- 云原生周刊丨CIO 洞察:Kubernetes 解锁 AI 新纪元
KubeSphere 云原生
云原生kubernetes人工智能
开源项目推荐DRANETDRANET是由谷歌开发的K8s网络驱动程序,利用K8s的动态资源分配(DRA)功能,为高吞吐量和低延迟应用提供高性能网络支持。它旨在优化资源管理,确保K8s集群中的网络资源能够按需高效分配。DRANET采用Apache-2.0开源许可,鼓励社区贡献与扩展,是云原生环境下提升网络性能的创新解决方案。LazyjournalLazyjournal是一个用Go语言编写的终端用户界
- 深入解析深度学习中的过拟合与欠拟合诊断、解决与工程实践
古月居GYH
深度学习人工智能
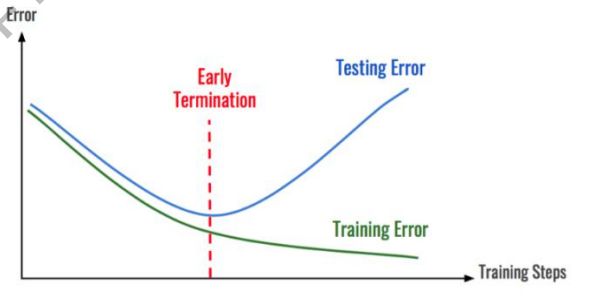
一、引言:模型泛化能力的核心挑战在深度学习模型开发中,欠拟合与过拟合是影响泛化能力的两个核心矛盾。据GoogleBrain研究统计,工业级深度学习项目中有63%的失败案例与这两个问题直接相关。本文将从基础概念到工程实践,系统解析其本质特征、诊断方法及解决方案,并辅以可复现的代码案例。二、核心概念与通熟易懂解释简单而言,欠拟合是指模型不能在训练集上获得足够低的误差。换句换说,就是模型复杂度低,模型在
- 初始OpenCV
指尖下的技术
OpenCVopencv人工智能计算机视觉
OpenCV是一个功能强大、应用广泛的计算机视觉库,它为开发人员提供了丰富的工具和算法,可以帮助他们快速构建各种视觉应用。随着计算机视觉技术的不断发展,OpenCV也将会继续发挥重要的作用。OpenCV提供了大量的计算机视觉算法和图像处理工具,广泛应用于图像和视频的处理、分析以及机器学习领域。所以学习人计算机视觉或者图像处理方面的知识,OpenCV是一个要重点学习的工具库。首先介绍一下OpenCV
- 【纯职业小组——思维】
Kent_J_Truman
蓝桥杯算法
题目思路第十五届蓝桥杯省赛PythonB组H题【纯职业小组】题解(AC)_蓝桥杯纯职业小组-CSDN博客代码#includeusingnamespacestd;usingll=longlong;intmain(){ios::sync_with_stdio(0);cin.tie(0);intt;cin>>t;while(t--){intn;llk;cin>>n>>k;unordered_maph;f
- 深入探讨盘古大模型的高精度多尺度能力
Hardess-god
WRF人工智能算法
随着人工智能技术的快速发展,大模型的研究逐渐进入新的阶段。其中,盘古大模型以其卓越的高精度和多尺度处理能力成为研究热点。本文将详细分析盘古模型在高精度多尺度问题上的技术特征、优势和应用潜力,并探讨其深入研究的方向。一、盘古模型概述盘古模型是华为推出的中文预训练大模型系列,拥有数十亿甚至千亿级的参数规模。它以Transformer架构为基础,通过海量文本数据进行训练,表现出优异的自然语言理解和生成能
- 使用Ollama部署开源大模型
好好学习 666
开源
Ollama是一个简明易用的本地大模型运行框架,可以一键启动启动并运行Llama3、Mistral、Gemma和其他大型语言模型。安装MacOS,Windows用户直接在官网下载页下载安装包即可。Linux系统运行如下命令安装curl-fsSLhttps://ollama.com/install.sh|sh使用Usage:ollama[flags]ollama[command]AvailableC
- 纯「牛马」的逻辑玩儿不转了!
