pyspark入门--DataFrame基础
pyspark
是一个python操作spark的库, 可以方便我们进行spark数据处理

安装
pip install pysparkDataFrame(数据帧)
类似于表格
1-查看
项目结构
people.json
pyspark支持查看json文件
[{
"name": "Michael",
"age": 12
},
{
"name": "Andy",
"age": 13
},
{
"name": "Justin",
"age": 8
}] 1-show.py
from pyspark.sql import SparkSession
# 创建spark会话(连接)
spark = SparkSession.builder.appName('Basics').getOrCreate()
# 获取people.json里的数据
# option("multiline","true") 是为了能解析json数组
df = spark.read.option("multiline","true").json("people.json")
# 打印整个dataframe
df.show()
# 打印dataframe的每个字段(列)的类型
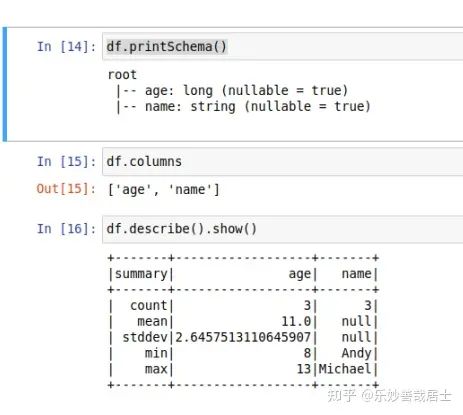
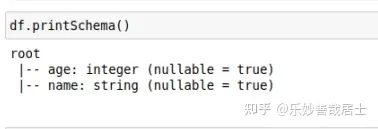
df.printSchema()
# 打印dataframe有哪些字段(列)
print(df.columns)
# 打印dataframe的详细信息
df.describe().show() 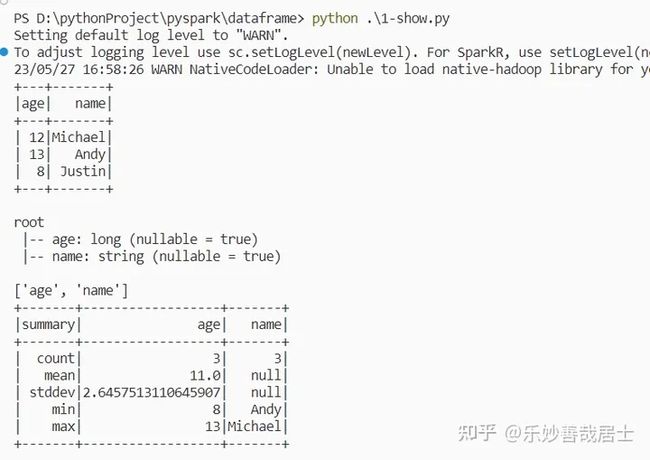

2-type/head/select/withColumn/withColumnRenamed/使用sql语句
from pyspark.sql import SparkSession
# 创建spark会话(连接)
spark = SparkSession.builder.appName('Basics').getOrCreate()
# 获取people.json里的数据
# option("multiline","true") 是为了能解析json数组
df = spark.read.option("multiline","true").json("people.json")
# 获取某列的类型(这个类型是pyspark自动推导的)
# df['xxx']表示取df的xxx列
print(type(df['age']))
# select,可以读取指定条件的数据
df.select('age').show()
## 读取多列
df.select('age','Name').show()
# 打印 头两个里,下标为0的
print(df.head(2)[0])
## row[0]可以取得row里的数据
print(df.head(2)[0][0])
# 添加一列,值为age*2
df.withColumn('newage',df['age']*2).show()
# 重命名某列
df.withColumnRenamed('age','new_age').show()
# 使用sql
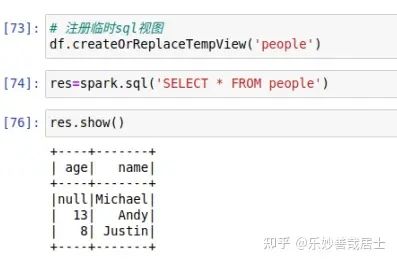
