MySQL----内置函数
MySQL---->内置函数
函数:将经常使用的代码封装起来,需要的时候直接调用就可以
从函数定义角度,函数可分为:
- 内置函数:系统内置的通用函数
- 自定义函数:需要根据需求编写的函数
MySQL提供的内置函数从实现的功能角度可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、加密与解密函数、获取MySQL信息函数、聚合函数。将其汇总可以分为两大类单行函数、聚合函数(分组函数)
单行函数
- 操作数据对象
- 接受参数返回一个结果
- 只对一行进行变换
- 每行返回一个结果
- 可以嵌套
- 参数可以是一列或一个值
数值函数
1) 基本函数
| 函数 | 用法 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SIGN(X) | 返回X的符号。正数返回1,负数返回-1,0返回0 |
| PI() | 返回圆周率的值 |
| CEIL(x),CEILING(x) | 返回大于或等于某个值的最小整数 |
| FLOOR(x) | 返回小于或等于某个值的最大整数 |
| LEAST(e1,e2,e3…) | 返回列表中的最小值 |
| GREATEST(e1,e2,e3…) | 返回列表中的最大值 |
| MOD(x,y) | 返回X除以Y后的余数 |
| RAND() | 返回0~1的随机值 |
| RAND(x) | 返回0~1的随机值,其中x的值用作种子值,相同的X值会产生相同的随机 数 |
| ROUND(x) | 返回一个对x的值进行四舍五入后,最接近于X的整数 |
| ROUND(x,y) | 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| SQRT(x) | 返回x的平方根。当X的值为负数时,返回NULL |
2) 角度与弧度互换函数
| 函数 | 用法 |
|---|---|
| RADIANS(x) | 将角度转化为弧度,其中,参数x为角度值 |
| DEGREES(x) | 将弧度转化为角度,其中,参数x为弧度值 |
3) 三角函数
| 函数 | 用法 |
|---|---|
| SIN(x) | 将角度转化为弧度,其中,参数x为角度值 |
| ASIN(x) | 将弧度转化为角度,其中,参数x为弧度值 |
| COS(x) | 返回x的余弦值,其中,参数x为弧度值 |
| ACOS(x) | 返回x的反余弦值,即获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) | 返回x的正切值,其中,参数x为弧度值 |
| ATAN(x) | 返回x的反正切值,即返回正切值为x的值 |
| ATAN2(m,n) | 返回两个参数的反正切值 |
| COT(x) | 返回x的余切值,其中,X为弧度值 |
4) 指数与对数函数
| 函数 | 用法 |
|---|---|
| POW(x,y),POWER(X,Y) | 返回x的y次方 |
| EXP(X) | 返回e的X次方,其中e是一个常数,2.718281828459045 |
| LN(X),LOG(X) | 返回以e为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG10(X) | 返回以10为底的X的对数,当X <= 0 时,返回的结果为NULL |
| LOG2(X) | 返回以2为底的X的对数,当X <= 0 时,返回NULL |
5) 进制间的转换
| 函数 | 用法 |
|---|---|
| BIN(x) | 返回x的二进制编码 |
| HEX(x) | 返回x的十六进制编码 |
| OCT(x) | 返回x的八进制编码 |
| CONV(x,f1,f2) | 返回f1进制数变成f2进制数 |
字符串函数
字符串的索引是从1开始的
| 函数 | 用法 |
|---|---|
| ASCII(S) | 返回字符串S中的第一个字符的ASCII码值 |
| CHAR_LENGTH(s) | 返回字符串s的字符数。作用与CHARACTER_LENGTH(s)相同 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| CONCAT(s1,s2,…,sn) | 连接s1,s2,…,sn为一个字符串 |
| CONCAT_WS(x, s1,s2,…,sn) | 同CONCAT(s1,s2,…)函数,但是每个字符串之间要加上x,x相当于连接符 |
| INSERT(str, idx, len, replacestr) | 将字符串str从第idx位置开始,len个字符长的子串替换为字符串replacestr |
| REPLACE(str, a, b) | 用字符串b替换字符串str中所有出现的字符串a |
| UPPER(s) 或 UCASE(s) | 将字符串s的所有字母转成大写字母 |
| LOWER(s) 或LCASE(s) | 将字符串s的所有字母转成小写字母 |
| LEFT(str,n) | 返回字符串str最左边的n个字符 |
| RIGHT(str,n) | 返回字符串str最右边的n个字符 |
| LPAD(str, len, pad) | 用字符串pad对str最左边进行填充,直到str的长度为len个字符,实现右对齐效果 |