求职面试职场创业创业者
又在微信群里被「声讨」了,距离上次这等待遇也过去一段时间了,让人有点「怀念」呢~(别瞎想,我不是字母!)我想此刻趁这心情还未消散殆尽,把近期一直想说但没说的话先说一遍,也暂时不管它是否严谨了,看完想吐槽就尽管来吧!麻木的纯「牛马」们在2022年11月末,ChatGPT的横空出世拉开了AI时代的帷幕,迄今为止两年多过去了,相关基础设施和上层应用已经涌现并迭代了很多版本。在这期间,很多人都至少听说过几
- 01年实习生被曝负责字节RL核心算法!系字节LLM攻坚小组成员
量子位
一个超越DeepSeekGRPO的关键RL算法出现了!用上该算法后,Qwen2.5-32B模型只经过RL训练,不引入蒸馏等其他技术,在AIME2024基准上拿下50分,优于相同setting下使用GRPO算法的DeepSeek-R1-Zero-Qwen,且DAPO使用的训练步数还减少了50%。这个算法名为DAPO,字节、清华AIR联合实验室SIALab出品,现已开源。论文通讯作者和开源项目负责人都
- 重塑家用机器人大脑!云鲸旗舰机型逍遥002搭载旭日5正式开售
量子位
2025年3月20日,全球家庭清洁机器人明星品牌云鲸智能携最新一代旗舰机型——云鲸逍遥002,亮相中国家电及消费电子博览会(AWE)。该产品以”AI智能深度清洁“为核心,基于地瓜机器人全新一代旭日5智能计算芯片,推出首创的双目AI视觉感知自适应系统,以10TOPs的端侧算力与180万点/秒的3D稠密深度点云生成能力,为家庭场景带来毫米级障碍测距精度与语义级环境理解,是家庭清洁机器人智能化演进的又一
- 量子位招聘 | DeepSeek帮我们改的招聘启事
量子位
关注前沿科技量子位未来同事,你好~这是一则招聘帖。如果你与我们志同道合,对AI大模型、具身智能、终端硬件、AI新媒体编辑感兴趣,我们正在招聘这些领域的原创作者。以下岗位均为全职,工作地点:北京中关村。岗位面向:社招、应届毕业生,所有岗位均可实习——表现出色均可转正加分项:乐于探索AI新工具,善用AI新工具;拥有解读论文的能力,能深入浅出讲解原理;有写代码能力;量子位长期读者。加入我们,你可以获得:
- 【2017-2025】Adobe Photoshop【PS】软件下载安装
adkjcbqvblq
adobephotoshopui
获取安装包https://pan.baidu.com/s/1NLUthiAyC2chlSEwbf1LRQ?pwd=4ppq1.起源与发展1.1初试啼声AdobePhotoshop的历史可以追溯到1987年,当时由托马斯·诺尔(ThomasKnoll)和他的兄弟约翰·诺尔(JohnKnoll)共同开发。托马斯在父亲的帮助下,开始了图像处理的编程尝试。他们的初始产品是一个用于Mac系统的程序,最初名为
- AI巨浪中的安全之舵:天空卫士助力人工智能落地远航
天空卫士
人工智能安全数据安全网络安全大数据
"AI时代的安全战场,不在云端在本地;数据治理的胜负手,不在防御在认知。"近期,众多企业纷纷接入DeepSeek大模型,迅速推动了大型模型应用的广泛铺开。无论是在制造业、金融业,还是在医疗、教育等领域,DeepSeek大模型的应用都如火如荼,遍地开花,展现出了其广泛的应用前景和巨大的商业价值。顺势而来的是DeepSeek一体机以"低成本、高算力、私有化部署"的优势席卷企业市场。因为DeepSeek
- DeepSeek重塑软件行业:研发工程师的机遇与挑战
LiuSid7
人工智能llama语言模型ai
人工智能技术的浪潮正以前所未有的速度重塑软件行业,而DeepSeek作为其中的代表性技术,已成为研发工程师日常工作中不可忽视的变革力量。从代码生成到架构优化,从效率提升到职业生态重构,DeepSeek正在重新定义工程师的工作范式。以下从技术革新、职业发展、行业趋势三个维度,分析其对研发工程师的核心影响。一、技术革新:从“重复劳动”到“创造力释放”代码生产的效率革命DeepSeek通过自然语言指令生
- 如何使用YOLOv8在AI-TOD数据集上进行遥感目标检测,从安装依赖项、准备数据集、配置YOLOv8、训练和评估模型以及构建GUI应用程序展示检测
计算机C9硕士_算法工程师
人工智能YOLO目标检测遥感
如何使用YOLOv8在AI-TOD数据集上进行遥感目标检测,从安装依赖项、准备数据集、配置YOLOv8、训练和评估模型以及构建GUI应用程序展示检测文章目录1.安装依赖2.数据准备3.配置YOLOv83.1加载预训练模型或自定义模型4.训练模型5.评估模型6.构建GUI应用程序(可选)以下文字及代码仅供参考。遥感目标检测,AI-TOD数据集aitod,训练集11214张,测试集集14018,验证集
