MySQL性能优化(四)性能优化总结
文章目录
- 连接优化
-
- 服务端链接优化
- 客户端连接优化
- 配置的优化
- 架构优化
-
- 数据库高可用:
- 数据库慢查询
-
- 慢查询日志
- profiling工具
- 表结构和存储引擎的优化
-
- 存储引擎:
- 表结构
- SQL与索引的优化
-
- 案例- 执行计划 Explain
-
- ID序号
- select type查询类型
- `type 针对单表的访问方法`
-
- System
- Const
- eq_ref 唯一索引查询
- ref 非唯一索引查询
- range 索引范围查询
- index (full index scan)
- ALL(full table scan)全表扫描
- `possible_keys、key`
- key_len 使用的索引长度
- ref筛选数据的参考
- rows预计扫描行数
- filtered 过滤百分比
- `Extra 额外的信息`
-
- using index 覆盖索引
- using where
- using index Conditon (默认开启)
- using filesort 不能直接使用索引排序
- using temporary 使用临时表
- 优化案例
- 业务优化
- 数据库服务端状态
- 附:
MySQL数据库优化的层次和思路
MySQL数据库优化的工具
连接优化
服务端链接优化
- 服务端高并发,连接数不够可以调大连接数。
show variables like 'max_connections'
-- max_connections 151
- 适当调小链接超时时间
客户端连接优化
- 使用数据库连接池技术。MyBatis自带的连接池、Durid、Hikari。
连接池数量计算公式:connections = ((cpu_core_count * 2) + effective_spindle_count)。不宜配置过多,原因是CPU上下文切换需要消耗时间。
配置的优化
- 数据库配置
参考官方文档:https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html - 操作系统配置:磁盘阵列等。
架构优化
- 缓存(Redis)
- 数据库集群:复制技术https://dev.mysql.com/doc/refman/5.7/en/replication.html
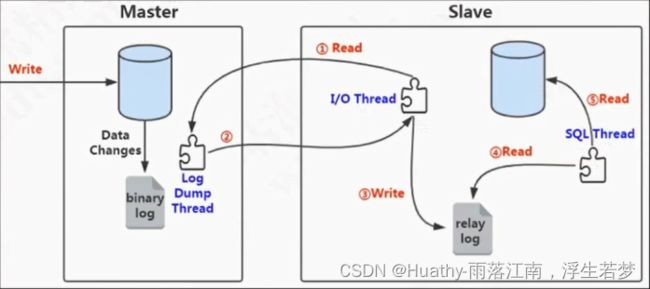
- 多数据源(读写分离):mycat、AbstractRoutingDataSource、ShardingJDBC
- 问题:同步延迟(主库并发、从库单线程导致)。解决方案1:可以采用全同步复制,但是会造成Master节点性能下降。MySQL默认是异步复制(对于Master节点来说,只要事务写入binlog提交了就会返回给客户端,并不会关心从库是否同步成功)。
- 解决同步延迟更优的方案2:半同步复制。并不是等待所有的从库都写入成功才返回,而是只要有一个从库写入relay log就返回。但是启用半同步复制需要在主从节点安装对应插件。semisync_master.so、semisync_slave.so。
install plugin rpl_semi_sync_master soname 'semisync_master.so'; show variables like '%semi_sync%' -- 默认关闭,需要手动开启- 解决同步延迟方案3:基于GTID(Global Transaction ID)复制。https://dev.mysql.com/doc/refman/5.7/en/replication-gtids.html
show variables like '%gtid_mode%' -- gtid_mode OFF -- 默认关闭需要手动开启

3. 分表:垂直分表、水平分表
4. 分库:垂直分库、水平分库
数据库高可用:
- 主从:HaProxy + Keepalived
- NDB cluster:https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-overview.html
- Galera Cluster For MySQL
- MHA:(Master-Master Replication Manager For MySQL) -> MMM:(MySQL Master High Available)
- MRG:(MySQL Group Replication)
数据库慢查询
慢查询日志
开启慢查询日志会消耗性能
-- 慢查询配置
show variables like 'slow_query%';
-- 多长时间的查询才叫慢查询
show variables like 'long_query%';
mysql慢日志分析工具
mysqldumpslow --help
whereis mysqldumpslow
profiling工具
https://dev.mysql.com/doc/refman/5.7/en/show-profile.html
select @@profiling;
set @@profiling=1;
表结构和存储引擎的优化
存储引擎:
表结构
如果能确定长度,就不要定义定长的字段,给默认值也不要允许空值。
存非文本字段,应该存储地址。而不是存储编码。仅量和业务表做拆分。
对于字段很多的表,对字段进行拆分。
也可以利用字段冗余来避免join,提升查询性能。
历史表:增长速度快。按照时间维度区分。按年月划分为12个区。
SQL与索引的优化
案例- 执行计划 Explain
更详细的explain:format=JSON
explain format=JSON select t.tname from teacher t group by tname;
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html