## 注册临时sql视图
df.createOrReplaceTempView('people')
## 使用sql语句
res = spark.sql('select * from people')
res.show()
age_eq_13 = spark.sql('select * from people where age = 13')
age_eq_13.show()



3-过滤器
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('ops').getOrCreate()
# header表示第一行是列名
df = spark.read.csv('train.csv',inferSchema=True,header=True)
df.printSchema()
df.show()
df.head(3)[0]
# 过滤器
df.filter('Sex == "male"').show()
# select 选择要显示的列
df.filter('Sex == "female"').select('Sex').show()
# select 选择要显示的列
df.filter('Sex == "female"').select(['Sex','Name']).show()
# 过滤器写法2
df.filter(df['Sex']=='male').select('Ticket').show()
# 过滤器 多条件
df.filter((df['Sex']=='male') & (df['Pclass']>1)).show()
# 过滤器 非 ~
df.filter(~(df['Pclass']>1)).show()
# collect -> list
res = df.filter(df['Pclass']==2).collect()
print(res)
row = res[0]
# 转为字典
print(row.asDict())
print(row.asDict()['Pclass']) 4-Groupby 分组
from pyspark.sql import SparkSession
from pyspark.sql.functions import countDistinct,avg,stddev
from pyspark.sql.functions import format_number
spark = SparkSession.builder.appName('aggs').getOrCreate()
df = spark.read.csv('EcommerceCustomers.csv',inferSchema=True,header=True)
df.show()
df.printSchema()
# 根据字段分组
df.groupBy('Avatar')
# 分组求平均
df.groupBy('Avatar').mean().show()
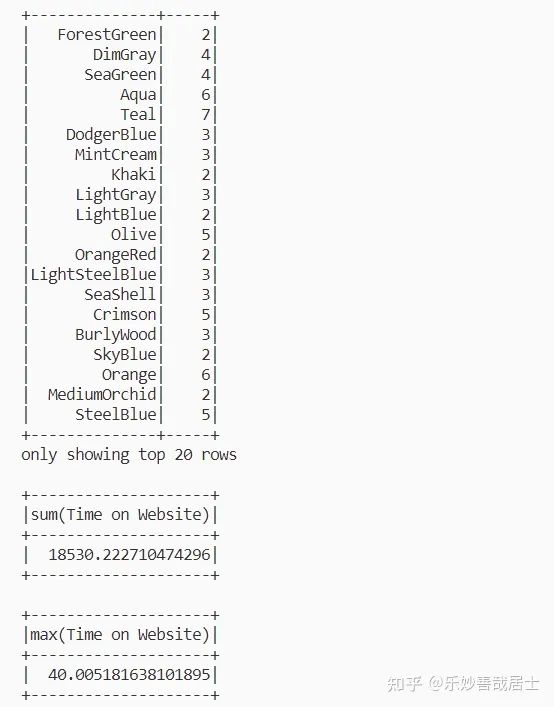
df.groupBy('Avatar').count().show()
# 聚合 求'Time on Website'列的值的sum
df.agg({'Time on Website':'sum'}).show()
