6).
七、环境和分布偏移
暂时略过。。
八、房价预测Kaggle实战
import hashlib
import os
import tarfile
import zipfile
import requests
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
from d2l import torch as d2l
DATA_HUB = dict() # 映射数据集名称与url和密钥
DATA_URL = "http://d2l-data.s3-accelerate.amazonaws.com/"
in_features = None
"""
下载函数
"""
def download(name, cache_dir=os.path.join("..", "data")):
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split("/")[-1])
if os.path.exists(fname): # 如果文件已经存在
sha1 = hashlib.sha1()
with open(fname, "rb") as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # 已下载且文件没有被篡改
print(f"正在从{url}中下载{fname}。。。")
r = requests.get(url, stream=True, verify=True)
with open(fname, "wb") as f:
f.write(r.content)
return fname
"""
解压函数
"""
def download_extract(name, folder=None):
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == ".zip":
fp = zipfile.ZipFile(fname, "r")
elif ext in (".tar", ".gz"):
fp = tarfile.open(fname, "r")
else:
assert False, "只有zip/tar文件可以被解压缩"
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
"""下载所有数据集"""
def download_all():
for name in DATA_HUB:
download(name)
def get_net():
net = nn.Sequential(nn.Linear(in_features, 50))
return net
def log_rmse(net, features, labels):
clipped_preds = torch.clamp(net(features), 1, float("inf"))
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
"""
训练
"""
def train(
net,
train_features,
train_labels,
test_features,
test_labels,
num_epocs,
learning_rate,
weight_decay,
batch_size,
):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
optimizer = torch.optim.Adam(
net.parameters(), lr=learning_rate, weight_decay=weight_decay
)
for epoch in range(num_epocs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
"""K折交叉验证"""
def get_k_fold_data(k, i, X, y): # 分成k折,选i个切片作为验证集
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X.valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X.valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(
net, *data, num_epochs, learning_rate, weight_decay, batch_size
)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(
list(range(1, num_epochs + 1)),
[train_ls, valid_ls],
xlabel="epoch",
ylabel="rmse",
xlim=[1, num_epochs],
legend=["train", "valid"],
yscale="log",
)
print(
f"折{i + 1},训练log rmse{float(train_ls[-1]):f}, "
f"验证log rmse{float(valid_ls[-1]):f}"
)
return train_l_sum / k, valid_l_sum / k
def train_and_pred(
train_features,
test_features,
train_labels,
test_data,
num_epochs,
lr,
weight_decay,
batch_size,
):
net = get_net()
train_ls, _ = train(
net,
train_features,
train_labels,
None,
None,
num_epochs,
lr,
weight_decay,
batch_size,
)
d2l.plot(
np.arange(1, num_epochs + 1),
[train_ls],
xlabel="epoch",
ylabel="log rmse",
xlim=[1, num_epochs],
yscale="log",
)
print(f"训练log rmse:{float(train_ls[-1]):f}")
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data["SalePrice"] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data["Id"], test_data["SalePrice"]], axis=1)
submission.to_csv("submission.csv", index=False)
if __name__ == "__main__":
DATA_HUB["kaggle_house_train"] = (
DATA_URL + "kaggle_house_pred_train.csv",
"585e9cc93e70b39160e7921475f9bcd7d31219ce",
)
DATA_HUB["kaggle_house_test"] = (
DATA_URL + "kaggle_house_pred_test.csv",
"fa19780a7b011d9b009e8bff8e99922a8ee2eb90",
)
train_data = pd.read_csv(download("kaggle_house_train"))
test_data = pd.read_csv(download("kaggle_house_test"))
all_features = pd.concat((train_data.iloc[:, 1:], test_data.iloc[:, 1:]))
"""数值型特征的尺度同一"""
numeric_features = all_features.dtypes[
all_features.dtypes != "object"
].index # 寻找是数值对象的列名
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std())
) # 计算标准分数
all_features[numeric_features] = all_features[numeric_features].fillna(
0
) # 将缺失值填0 0刚好是每个特征的均值
"""离散型特征处理"""
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
"""获取数据集"""
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32
)
loss = nn.MSELoss()
in_features = train_features.shape[1]
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 15, 0, 64
train_l, valid_l = k_fold(
k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size
)
print(
f"{k}-折验证: 平均训练log rmse: {float(train_l):f}, "
f"平均验证log rmse: {float(valid_l):f}"
)
train_and_pred(
train_features,
test_features,
train_labels,
test_data,
num_epochs,
lr,
weight_decay,
batch_size,
)