| RPAD(str ,len, pad) | 用字符串pad对str最右边进行填充,直到str的长度为len个字符,实现左对齐效果 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始与结尾的空格(首位) |
| TRIM(s1 FROM s) | 去掉字符串s开始与结尾的s1 |
| TRIM(LEADING s1 FROM s) | 去掉字符串s开始处的s1 |
| TRIM(TRAILING s1 FROM s) | 去掉字符串s结尾处的s1 |
| REPEAT(str, n) | 返回str重复n次的结果 |
| SPACE(n) | 返回n个空格 |
| STRCMP(s1,s2) | 比较字符串s1,s2的ASCII码值的大小 |
| SUBSTR(s,index,len) | 返回从字符串s的index位置其len个字符,作用与SUBSTRING(s,n,len)、 MID(s,n,len)相同 |
| LOCATE(substr,str) | 返回字符串substr在字符串str中首次出现的位置,作用于POSITION(substr IN str)、INSTR(str,substr)相同。未找到,返回0 |
| ELT(m,s1,s2,…,sn) | 返回指定位置的字符串,如果m=1,则返回s1,如果m=2,则返回s2,如果m=n,则返回sn |
| FIELD(s,s1,s2,…,sn) | 返回字符串s在字符串列表中第一次出现的位置 |
| FIND_IN_SET(s1,s2) | 返回字符串s1在字符串s2中出现的位置。其中,字符串s2是一个以逗号分隔的字符串 |
| REVERSE(s) | 返回s反转后的字符串 |
| NULLIF(value1,value2) | 比较两个字符串,如果value1与value2相等,则返回NULL,否则返回 value1 |
注意:MySQL中,字符串的位置是从1开始的。
日期和时间函数
1) 获取日期、时间
| 函数 | 用法 |
|---|---|
| CURDATE() ,CURRENT_DATE() | 返回当前日期,只包含年、 月、日 |
| CURTIME() , CURRENT_TIME() | 返回当前时间,只包含时、 分、秒 |
| NOW() / SYSDATE() / CURRENT_TIMESTAMP() / LOCALTIME() / LOCALTIMESTAMP() | 返回当前系统日期和时间 |
| UTC_DATE() | 返回UTC(世界标准时间) 日期 |
| UTC_TIME() | 返回UTC(世界标准时间) 时间 |
2) 日期与时间戳的转换
| 函数 | 用法 |
|---|---|
| UNIX_TIMESTAMP() | 以UNIX时间戳的形式返回当前时间。SELECT UNIX_TIMESTAMP() - >1634348884 |
| UNIX_TIMESTAMP(date) | 将时间date以UNIX时间戳的形式返回。 |
| FROM_UNIXTIME(timestamp) | 将UNIX时间戳的时间转换为普通格式的时间 |
3) 获取月份、星期、星期数、天数等函数
| 函数 | 用法 |
|---|---|
| YEAR(date) / MONTH(date) / DAY(date) | 返回具体的日期值 |
| HOUR(time) / MINUTE(time) / SECOND(time) | 返回具体的时间值 |
| FROM_UNIXTIME(timestamp) | 将UNIX时间戳的时间转换为普通格式的时间 |
| MONTHNAME(date) | 返回月份:January,… |
| DAYNAME(date) | 返回星期几:MONDAY,TUESDAY…SUNDAY |
| WEEKDAY(date) | 返回周几,注意,周1是0,周2是1,。。。周日是6 |
| QUARTER(date) | 返回日期对应的季度,范围为1~4 |
| WEEK(date) , WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFYEAR(date) | 返回日期是一年中的第几天 |
| DAYOFMONTH(date) | 返回日期位于所在月份的第几天 |
| DAYOFWEEK(date) | 返回周几,注意:周日是1,周一是2,。。。周六是 7 |
4) 日期的操作函数
| 函数 | 用法 |
|---|---|
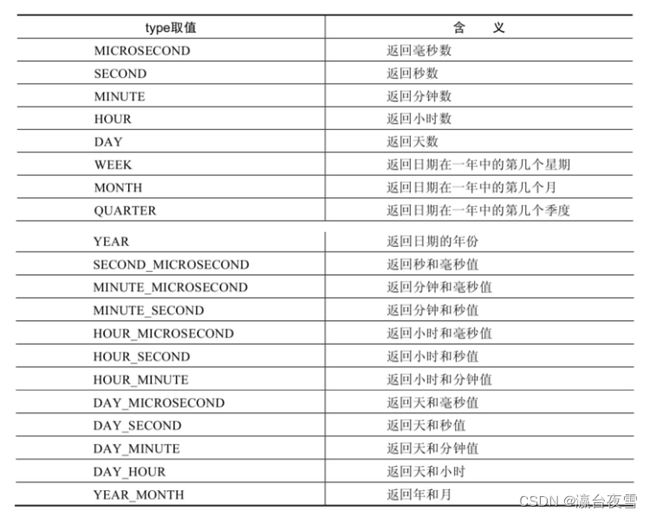
| EXTRACT(type FROM date) | 返回指定日期中特定的部分,type指定返回的值 |
EXTRACT(type FROM date)函数中type的取值与含义:
5) 时间和秒钟转换的函数
| 函数 | 用法 |
|---|---|
| TIME_TO_SEC(time) | 将 time 转化为秒并返回结果值。转化的公式为: 小时*3600+分钟 *60+秒 |
| SEC_TO_TIME(seconds) | 将 seconds 描述转化为包含小时、分钟和秒的时间 |
6) 计算日期和时间的函数
| 函数 | 用法 |
|---|---|
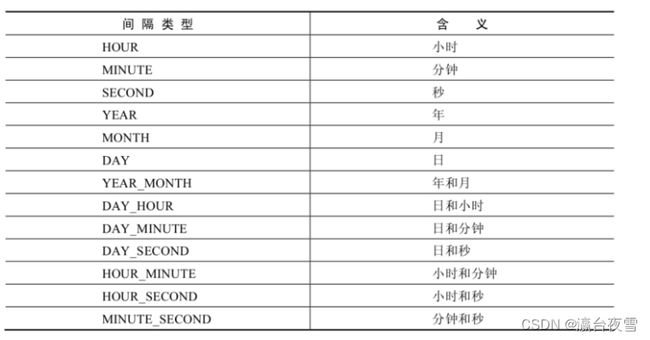
| DATE_ADD(datetime, INTERVAL expr type), ADDDATE(date,INTERVAL expr type) | 返回与给定日期时间相差INTERVAL时间段的日期时间 |