drop table if exists course;
create table course(
id int(3) default null,
cname varchar(20) default null,
tid int(3) default null
) engine = InnoDB default charset = utf8mb4;
drop table if exists teacher;
create table teacher(
tid int(3) default null,
tname varchar(20) default null,
tcid int(3) default null
) engine = InnoDB default charset = utf8mb4;
drop table if exists teacher_contact;
create table teacher_contact(
tcid int(3) default null,
phone varchar(20) default null
) engine = InnoDB default charset = utf8mb4;
insert into course values(1,'java','1');
insert into course values(2,'jvm','1');
insert into course values(3,'mysql','2');
insert into course values(4,'c#','2');
insert into teacher values(1,'whx',1);
insert into teacher values(2,'huathy',2);
insert into teacher_contact values(1,'QQ12341234');
insert into teacher_contact values(2,'TEL123123123');
ID序号
explain select * from teacher_contact tc where tcid = (
select t.tcid from teacher t where t.tid = (
select c.tid from course c where c.cname = 'jvm'
)
)
# 查询顺序从大到小
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra |
--+-----------+-----+----------+----+-------------+---+-------+---+----+--------+-----------+
1|PRIMARY |tc | |ALL | | | | | 2| 50.0|Using where|
2|SUBQUERY |t | |ALL | | | | | 2| 50.0|Using where|
3|SUBQUERY |c | |ALL | | | | | 4| 25.0|Using where|
explain select * from teacher t
left join teacher_contact tc on t.tcid = tc.tcid
left join course c on t.tid = c.tid
where c.id = 2 or tc.tcid = 3;
# id相同,则从上到下依次访问
id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra |
--+-----------+-----+----------+----+-------------+---+-------+---+----+--------+--------------------------------------------------+
1|SIMPLE |t | |ALL | | | | | 2| 100.0| |
1|SIMPLE |tc | |ALL | | | | | 2| 100.0|Using where; Using join buffer (Block Nested Loop)|
1|SIMPLE |c | |ALL | | | | | 4| 100.0|Using where; Using join buffer (Block Nested Loop)|
小表驱动大表:关联查询会产生临时表,应优先查询表数据少的表。
select type查询类型
- SIMPLE 简单查询
- PRIMARY 主查询
- SUBQUERY 子查询
- DERIVED 临时表
- UNION 链接查询
- UNION RESULT 链接结果
explain select t.* from (
select * from teacher where tid =1
union
select * from teacher where tid =2
) t

type 针对单表的访问方法
链接类型:从左到右,性能越来越差
system > const > eq_ref > ref > range > index > ALL
System
在Memory或MyISAM存储引擎中,只能查询到一条记录。
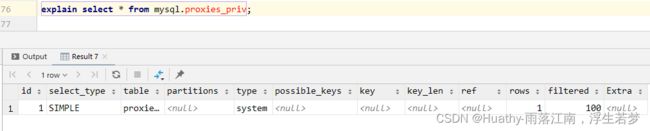
Const
主键索引或者唯一索引,只能查询到一条数据

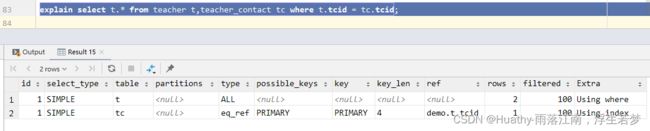
eq_ref 唯一索引查询
在join中被驱动的表,是通过唯一索引去访问的。
alter table teacher_contact add primary key (tcid);
explain select t.* from teacher t,teacher_contact tc where t.tcid = tc.tcid;
ref 非唯一索引查询
alter table teacher add index idx_teacher_tcid(tcid);
explain select t.* from teacher t where t.tcid = 1;

range 索引范围查询
alter table teacher add index idx_teacher_tid(tid);
explain select t.* from teacher t where t.tid < 3;
explain select t.* from teacher t where t.tid between 1 and 2;
explain select t.* from teacher_contact t where t.tcid in (1,2)

index (full index scan)
explain select t.tid from teacher t where t.tid
![]()
ALL(full table scan)全表扫描
explain select * from course t where t.cname = 'huathy'

possible_keys、key
possible_keys:可能使用到的索引。
key:实际使用的索引。
有没有可能possible_keys是空的而实际key有值?有可能。基于成本的优化器会存在,覆盖索引和索引条件下推的情况。
key_len 使用的索引长度
使用的索引长度。
-- username varchar(255) null,
-- utf8mb3 一个字符占3个字节 255 * 3 = 765 + 2(varchar变长) + 1(null可以为空)
-- utf8mb4 一个字符占4个字节 1020 * 4 = 765 + 2(varchar变长) + 1(null可以为空)
ref筛选数据的参考
const 表示使用参数为常量
rows预计扫描行数
InnoDB预读行数不太准确,而MyISAM统计较准。
MyISAM记录了我们的数据总行数。
如果返回行数与需要的结果相差太大,说明SQL需要优化。
filtered 过滤百分比
数据库:Server层 == 存储引擎层(InnoDB)
如果filtered为100表示返回数据都是Server层所需要的。而如果值很低,说明SQL需要优化。
Extra 额外的信息
执行计划给出的额外信息。
using index 覆盖索引
select 查询的字段,刚好在索引中。就不需要回表操作。
using where
存储引擎返回的数据不全是客户端所需要的,需要在Server层进行过滤。
using index Conditon (默认开启)
索引条件下推。本来无法利用索引。但某些条件下可以将需要查询的条件下推到存储引擎。先让存储引擎进行过滤。
using filesort 不能直接使用索引排序
不能直接使用索引排序,而是使用其他字段进行排序。

using temporary 使用临时表
得到最终需要使用临时表来存储数据。eg:在非索引字段上去重,在非索引字段上分组。

优化案例
- 在limit查询偏移量很大的时候。
select * from user_innodb limit 4000000,10; -- 4秒
select * from user_innodb where id > 4000000 limit 10; -- 0.1秒
业务优化
熔断降级。业务分流。流量削峰。
或者更换非关系的数据库,eg:Redis、MongoDB。
数据库服务端状态
show full processlist;
show status;
show engine innodb status;
附:
MySQL中文网站:https://mysql.net.cn/doc/refman/8.0/en/