yolov5超参数解释(hyp.scratch-low.yaml)
文章目录
- 前言
- 总览一下,接下来开始逐个分析
-
- lr0
- lrf
- momentum
- weight_decay
- warmup_epochs
- warmup_momentum
- warmup_bias_lr
- box(目标框损失权重)
- cls(分类损失权重)
- cls_pw(分类损失的二元交叉熵损失中正样本的权重)
- obj(置信度损失权重)
- obj_pw(置信度损失的二元交叉熵损失中正样本的权重)
- iou_t
- anchor_t
- fl_gamma
- hsv_h、hsv_s、hsv_v
- degrees、translate、scale、shear
- perspective
- flipud、fliplr
- mosaic、mixup、copy_paste
- 总结
前言
在模型训练中,超参数的调整是必不可少的。有时候看到结果,分析之后发现是过拟合,这时候就需要对自己的模型超参数进行调整,以达到最优效果等等。这里对yolov5中的文件 hyp.scrtch-low.yaml超参数进行调整。
总览一下,接下来开始逐个分析
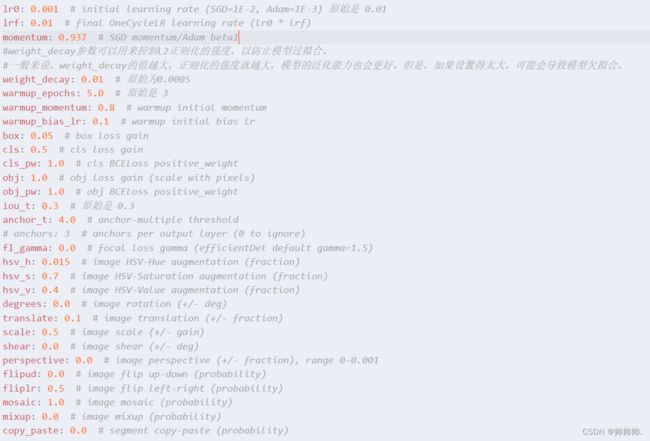
lr0
学习率的初始值,通常使用SGD时为0.01,使用Adam时为0.001
lrf
OneCycleLR 学习率调度器中的最终学习率(lr0 * lrf)
momentum
概念:
动量可以理解为参数更新的惯性,类似于小球滚动的惯性。它通过维护一个动量向量,记录之前梯度方向的加权平均值,并将其用于参数更新,可以加快训练速度,提高模型稳定性。
- 较小的动量可以使更新方向更加平稳
- 较大的动量可以加速参数更新。
weight_decay
概念:
权重衰减(weight decay)是一种常见的正则化技术,旨在减少模型的复杂性,防止过拟合。
- weight decay值越大,正则化强度越大,模型泛化能力会更好。但是太大会导致模型欠拟合。
warmup_epochs
- 在训练深度学习模型时,有时候需要先使用一个较小的学习率来进行预热,以避免在初始阶段出现不稳定的梯度或损失的情况。
- warmup_epochs就是控制预热的epoch数,也就是在训练的前几个epoch使用较小的学习率,使得模型能够更快地收敛到稳定的状态。
- 在预热阶段结束后,学习率会逐渐增加到初始设定的学习率,然后继续按照设定的学习率进行训练。
warmup_momentum
简单来说,就是热身训练那几个epochs的动量设置
warmup_bias_lr
概念:
指在学习率warm-up期间,偏置(bias)的学习率所使用的初始学习率。
- 在训练深度神经网络时,通常采用较小的学习率进行初始化,以便网络能够逐渐适应数据集的特征。
- 当学习率较小时,偏置的学习率通常要比权重的学习率更高,以保证网络在早期学习阶段能够更快地适应数据集的偏置。
box(目标框损失权重)
概念:
box通常指的是bounding box,即目标的边框。在yolov5中,是一个超参数,控制bounding box loss的权重。
- 它影响了网络如何调整检测边界框的位置和大小,以更好地匹配目标。
- 较大的box值将使网络更注重优化边界框。
- 较小的值将使其更加注重类别分类。
cls(分类损失权重)
概念:
在目标检测中,cls 通常表示分类损失。YoloV5中使用的是交叉熵损失,它度量的是目标属于每个类别的概率分布与实际分布之间的差异。
- 这个损失用于调整网络的权重,使网络能够更准确地预测目标的类别。
- cls值越大,表示越注重分类损失的影响。
cls_pw(分类损失的二元交叉熵损失中正样本的权重)
概念:
cls_pw就是用于控制分类损失函数中正样本权重的参数。
- 在某些情况下,数据集中的正负样本不平衡,导致分类损失函数中的负样本权重占比较大,这可能会导致模型对正样本的预测能力下降。
- 可以通过增加正样本的权重来平衡分类损失函数,从而提高模型对正样本的预测能力。
- 默认为1.0,表示正样本权重和负样本权重相等。