| DATE_SUB(date,INTERVAL expr type), SUBDATE(date,INTERVAL expr type) | 返回与date相差INTERVAL时间间隔的日期 |
上述函数中type的取值:
| 函数 | 用法 |
|---|---|
| ADDTIME(time1,time2) | 返回time1加上time2的时间。当time2为一个数字时,代表的是 秒 ,可以为负数 |
| SUBTIME(time1,time2) | 返回time1减去time2后的时间。当time2为一个数字时,代表的 是 秒 ,可以为负数 |
| DATEDIFF(date1,date2) | 返回date1 - date2的日期间隔天数 |
| TIMEDIFF(time1, time2) | 返回time1 - time2的时间间隔 |
| FROM_DAYS(N) | 返回从0000年1月1日起,N天以后的日期 |
| TO_DAYS(date) | 返回日期date距离0000年1月1日的天数 |
| LAST_DAY(date) | 返回date所在月份的最后一天的日期 |
| MAKEDATE(year,n) | 针对给定年份与所在年份中的天数返回一个日期 |
| MAKETIME(hour,minute,second) | 将给定的小时、分钟和秒组合成时间并返回 |
| PERIOD_ADD(time,n) | 返回time加上n后的时间 |
7) 日期的格式化与解析
| 函数 | 用法 |
|---|---|
| DATE_FORMAT(date,fmt) | 按照字符串fmt格式化日期date值 |
| TIME_FORMAT(time,fmt) | 按照字符串fmt格式化时间time值 |
| GET_FORMAT(date_type,format_type) | 返回日期字符串的显示格式 |
| STR_TO_DATE(str, fmt) | 按照字符串fmt对str进行解析,解析为一个日期 |
上述 非GET_FORMAT 函数中fmt参数常用的格式符:
| 格式符 | 说明 | 格式符 | 说明 |
|---|---|---|---|
| %Y | 4位数字表示年份 | %y | 表示两位数字表示年份 |
| %M | 月名表示月份(January,…) | %m | 两位数字表示月份 (01,02,03。。。) |
| %b | 缩写的月名(Jan.,Feb.,…) | %c | 数字表示月份(1,2,3,…) |
| %D | 英文后缀表示月中的天数 (1st,2nd,3rd,…) | %d | 两位数字表示月中的天数(01,02…) |
| %e | 数字形式表示月中的天数 (1,2,3,4,5…) | ||
| %H | 两位数字表示小数,24小时制 (01,02…) | %h 和%I | 两位数字表示小时,12小时制 (01,02…) |
| %k | 数字形式的小时,24小时制(1,2,3) | %l | 数字形式表示小时,12小时制 (1,2,3,4…) |
| %i | 两位数字表示分钟(00,01,02) | %S 和%s | 两位数字表示秒(00,01,02…) |
| %W | 一周中的星期名称(Sunday…) | %a | 一周中的星期缩写(Sun., Mon.,Tues.,…) |
| %w | 以数字表示周中的天数 (0=Sunday,1=Monday…) | ||
| %j | 以3位数字表示年中的天数(001,002…) | %U | 以数字表示年中的第几周, (1,2,3。。)其中Sunday为周中第一 天 |
| %u | 以数字表示年中的第几周, (1,2,3。。)其中Monday为周中第一 天 | ||
| %T | 24小时制 | %r | 12小时制 |
| %p | AM或PM | %% | 表示% |
流程控制函数
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。 MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数。
| 函数 | 用法 |
|---|---|
| IF(value,value1,value2) | 如果value的值为TRUE,返回value1, 否则返回value2 |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 … [ELSE resultn] END | 相当于Java的if…else if…else… |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量值1 THEN 值1 … [ELSE 值n] END | 相当于Java的switch…case… |
SELECT first_name,last_name,IF(salary>6000,'高工资','低工资') '工资等级'
FROM atguigudb.employees;
SELECT first_name,last_name,IFNULL(commission_pct,0) "details"
FROM atguigudb.employees
LIMIT 0,20;
SELECT first_name,last_name,CASE WHEN salary>=15000 THEN '大佬'