df.agg({'Time on Website':'max'}).show()
group_data = df.groupBy('Avatar')
# 分组进行agg聚合(字典方式)操作
group_data.agg({'Time on Website':'max'}).show()
# 求数据总数(不含重复数据)
df.select(countDistinct('Time on Website')).show()
# alias 其别名
# avg 求平均
df.select(avg('Time on Website').alias('website')).show()
# stddev 标准差
df.select(stddev('Time on Website')).show()
web_std = df.select(stddev('Time on Website').alias('web'))
web_std.show()
# 保留2位
web_std.select(format_number('web',2).alias('web')).show()
df.show()
# 升序排列
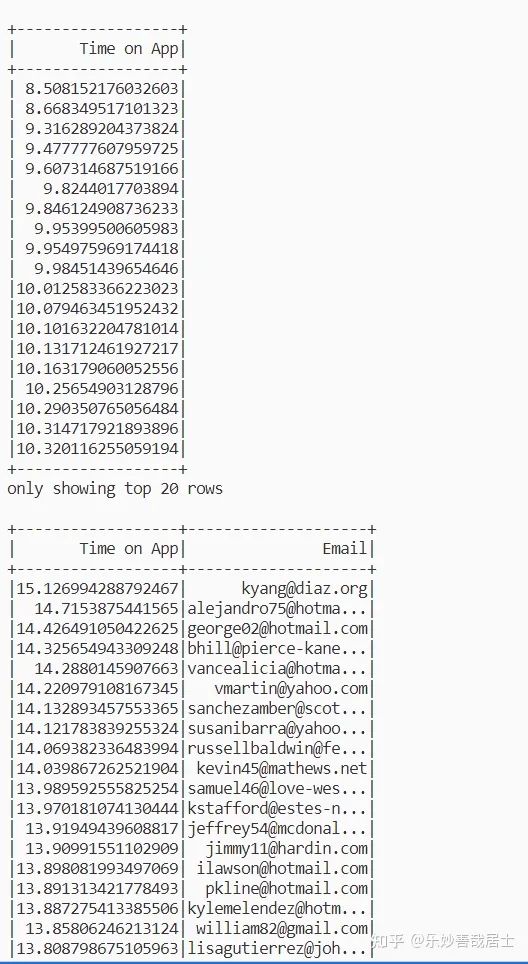
df.orderBy('Time on App').select('Time on App').show()
# 降序
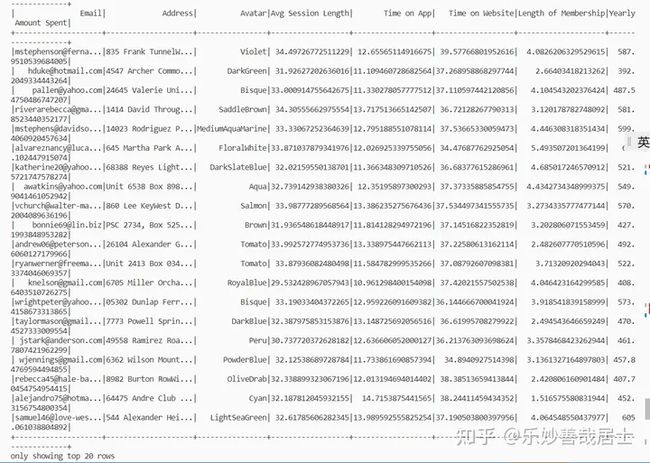
df.orderBy(df['Time on App'].desc()).select(['Time on App','Email']).show() 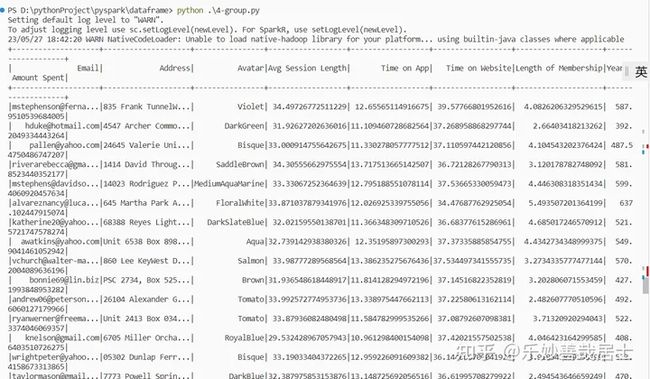



5-缺失值处理
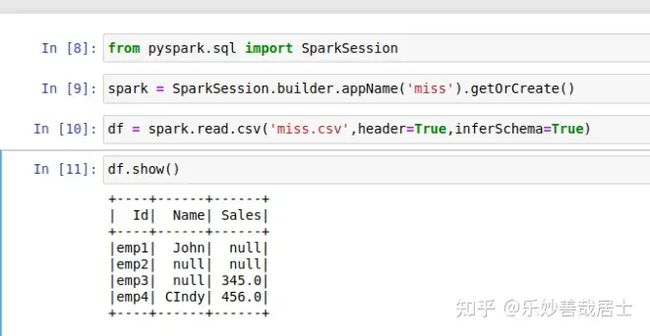
from pyspark.sql import SparkSession
from pyspark.sql.functions import mean
spark = SparkSession.builder.appName('miss').getOrCreate()
df = spark.read.csv('miss.csv',header=True,inferSchema=True)
df.show()
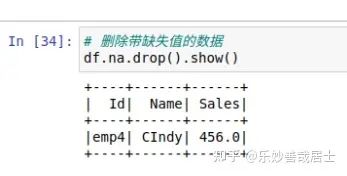
# 删除带缺失值的数据
df.na.drop().show()
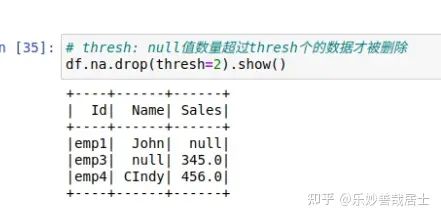
# thresh: null值数量超过thresh个的数据才被删除
df.na.drop(thresh=2).show()
# how: 删除策略(all/any)
df.na.drop(how='all').show()
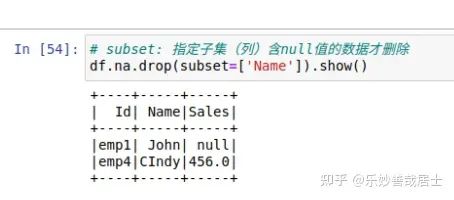
# subset: 指定子集(列)含null值的数据才删除
df.na.drop(subset=['Name']).show()
# pyspark自可以自动推断类型,在填充缺失值时很有帮助
df.printSchema()