- 值设置的越大,则正样本权重越大。
obj(置信度损失权重)
概念:
YOLOv5 模型的 obj 指代对象的存在损失权重,用于指定正负样本的权重。
- 这个权重被用来平衡正负样本对于训练的贡献,避免模型偏向于训练样本数较多的类别,从而提高模型的性能。
- 当该参数值较大时,模型对对象的存在的关注程度就会更高。
obj_pw(置信度损失的二元交叉熵损失中正样本的权重)
指正样本权重
- 如果正样本数量较少,YOLOv5 会增加正样本的权重,以便更多地关注正样本,提高检测准确率。
- 如果正样本数量较多,YOLOv5 会减小正样本的权重,以便更多地关注负样本,减少误检率。
iou_t
Iou阈值,用于预测框和真实框之间的匹配。
- IoU 是指检测框(预测框)和真实框之间的交并比。当预测框和真实框之间的 IoU 大于 iou_t 时,视为检测正确,否则视为检测错误。
- 比如,iuo_t设置为0.5,只有预测框和真实框之间的Iou大于0.5才会视为正确检测。
anchor_t
anchor的阈值,用于筛选anchor。跟iou_t道理一样
- 这个参数就是控制哪些anchor boxes会被用来匹配目标。anchor_t越小,则越容易匹配更小的目标,anchor_t越大,则越容易匹配更大的目标
- 对于一些小的目标,因为它们的大小与anchor的大小差别较大,需要使用比较小的anchor box进行匹配,此时设置一个小的anchor_t可以让这些小目标更容易被匹配上。
- 而对于一些大目标,它们的大小与anchor大小的差别较小,可以使用相对较大的anchor进行匹配,此时设置一个大的anchor_t可以使得大目标更容易被匹配。
fl_gamma
fl_gamma 是 Focal Loss 中的一个参数,用于调整损失函数的加权。
- fl_gamma 就是控制难以分类样本权重的参数,其值越大,模型对难以分类样本的关注程度越高,对易于分类的样本关注程度越低。
hsv_h、hsv_s、hsv_v
表示图像HSV颜色空间的色调、饱和度、明度的增强参数。
- hsv_h、hsv_s、hsv_v的取值范围都是[0, 1],可以尝试不同的取值来进行比较。
- 值越大,强度越大
degrees、translate、scale、shear
表示图像旋转、平移、缩放、扭曲的增强参数
- 数据增强的程度越大,可以提高模型的泛化能力,但也会增加训练时间和计算资源的消耗。
perspective
是数据增强中的一种,它会对图像进行透视变换,使得图像看起来像是从不同的角度拍摄的。
- 透视变换可以改变图像中物体的形状和位置,因此能够增加模型的鲁棒性和泛化能力。
- 参数的值表示透视变换的程度,取值范围是0到0.001。
- 当值为0时,表示不进行透视变换。当值为0.001时,表示进行最大程度的透视变换。
- 通常情况下,可以将其设置为一个比较小的值,例如0.0005,以增加模型的泛化能力,同时不会对图像造成过大的扭曲。
flipud、fliplr
表示图像上下翻转、左右翻转的增强概率。
- 它们的取值范围是从 0 到 1,表示翻转的概率
- 比如,flipud 设置为 0.5 表示有 50% 的概率对图像进行上下翻转,设置为 0 表示不进行翻转,设置为 1 表示始终进行上下翻转,fliplr同理。
mosaic、mixup、copy_paste
数据增强的方式,可以用来增强训练集的多样性,从而提高模型的泛化性能。
- mosaic: 以一定的概率将四张图片拼接成一张,增强了模型对多物体的感知能力和位置估计能力。
取值一般在0.1~1.0之间 - mixup: 以一定的概率对两张图片进行线性混合,增强了模型对物体形状和纹理的学习能力
取值一般在0.0~0.5之间 - copy_paste: 以一定的概率将一张图片的一部分复制到另一张图片上,增强了模型对物体的位置和尺度变化的鲁棒性。取值一般在0.0~0.5之间
- 这些取值表示概率,比如mosaic参数值为1,表示使用mosaic数据增强概率为100%,值为0.5则表示概率为50%。
总结
关于hyp.scrtch-low.yaml的超参数写完了,我觉得在模型训练中,适当的调整这些超参数还是很有用的。