实验一:词法分析程序的设计
文章目录
- 一、实验目的
- 二、实验原理与要求
-
- 1、原理
- 2、要求
- 三、实验设备
- 四、实验内容
-
- 1. 定义语言子集并编码,要求有保留字、标识符、常数、运算符、界符。
- 2. 画出状态转换图。
- 3. 编写代码,实现分析。
- 五、实验步骤
-
- 1. 定义语言子集的单词符号的种别编码及内码值
- 2. 构造状态转换图(自动机)
- 3. 状态转换图的实现(编码)
- 4. 测试
- 六、配套资源
一、实验目的
理解词法分析的功能,熟悉词法分析程序的构造。
二、实验原理与要求
1、原理
利用状态转换图来确定程序的流程。
2、要求
定义一个单词集,能用状态转换图描述。测试应满足分支覆盖。
三、实验设备
配置有C/C++开发环境的计算机设备。
四、实验内容
1. 定义语言子集并编码,要求有保留字、标识符、常数、运算符、界符。
2. 画出状态转换图。
3. 编写代码,实现分析。
五、实验步骤
1. 定义语言子集的单词符号的种别编码及内码值
如果一个种别只含有一个单词符号,则内码值为-1;如果一个种别含有多个单词符号(如:标识符、常数),用它自身的值作为内码值。
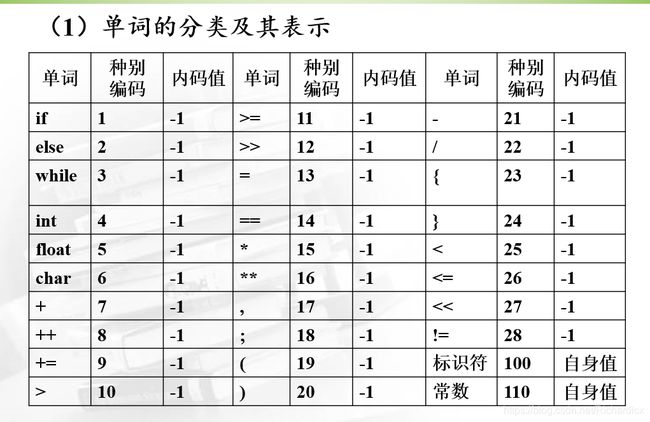
定义一个结构体数组Result,用它存放识别出的单词符号的种别编码及内码值。如:输入k=99; 则输出为:(100, k), (13, -1), (110, 99), (18, -1), (0,)

2. 构造状态转换图(自动机)


说明:状态96~100表示输入非法字符。
3. 状态转换图的实现(编码)
// -*- coding: utf-8 -*-
// @ Date : 2020/5/20 13:14
// @ Author : RichardLau_Cx
// @ file : Richard.cpp
// @ IDE : Dex-C++
// @ Source : 编译原理实验
/**
* 1. 以学习他人的经验为主,带入自己的想法为辅
* 2. 频繁debug各函数实现,是一种变相的效率提升
* 3. 由于很多变量都是公共变量,所以函数调用时则不必传值
*/
#include 4. 测试
- 如:输入520.13E+14*9+99,则输出为:(110, 520.13E+14),(15, -1),(110, 9),(7, -1),(110, 99),(0, )

- 如:输入if(k <= 45) sum += 2;,则输出为:(1, -1),(19, -1),(100, k),(26, -1),(110, 45),(20, -1),(100, sum),(9, -1),(110, 2),(18, -1),(0, )

- 测试常数:k=36; 或者 15.67 或者 13e-14



- 测试含有非法字符的:char string11?? > !min;,则输出为:(6, -1),(100, string11),(0, Input Error!),(0, Input Error!),(10, -1),(0, Input Error!),(100, min),(18, -1),(0, )
Note:简单起见,除标识符、常数外,其余单词均为一个单词一类(如一个保留字一类,一个运算符一类),则标识符、常数的内码值为自身的值,其余单词的种别编码代表了它自身的值,故内码值用 -1表示。
六、配套资源
- 实验指导书