- 蓝桥杯---纯职业小组(c语言)
写代码的熊萌新
蓝桥杯c语言哈希算法
问题描述在蓝桥王国,国王统治着一支由n个小队组成的强大军队。每个小队都由相同职业的士兵组成。具体地,第i个小队包含了bi名职业为ai的士兵。近日,国王计划在王宫广场举行一场盛大的士兵检阅仪式,以庆祝王国的繁荣昌盛。然而,在士兵们入场的过程中,一场突如其来的风暴打乱了他们的行列,使得不同小队的士兵混杂在一起,次序乱成一团,尽管国王无法知道每个士兵的具体职业,但为了确保仪式能顺利进行,国王打算从这些混
- 机器学习结合伏羲模型高精度多尺度气象分析与降尺度实现
Hardess-god
WRF算法人工智能
随着人工智能的发展,机器学习技术在气象预报领域展现出巨大潜力。本文详细探讨如何结合机器学习(ML)和伏羲模型进行高精度多尺度气象模拟分析,并提供详细的实现步骤和相关代码。1.研究目标与技术路线目标:结合机器学习模型与伏羲气象模式,实现区域和局地高精度降尺度。技术路线:伏羲模型提供大尺度气象数据和预报使用机器学习模型(如CNN、LSTM、XGBoost)进行降尺度2.数据准备与处理2.1气象数据获取
- 使用Python和LangChain构建检索增强生成(RAG)应用的详细指南
m0_57781768
pythonlangchain搜索引擎
使用Python和LangChain构建检索增强生成(RAG)应用的详细指南引言在人工智能和自然语言处理领域,利用大语言模型(LLM)构建复杂的问答(Q&A)系统是一个重要应用。检索增强生成(RetrievalAugmentedGeneration,RAG)是一种技术,通过将模型知识与额外数据结合来增强LLM的能力,使其能够回答关于特定源信息的问题。这些应用不仅限于公开数据,还可以处理私有数据和模
- 学习111
麋鹿叔叔
学习
项目名称项目简介主要功能技术原理GitHub地址browser-use智能浏览器工具,让AI像人类一样操作浏览器,实现网页自动化网页浏览与操作、多标签页管理、视觉识别与内容提取、操作记录与重复执行、自定义动作支持、主流LLM模型支持为大语言模型服务的创新Python工具库GitHubEkoFellouAI推出的生产就绪型JavaScript框架,基于自然语言驱动创建智能代理支持所有平台,提供统一便
- 不用再当“技术宅“!这个AI神器让我5分钟变身人工智能达人
阳光永恒736
AI工具人工智能deepseek一键包本地部署AI资源
最近我在朋友圈刷到好多朋友都在玩AI画图、AI写诗,看得我心痒痒。可每次想自己试试,打开教程就被满屏的代码吓退——"Python环境配置"、"CUDA驱动安装"这些词比数学作业还让人头疼。直到我发现了一个叫DeepSeek本地部署一键包的神器,我的AI探索之旅终于变得像搭乐高一样简单!夸克网盘分享一、原来AI离我们这么近上周三放学路上,我看见隔壁班的小美用AI给自己照片生成古风造型,这让我突然意识
- Umi-OCR 实践教程:离线、免费、高效的图像文字识别工具
几道之旅
人工智能智能体及数字员工ocr人工智能
一、工具简介Umi-OCR是一款开源、免费且支持离线运行的OCR(光学字符识别)工具,适用于Windows和Linux系统。它基于深度学习技术,能够高效提取图像中的文字,支持多语言识别、批量处理、截屏识别等功能,尤其适合对隐私敏感或网络受限的场景。核心亮点:离线运行:无需联网,保护隐私。多引擎支持:提供Paddle(高性能)和Rapid(低配兼容)两种引擎。批量处理:支持图片、PDF、电子书等多格
- 使用LangChain实现基于LLM和RAG的PDF问答系统
张同学吧
langchain语言模型
目录前言一.大语言模型(LLM)1.什么是LLM?2.LLM的能力与特点二、增强检索生成(RAG)三.什么是LangChain?1.LangChain的核心功能2.LangChain的优势3.LangChain的应用场景4.总结四.使用LangChain实现基于PDF的问答系统前言本文将介绍LLM和RAG的基本概念,并通过一个实际的代码示例,展示如何使用LangChain构建一个基于PDF文档的问
- python将网银web工程转换成客户端electron工程案例
银行金融科技
人工智能机器学习DeepSeekelectron