WHEN salary>=10000 THEN '小佬'
WHEN salary>=8000 THEN '奋斗逼'
ELSE '老鼠人' END "details"
FROM atguigudb.employees;
SELECT first_name,last_name,CASE WHEN salary>=15000 THEN '大佬'
WHEN salary>=10000 THEN '小佬'
WHEN salary>=8000 THEN '奋斗逼'
END "details"
FROM atguigudb.employees;
SELECT first_name,last_name,department_id,CASE department_id WHEN 10 THEN salary*1.1
WHEN 20 THEN salary*1.2
WHEN 30 THEN salary*1.3
ELSE salary*1.4 END "details"
FROM atguigudb.employees;
加密与解密函数
加密与解密函数主要用于对数据库中的数据进行加密和解密处理,以防止数据被他人窃取。这些函数在保证数据库安全时非常有用。
| 函数 | 用法 |
|---|---|
| PASSWORD(str) | 返回字符串str的加密版本,41位长的字符串。加密结果不可逆 ,常用于用户的密码加密,在mysql8.0不适用 |
| MD5(str) | 返回字符串str的md5加密后的值,也是一种加密方式。若参数为 NULL,则会返回NULL |
| SHA(str) | 从原明文密码str计算并返回加密后的密码字符串,当参数为 NULL时,返回NULL。 SHA加密算法比MD5更加安全 。 |
| ENCODE(value,password_seed) | 返回使用password_seed作为加密密码加密value |
| DECODE(value,password_seed) | 返回使用password_seed作为加密密码解密value |
MySQL信息函数
MySQL中内置了一些可以查询MySQL信息的函数,这些函数主要用于帮助数据库开发或运维人员更好地 对数据库进行维护工作。
| 函数 | 用法 |
|---|---|
| VERSION() | 返回当前MySQL的版本号 |
| CONNECTION_ID() | 返回当前MySQL服务器的连接数 |
| DATABASE(),SCHEMA() | 返回MySQL命令行当前所在的数据库 |
| USER(),CURRENT_USER()、SYSTEM_USER(), SESSION_USER() | 返回当前连接MySQL的用户名,返回结果格式为 “主机名@用户名” |
| CHARSET(value) | 返回字符串value自变量的字符集 |
| COLLATION(value) | 返回字符串value的比较规则 |
MySQL中有些函数无法对其进行具体的分类,但是这些函数在MySQL的开发和运维过程中也是不容忽视 的。
| 函数 | 用法 |
|---|---|
| FORMAT(value,n) | 返回对数字value进行格式化后的结果数据。n表示 四舍五入 后保留 到小数点后n位 |
| CONV(value,from,to) | 将value的值进行不同进制之间的转换 |
| INET_ATON(ipvalue) | 将以点分隔的IP地址转化为一个数字 |
| INET_NTOA(value) | 将数字形式的IP地址转化为以点分隔的IP地址 |
| BENCHMARK(n,expr) | 将表达式expr重复执行n次。用于测试MySQL处理expr表达式所耗费 的时间 |
| CONVERT(value USING char_code) | 将value所使用的字符编码修改为char_code |
聚合函数
聚合函数对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值
聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
常见的聚合函数
AVG/SUM
只适用于数值类型的字段(或变量)否则没有效果
SELECT AVG(salary),SUM(salary)
FROM employees;
SELECT AVG(salary),SUM(last_name)
FROM employees;
MAX/MIN
可以对字符串也可进行排序,使用与数值类型,字符串类型,日期时间类型的字段(或变量)
SELECT MAX(salary),MIN(salary)
FROM employees;
SELECT MAX(last_name),MIN(last_name)
FROM employees;
COUNT
计算指定字段在查询结果中出现的个数
注意:计算指定字段出现的个数时,是不计算空值的
SELECT COUNT(employee_id),COUNT(salary),COUNT(1),COUNT(*)
FROM employees;
SELECT AVG(salary),SUM(salary)/COUNT(salary),
AVG(commission_pct),SUM(commission_pct)/COUNT(commission_pct),
SUM(commission_pct)/107
FROM employees;
统计表中的记录数,可以使用COUNT(*),COUNT(1),COUNT(具体字段),哪一个效率最高?