# 输入字符串,就自动填充字符串类型的数据
df.na.fill('FILL VALUE').show()
# 输入number,就自动填充number类型的数据
df.na.fill(0).show()
# 指定列填充指定数据
df.na.fill('No Name',subset=['Name']).show()
mean_val = df.select(mean(df['Sales'])).collect()
mean_sale = mean_val[0][0]
print(mean_sale)
# 给缺失值填充该列的平均值
df.na.fill(mean_sale,['Sales']).show()
df.na.fill(df.select(mean(df['Sales'])).collect()[0][0],['Sales']).show()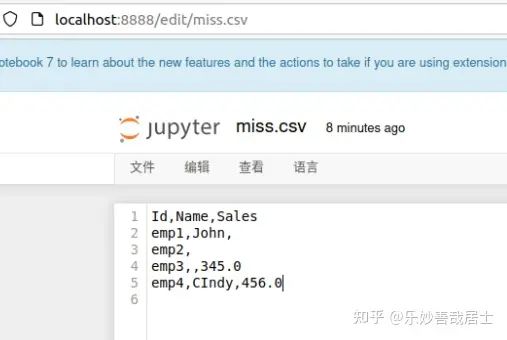




6-时间类型处理
from pyspark.sql import SparkSession
from pyspark.sql.functions import (dayofmonth,hour,dayofyear,
month,year,weekofyear,
format_number,date_format)
spark = SparkSession.builder.appName('miss').getOrCreate()
df = spark.read.csv('appl_stock.csv',header=True,inferSchema=True)
df.head(1)
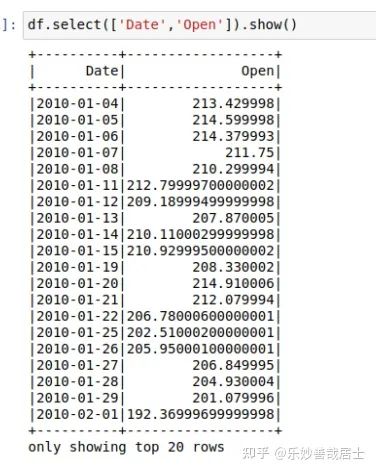
df.select(['Date','Open']).show()
# 获取每个Date数据(year-month-day)的day
df.select(dayofmonth(df['Date'])).show()
# 获取每个Date数据(year-month-day)的month
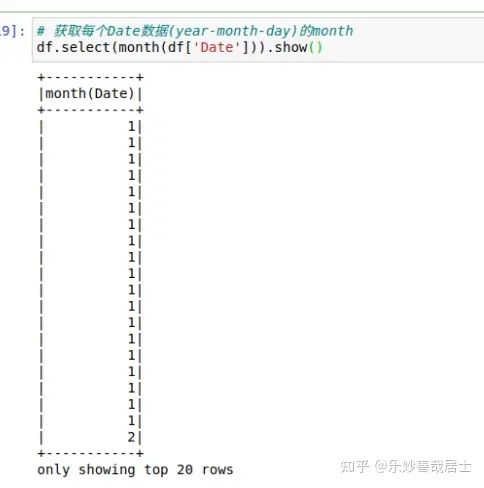
df.select(month(df['Date'])).show()
# 获取每个Date数据(year-month-day)的year
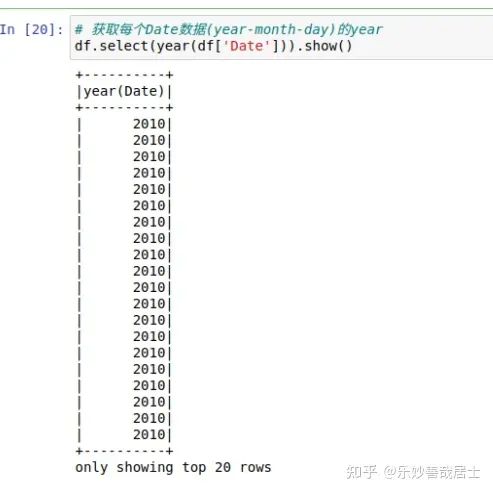
df.select(year(df['Date'])).show()
# 得到Date数据里的year并作为新的一列合并到原表格
newdf = df.withColumn('Year',year(df['Date']))
# 每年的平均Close
result = newdf.groupBy('Year').mean().select(['Year','avg(Close)'])
# 重命名列
new = result.withColumnRenamed('avg(Close)','Average CLosing Price')
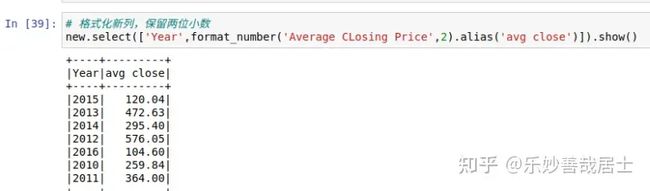
# 格式化新列,保留两位小数
new.select(['Year',format_number('Average CLosing Price',2).alias('avg close')]).show()