以下是一个将网银Web工程转换为Electron客户端的技术方案,结合Python和Electron实现桌面端增强功能:bash#项目结构webank-electron/├──main/#Electron主进程代码│├──main.js│└──python_server.py├──renderer/#网页渲染进程│└──webank-web/#原始网银Web工程├──package.json└──
- 基于ChatGPT、GIS与Python机器学习的地质灾害风险评估、易发性分析、信息化建库及灾后重建高级实践
weixin_贾
防洪评价风险评估滑坡泥石流地质灾害
第一章、ChatGPT、DeepSeek大语言模型提示词与地质灾害基础及平台介绍【基础实践篇】1、什么是大模型?大模型(LargeLanguageModel,LLM)是一种基于深度学习技术的大规模自然语言处理模型。代表性大模型:GPT-4、BERT、T5、ChatGPT等。特点:多任务能力:可以完成文本生成、分类、翻译、问答等任务。上下文理解:能理解复杂的上下文信息。广泛适配性:适合科研、教育、行
- OpenAI Deep Research 要 200 美元/月?试试这 4 款免费开源平替!
surfirst
LLM人工智能开源DeepResearch
引言随着AI研究代理(AIresearchagents)的兴起,越来越多的工具能够帮助用户快速获取信息、整理研究报告。OpenAI最近推出的DeepResearch便是一个典型代表,它能在几十分钟内完成原本需要人类数小时的多步骤研究任务。然而,DeepResearch并非唯一的选择,开源社区也提供了多个优秀的替代方案。如果你希望使用开源方案、获得更强的可定制性,或者避免依赖OpenAI,那么本文介
- DeepSeek API在AutoCAD中的创新应用与挑战
CodeJourney.
数据库算法人工智能
在数字化设计领域,随着人工智能技术的飞速发展,将AI能力融入传统设计软件成为提升设计效率和质量的重要趋势。AutoCAD作为广泛应用的计算机辅助设计软件,与DeepSeekAPI的结合展现出了巨大的潜力。这种融合不仅为设计工作带来了全新的思路和方法,还在多个方面对设计流程进行了优化和创新。一、DeepSeekAPI赋能AutoCAD的多元应用场景(一)智能设计辅助:让创意快速落地在传统设计过程中,
- 程序员学商务英语之Don‘t jinx it、l have a half mind to do sth、Don‘t change the subject、Quality over quantity..
李匠2024
英文
1463-Don'tjinxit.-别鸟鸦嘴A:Whatifitrainstheweekend?Youknow,theweather'sbeenchangeablethesedays!如果这个周末下雨怎么办?你知道,这些天的天气变化无常!B:Don'tiinxit.i'vespentalotoftimepreparingforthiscamping.lhopeitstaysfineforthewe
- AI 赋能应急管理:ChatGPT、DeepSeek、Grok 的应用探索
一ge科研小菜菜
人工智能人工智能
个人主页:一ge科研小菜鸡-CSDN博客期待您的关注1.引言随着人工智能(AI)技术的快速发展,大语言模型(LLM)在应急管理领域的应用逐步扩大。ChatGPT、DeepSeek、Grok等AI模型凭借强大的文本处理、数据分析和推理能力,可为灾害预警、应急响应、风险评估等提供高效支持。本文将对比三大AI模型在应急管理中的优势,并探讨其在未来智能化应急管理体系中的应用前景。2.应急管理中的核心挑战应
- DeepSeek的崛起:2025新春国产AI模型的全球影响力
耶耶Norsea
网络杂烩人工智能百度
摘要在2025年新春之际,国产AI模型DeepSeek以现象级的姿态迅速崛起,凭借免费、易用及高性能的特点,吸引了全球科技界的广泛关注。这款大型人工智能模型不仅展现了国产技术的实力,还为用户提供了高效便捷的使用体验,成为行业内的焦点。关键词DeepSeek崛起,2025新春,国产AI模型,免费易用,高性能特点一、国产AI的崭新篇章1.1DeepSeek的诞生背景在2025年新春之际,DeepSee
- 一文说清楚什么是预训练(Pre-Training)、微调(Fine-Tuning),零基础小白建议收藏!!