如果使用MyISAM存储引擎,则三者效率相同,统计数据表的行数只需要O(1)的复杂度,这是因为每张MylSAM的数据表都有一个meta信息存储row_count的只,而一致性则由表级锁来保证
如果使用的是InnoDB存储引擎,则三者效率:count(*)=count(1)>count(字段)
GROUP BY使用
分组函数,可以使用GROUP BY子句将表中的数据分成若干组
结论:SELECT中出现的非组函数的字段必须声明在GROUP BY中。反之,GROUP BY中声明的字段可以不出现在SELECT中
GROUP 声明在FROM后面,WHERE后面,ORDER BY前面,LIMIT前面
MySQL中GROUP BY中使用WITH ROLLUP,会计算最后的平均值,但需注意与ORDER BY连用
SELECT department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id
ORDER BY department_id DESC;
SELECT job_id,department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY department_id,job_id
ORDER BY department_id DESC;
SELECT job_id,department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id,department_id
ORDER BY department_id DESC;
SELECT job_id,department_id,AVG(salary),SUM(salary)
FROM employees
GROUP BY job_id,department_id WITH ROLLUP;
HAVING 使用
用以实现数据过滤操作
-
如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则将报错
-
HAVING必须放在GROUP BY后面
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000;
- 开发中,使用HAVING的前提是SQL中使用GROUP BY
- WHERE和HAVING可以组合使用,组合使用,执行效率高
SELECT department_id,MAX(salary)
FROM employees
WHERE department_id IN (10,20,30,40)
GROUP BY department_id
HAVING MAX(salary)>10000;
SELECT department_id,MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 AND department_id IN (10,20,30,40);
- 当过滤条件中有聚合函数,则此过滤条件必须声明在HAVING中。当过滤条件中没有聚合函数时,则此过滤条件声明在WHERE中或HAVING中都可以。但是,建议声明在WHERE中
WHERE与HAVING对比
- HAVING使用范围更广。在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务
- 如果过滤条件中没有聚合函数:WHERE执行效率要高于HAVING.WHERE 是先筛选后连接,而 HAVING 是先连接 后筛选。
- WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组 统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发 挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很 大的差别。
SELECT 的执行过程
SELECT语句的完整结构
SQL92
SELECT ....,...,...,(存在聚合函数)
FROM ...,...,
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ... (ASC/DESC)
LIMIT ...,..
SQL99
SELECT ....,...,...,(存在聚合函数)
FROM ...(LEFT/RIGHT) JOIN...ON ...多表连接条件
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,...
HAVING 包含聚合函数的过滤条件
ORDER BY ... (ASC/DESC)
LIMIT ...,..
SQL语句的执行过程
先行再列最后展示
FROM -> ON->(LEFT/RIGHT JOIN)->WHERE -> GROUP BY -> SELECT 的字段 -> HAVING -> DISTINCT -> ORDER BY -> LIMIT
SELECT的别名可以在HAVING 中使用,但不能在WHERE中使用
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个 虚拟表 ,然后将这个虚拟表传入下一个步 骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。