MySQL数据表查询

作者介绍:一个有梦想、有理想、有目标的,且渴望能够学有所成的追梦人。
学习格言:不读书的人,思想就会停止。——狄德罗
⛪️个人主页:进入博主主页
专栏系列:进入MySQL知识专栏
欢迎小伙伴们访问到博主的文章内容,在浏览阅读过程发现需要纠正的地方,烦请指出,愿能与诸君一同成长!
目录
文章内容如下
✏️一、表达式
one / 定义
two / 运算符
1、算术运算符
2、赋值运算符
3、⽐较运算符
4、逻辑运算符
5、字符匹配运算
6、优先级
✏️二、基本查询
one / 基本语法
two / 查询全部字段数据(*)
three / 局部字段查询
four / 前N条数
five / 条件查询
six / 别名( as)
seven / 字符连接(+)
eight / 排序查询
nine / 聚合函数
ten / 筛选重复数据(去重)
eleven / 分组查询
twelve / 模糊查询
thirteen / 正则查询
fourteen / case when查询
fifteen / ⾏转列
✏️三、多表查询
one / 等值查询
two / 内连接
three / 外连接
1、左外连接
2、右外连接
3、完全外连接
four / 交叉连接
five / ⾃连接
six / 联合查询
✏️四、⼦查询
one / 概念
one / 三种实现
1、[NOT] IN
2、⽐较运算符 [any | some | all]
3、[not] exists
three / 特殊使⽤
✏️五、常⽤函数
one / 字符函数
two / 字符函数
three / ⽇期函数
four / 流程控制函数
1、if:处理双分⽀
2、IFNULL(value1,value2)
3、case语句:处理多分⽀
five / 其他函数
✏️总结
文章内容如下
✏️一、表达式
one / 定义
操作数与操作符组合的式⼦。
操作数:可以是常量、变量、函数的返回值、另⼀个查询语句返回的值;
操作符:就是运算符,包括算术运算符、赋值运算符、⽐较运算符、逻辑运算符、字符匹配运算等。
two / 运算符
1、算术运算符

select 1+1,1/2;
2、赋值运算符
=(⽐较运算符也是=)
3、⽐较运算符
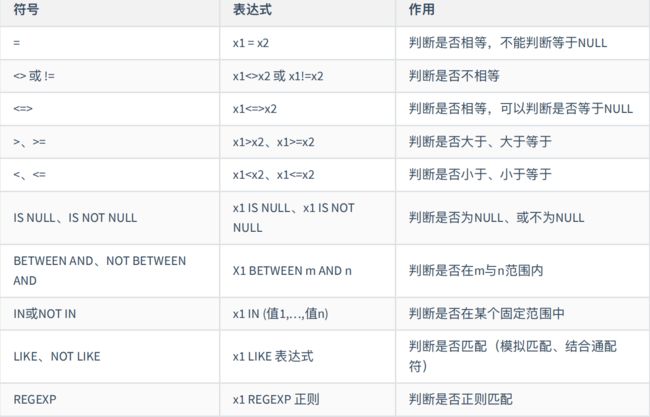
注意:运算结果只能为真(1)或假(0)
#匹配username是否以字符t开始
select username,username REGEXP'^t'from student;#区别=与<=>
select username,address=nullfrom student;
select username,address<=>nullfrom student;4、逻辑运算符
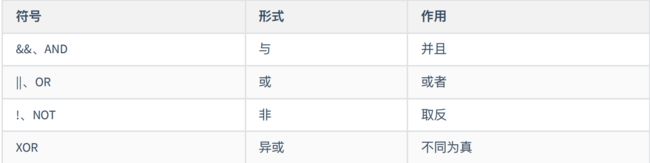
5、字符匹配运算
- BETWEEN...AND:如果操作数在某个范围之内,那么就为 TRUE
- IN:如果操作数等于表达式列表中的⼀个,那么就为 TRUE
- like:如果操作数与⼀种模式相匹配,那么就为 TRUE
- %:零个或任意个字符;
- _:任意⼀个字符;
- []:指定⼀个字符、字符串或范围,从中选择⼀个匹配对象;
- [^]:所匹配的字符为指定字符以外的⼀个字符
6、优先级
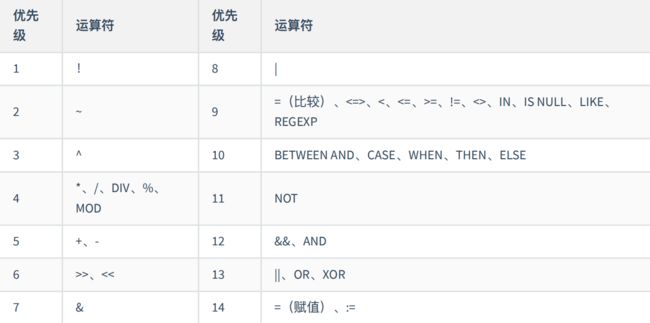
注意:可以通过()提⾼优先级。
✏️二、基本查询
one / 基本语法
select[distinct][顶部条数|聚合函数]字段集合|常量|表达式|函数|*
from表名
[where查询条件语句集合]
[groupby分组字段列表]
[having过滤条件语句集合]分组查询条件
[orderby排序字段集合[asc|desc]]
[LIMIT[,]]
# 执⾏顺序:FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT two / 查询全部字段数据(*)
select * from 表名 ;three / 局部字段查询