小城哇哇
人工智能语言模型AI大模型大模型微调预训练agiLLM
前言预训练和微调是现代AI模型的核心技术,通过两者的结合,机器能够在处理复杂任务时表现得更为高效和精准。预训练为模型提供了广泛的语言能力,而微调则确保了模型能够根据特定任务进行细化和优化。近年来,人工智能(AI)在各个领域的突破性进展,尤其是在自然语言处理(NLP)方面,引起了广泛关注。两项重要的技术方法——预训练和微调,成为了AI模型发展的基石。预训练通常是指在大规模数据集上进行模型训练,以帮助
- 每天分析一个开源项目:open_deep_research
申非zz
LLMgithub开源
每天分析一个开源项目:open_deep_research项目链接:langchain-ai/open_deep_research项目介绍项目功能:OpenDeepResearch是一个基于LangGraph的Web研究助手,旨在帮助用户快速生成特定主题的综合性报告。它模拟了OpenAI和Gemini的DeepResearch流程,但提供了更强的自定义能力,允许用户配置模型、Prompt、报告结构
- C/C++Win32编程基础详解视频下载
择善Zach
编程C++Win32
课题视频:C/C++Win32编程基础详解
视频知识:win32窗口的创建
windows事件机制
主讲:择善Uncle老师
学习交流群:386620625
验证码:625
--
- Guava Cache使用笔记
bylijinnan
javaguavacache
1.Guava Cache的get/getIfPresent方法当参数为null时会抛空指针异常
我刚开始使用时还以为Guava Cache跟HashMap一样,get(null)返回null。
实际上Guava整体设计思想就是拒绝null的,很多地方都会执行com.google.common.base.Preconditions.checkNotNull的检查。
2.Guava
- 解决ora-01652无法通过128(在temp表空间中)
0624chenhong
oracle
解决ora-01652无法通过128(在temp表空间中)扩展temp段的过程
一个sql语句后,大约花了10分钟,好不容易有一个结果,但是报了一个ora-01652错误,查阅了oracle的错误代码说明:意思是指temp表空间无法自动扩展temp段。这种问题一般有两种原因:一是临时表空间空间太小,二是不能自动扩展。
分析过程:
既然是temp表空间有问题,那当
- Struct在jsp标签
不懂事的小屁孩
struct
非UI标签介绍:
控制类标签:
1:程序流程控制标签 if elseif else
<s:if test="isUsed">
<span class="label label-success">True</span>
</
- 按对象属性排序
换个号韩国红果果
JavaScript对象排序
利用JavaScript进行对象排序,根据用户的年龄排序展示
<script>
var bob={
name;bob,
age:30
}
var peter={
name;peter,
age:30
}
var amy={
name;amy,
age:24
}
var mike={
name;mike,
age:29
}
var john={
- 大数据分析让个性化的客户体验不再遥远
蓝儿唯美
数据分析
顾客通过多种渠道制造大量数据,企业则热衷于利用这些信息来实现更为个性化的体验。
分析公司Gartner表示,高级分析会成为客户服务的关键,但是大数据分析的采用目前仅局限于不到一成的企业。 挑战在于企业还在努力适应结构化数据,疲于根据自身的客户关系管理(CRM)系统部署有效的分析框架,以及集成不同的内外部信息源。
然而,面对顾客通过数字技术参与而产生的快速变化的信息,企业需要及时作出反应。要想实
- java笔记4
a-john
java
操作符
1,使用java操作符
操作符接受一个或多个参数,并生成一个新值。参数的形式与普通的方法调用不用,但是效果是相同的。加号和一元的正号(+)、减号和一元的负号(-)、乘号(*)、除号(/)以及赋值号(=)的用法与其他编程语言类似。
操作符作用于操作数,生成一个新值。另外,有些操作符可能会改变操作数自身的
- 从裸机编程到嵌入式Linux编程思想的转变------分而治之:驱动和应用程序
aijuans
嵌入式学习
笔者学习嵌入式Linux也有一段时间了,很奇怪的是很多书讲驱动编程方面的知识,也有很多书将ARM9方面的知识,但是从以前51形式的(对寄存器直接操作,初始化芯片的功能模块)编程方法,和思维模式,变换为基于Linux操作系统编程,讲这个思想转变的书几乎没有,让初学者走了很多弯路,撞了很多难墙。
笔者因此写上自己的学习心得,希望能给和我一样转变
- 在springmvc中解决FastJson循环引用的问题
asialee
循环引用fastjson
我们先来看一个例子:
package com.elong.bms;
import java.io.OutputStream;
import java.util.HashMap;
import java.util.Map;
import co
- ArrayAdapter和SimpleAdapter技术总结
百合不是茶
androidSimpleAdapterArrayAdapter高级组件基础
ArrayAdapter比较简单,但它只能用于显示文字。而SimpleAdapter则有很强的扩展性,可以自定义出各种效果
ArrayAdapter;的数据可以是数组或者是队列
// 获得下拉框对象
AutoCompleteTextView textview = (AutoCompleteTextView) this
- 九封信
bijian1013
人生励志
有时候,莫名的心情不好,不想和任何人说话,只想一个人静静的发呆。有时候,想一个人躲起来脆弱,不愿别人看到自己的伤口。有时候,走过熟悉的街角,看到熟悉的背影,突然想起一个人的脸。有时候,发现自己一夜之间就长大了。 2014,写给人
- Linux下安装MySQL Web 管理工具phpMyAdmin
sunjing
PHPInstallphpMyAdmin
PHP http://php.net/
phpMyAdmin http://www.phpmyadmin.net
Error compiling PHP on CentOS x64
一、安装Apache
请参阅http://billben.iteye.com/admin/blogs/1985244
二、安装依赖包
sudo yum install gd
- 分布式系统理论
bit1129
分布式
FLP
One famous theory in distributed computing, known as FLP after the authors Fischer, Lynch, and Patterson, proved that in a distributed system with asynchronous communication and process crashes,
- ssh2整合(spring+struts2+hibernate)-附源码
白糖_
eclipsespringHibernatemysql项目管理
最近抽空又整理了一套ssh2框架,主要使用的技术如下:
spring做容器,管理了三层(dao,service,actioin)的对象
struts2实现与页面交互(MVC),自己做了一个异常拦截器,能拦截Action层抛出的异常
hibernate与数据库交互
BoneCp数据库连接池,据说比其它数据库连接池快20倍,仅仅是据说
MySql数据库
项目用eclipse
- treetable bug记录
braveCS
table
// 插入子节点删除再插入时不能正常显示。修改:
//不知改后有没有错,先做个备忘
Tree.prototype.removeNode = function(node) {
// Recursively remove all descendants of +node+
this.unloadBranch(node);
// Remove
- 编程之美-电话号码对应英语单词
bylijinnan
java算法编程之美
import java.util.Arrays;
public class NumberToWord {
/**
* 编程之美 电话号码对应英语单词
* 题目:
* 手机上的拨号盘,每个数字都对应一些字母,比如2对应ABC,3对应DEF.........,8对应TUV,9对应WXYZ,
* 要求对一段数字,输出其代表的所有可能的字母组合
- jquery ajax读书笔记
chengxuyuancsdn
jQuery ajax
1、jsp页面
<%@ page language="java" import="java.util.*" pageEncoding="GBK"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme()
- JWFD工作流拓扑结构解析伪码描述算法
comsci
数据结构算法工作活动J#
对工作流拓扑结构解析感兴趣的朋友可以下载附件,或者下载JWFD的全部代码进行分析
/* 流程图拓扑结构解析伪码描述算法
public java.util.ArrayList DFS(String graphid, String stepid, int j)
- oracle I/O 从属进程
daizj
oracle
I/O 从属进程
I/O从属进程用于为不支持异步I/O的系统或设备模拟异步I/O.例如,磁带设备(相当慢)就不支持异步I/O.通过使用I/O 从属进程,可以让磁带机模仿通常只为磁盘驱动器提供的功能。就好像支持真正的异步I/O 一样,写设备的进程(调用者)会收集大量数据,并交由写入器写出。数据成功地写出时,写入器(此时写入器是I/O 从属进程,而不是操作系统)会通知原来的调用者,调用者则会
- 高级排序:希尔排序
dieslrae
希尔排序
public void shellSort(int[] array){