select 字段1,...,字段n from 表名 ;four / 前N条数
# 在MySQL中,top N⽆效,使⽤ limit 实现
select top N | top n percent ... from 表名 ;
select * from 表名 limit N
select * from 表名 limit [offset,] rows
# 分⻚查询
select * from 表名 limit (当前⻚-1) * 每⻚记录数,每⻚记录数offset:起始值,默认从0开始
rows:查询记录数
five / 条件查询
select 字段集合 | * from 表名 where 条件查询条件可以是
- 带⽐较运算符和逻辑运算符的查询条件
- 带 BETWEEN AND 关键字的查询条件
- 带 IS NULL 关键字的查询条件
- 带 IN、NOT IN 关键字的查询条件
- 带 LIKE 关键字的查询条件
six / 别名( as)
# 为字段指定别名
select 字段 [as] 别名 ...
# 为表名指定别名
select *|字段集合 from 表名 as 别名seven / 字符连接(+)
# 注:在MySQL中,+表示的是运算符,不能⽤于字符串连接
select 1 + 1;
# 把字符尝试转换为数值,如果转换成功,则得到对应的数值,如果转换失败,则为0
select 1 + '1' ;
select 1 + '你' ;
# null + 任何数据 = null
select 1 + null ;
# 实现字符连接,可以使⽤concat函数 eight / 排序查询
# 单字段排序,默认为ASC
order by 字段 ASC | DESC
# 多字段排序
# 注意:在对多个字段进⾏排序时,排序的第⼀个字段必须有相同的值,才会对第⼆个字段进⾏排序。如果第⼀个字段数据中所有
的值都是唯⼀的,MySQL 将不再对第⼆个字段进⾏排序。
order by 字段1 ASC | DESC,字段2 ASC | DESCnine / 聚合函数
如下
- sum() : 求和
- avg() : 平均值
- max() : 最⼤值
- min() : 最⼩值
- count() : 记录数
注意
- 也叫分组函数,⼀般⽤于分组查询
- 以上五个分组函数都忽略null值,除了count(*);
- sum和avg⼀般⽤于处理数值型,max、min、count可以处理任何数据类型;
- 如果count字段,则字段值为NULL的情况,将忽略统计
ten / 筛选重复数据(去重)
select distinct *|字段集合 from ...注意
如果DISTINCT 关键字后有多个字段,则会对多个字段进⾏组合去重,也就是说,只有多个字段组合起来完
全是⼀样的情况下才会被去重。
eleven / 分组查询
select 字段,聚合函数
from 表名
group by 字段
【WITH ROLLUP】
having 条件注意
select后⾯跟着的字段必须满⾜两个条件,要么分组字段、要么使⽤聚合函数;
分组查询⼀般结合聚合函数⼀起使⽤;
where是分组前条件,having是分组后条件。
案例
SELECT 性别,COUNT(*) FROM `学⽣信息`
GROUP BY 性别
WITH ROLLUP;
# 解决NULL输出:coalesce(arg1,arg2,arg3,...)
# 如果arg1⾮空,取值arg1,否则取值arg2;继续判断arg2是否为空,依此类推。如果参数都为NULL,则返回NULL
SELECT coalesce(NULL,100) ;
SELECT coalesce(性别,'总⼈数'),COUNT(*) FROM `学⽣信息`
GROUP BY 性别
WITH ROLLUP;twelve / 模糊查询
select * from 表名称 where 字段 like 值 注意
其中,值⼀般结合以下三个通配符使⽤
- _ (下划线):表示任意的1个字符(⻓度不能为0)
- % :表示任意的0个或多个字符
- [] :表示某范围(不⽀持?)