int limit = 1;
int temp;
int index;
while(limit <= array.length/3){
limit = limit * 3 + 1;
- 初二下学期难记忆单词
dcj3sjt126com
englishword
kitchen 厨房
cupboard 厨柜
salt 盐
sugar 糖
oil 油
fork 叉;餐叉
spoon 匙;调羹
chopsticks 筷子
cabbage 卷心菜;洋白菜
soup 汤
Italian 意大利的
Indian 印度的
workplace 工作场所
even 甚至;更
Italy 意大利
laugh 笑
m
- Go语言使用MySQL数据库进行增删改查
dcj3sjt126com
mysql
目前Internet上流行的网站构架方式是LAMP,其中的M即MySQL, 作为数据库,MySQL以免费、开源、使用方便为优势成为了很多Web开发的后端数据库存储引擎。MySQL驱动Go中支持MySQL的驱动目前比较多,有如下几种,有些是支持database/sql标准,而有些是采用了自己的实现接口,常用的有如下几种:
http://code.google.c...o-mysql-dri
- git命令
shuizhaosi888
git
---------------设置全局用户名:
git config --global user.name "HanShuliang" //设置用户名
git config --global user.email "
[email protected]" //设置邮箱
---------------查看环境配置
git config --li
- qemu-kvm 网络 nat模式 (四)
haoningabc
kvmqemu
qemu-ifup-NAT
#!/bin/bash
BRIDGE=virbr0
NETWORK=192.168.122.0
GATEWAY=192.168.122.1
NETMASK=255.255.255.0
DHCPRANGE=192.168.122.2,192.168.122.254
TFTPROOT=
BOOTP=
function check_bridge()
- 不要让未来的你,讨厌现在的自己
jingjing0907
生活 奋斗 工作 梦想
故事one
23岁,他大学毕业,放弃了父母安排的稳定工作,独闯京城,在家小公司混个小职位,工作还算顺手,月薪三千,混了混,混走了一年的光阴。 24岁,有了女朋友,从二环12人的集体宿舍搬到香山民居,一间平房,二人世界,爱爱爱。偶然约三朋四友,打扑克搓麻将,日子快乐似神仙; 25岁,出了几次差,调了两次岗,薪水涨了不过百,生猛狂飙的物价让现实血淋淋,无力为心爱银儿购件大牌
- 枚举类型详解
一路欢笑一路走
enum枚举详解enumsetenumMap
枚举类型详解
一.Enum详解
1.1枚举类型的介绍
JDK1.5加入了一个全新的类型的”类”—枚举类型,为此JDK1.5引入了一个新的关键字enum,我们可以这样定义一个枚举类型。
Demo:一个最简单的枚举类
public enum ColorType {
RED
- 第11章 动画效果(上)
onestopweb
动画
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Eclipse中jsp、js文件编辑时,卡死现象解决汇总
ljf_home
eclipsejsp卡死js卡死
使用Eclipse编辑jsp、js文件时,经常出现卡死现象,在网上百度了N次,经过N次优化调整后,卡死现象逐步好转,具体那个方法起到作用,不太好讲。将所有用过的方法罗列如下:
1、取消验证
windows–>perferences–>validation
把 除了manual 下面的全部点掉,build下只留 classpath dependency Valida
- MySQL编程中的6个重要的实用技巧
tomcat_oracle
mysql
每一行命令都是用分号(;)作为结束
对于MySQL,第一件你必须牢记的是它的每一行命令都是用分号(;)作为结束的,但当一行MySQL被插入在PHP代码中时,最好把后面的分号省略掉,例如:
mysql_query("INSERT INTO tablename(first_name,last_name)VALUES('$first_name',$last_name')");
- zoj 3820 Building Fire Stations(二分+bfs)
阿尔萨斯
Build
题目链接:zoj 3820 Building Fire Stations
题目大意:给定一棵树,选取两个建立加油站,问说所有点距离加油站距离的最大值的最小值是多少,并且任意输出一种建立加油站的方式。
解题思路:二分距离判断,判断函数的复杂度是o(n),这样的复杂度应该是o(nlogn),即使常数系数偏大,但是居然跑了4.5s,也是醉了。 判断函数里面做了3次bfs,但是每次bfs节点最多