- [^]:表示某范围以外
thirteen / 正则查询
详细了解:点击进入
select * from xx where xx regexp '[xx]'fourteen / case when查询
case when语句,用于计算条件列表并返回多个可能结果表达式之一。
案例
CREATE TABLE test_user
(
id int primary key auto_increment ,
name varchar(50) not null ,
gender tinyint default 1 ,
country_code smallint
) engine=InnoDb default charset=utf8;
insert into test_user(name,gender,country_code) values ('清⻛',1,100) ;
insert into test_user(name,gender,country_code) values ('⽞武',2,100) ;
insert into test_user(name,gender,country_code) values ('Kobe',1,110) ;
insert into test_user(name,gender,country_code) values ('John Snow',1,200) ;
select id,name,gender,
(
case gender
when 1 then '男'
when 2 then '⼥'
else '未知'
end
) 性别,
country_code
from test_user;fifteen / ⾏转列
详细了解:点击进入
案例
create table grade
(
id int(10) not null auto_increment ,
user_name varchar(20),
course varchar(20),
score float ,
primary key(id)
) engine=InnoDb default charset=utf8 ;
insert into grade(user_name,course,score) values ('张三','数学',34) ;
insert into grade(user_name,course,score) values ('张三','语⽂',58) ;
insert into grade(user_name,course,score) values ('张三','英语',58) ;
insert into grade(user_name,course,score) values ('李四','数学',45) ;
insert into grade(user_name,course,score) values ('李四','语⽂',87) ;
insert into grade(user_name,course,score) values ('李四','英语',45) ;
insert into grade(user_name,course,score) values ('王五','数学',76) ;
insert into grade(user_name,course,score) values ('王五','语⽂',34) ;
insert into grade(user_name,course,score) values ('王五','英语',89) ;
SELECT user_name,
max(case course when '数学' then score else 0 end) 数学,
max(case course when '语⽂' then score else 0 end) 语⽂,
max(case course when '英语' then score else 0 end) 英语
from grade GROUP BY user_name ;✏️三、多表查询
如果我们要查询的数据分布在不同的表时,那么需要连接多张表进⾏多表查询
one / 等值查询
select 字段集合 from 表1,表2,...,表n
where 条件 (主外键)注意
- 条件⼀般是主键和外键的关联(可能包含筛选数据的条件);
- ⼀般给各表取别名,提⾼阅读性、性能以及解决字段冲突
案例
create table 教师表
(
编号 int identity(1,1) primary key not null ,
姓名 char(30) ,
性别 char(2) check(性别='男' or 性别='⼥') default '男',
专业 char(30)
)
create table 学⽣表
(
学号 int identity(1,1) primary key not null ,
姓名 char(30) ,
性别 char(2) check(性别='男' or 性别='⼥') default '男',
身⾼ float ,
学分 float ,
教师编号 int foreign key references 教师表(编号)
)
insert into 教师表 values ('张三','男','计算机')
insert into 教师表 values ('李四','男','⽇语')
insert into 教师表 values ('王五','⼥','英语')
insert into 学⽣表 values ('学⽣⼀','男',1.5,50,1)
insert into 学⽣表 values ('学⽣⼆','⼥',2.5,60,1)
insert into 学⽣表 values ('学⽣三','男',3.5,70,2)
insert into 学⽣表 values ('学⽣四','⼥',4.5,80,2)
select * from 教师表
select * from 学⽣表two / 内连接
-- 功能同等值连接
-- 好处:连接条件与筛选条件分离,简洁明了
select 字段集合 from 表1 [inner] join 表2 on 条件(主外键|相同数据类型)
where 条件three / 外连接
1、左外连接
以第⼀张表为基础向第⼆张表匹配,匹配成功则正常显示,匹配不成功,则第⼆张表以NULL值显示
select 字段集合 from 表1 left [outer] join 表2 on 条件2、右外连接
以第⼆张表为基础向第⼀张表匹配,匹配成功则正常显示,匹配不成功,则第⼀张表以NULL值显示
select 字段集合 from 表1 right [outer] join 表2 on 条件3、完全外连接
左、右表的数据都要显示,如果能连接,则正常显示;如果不能连接,则以NULL值显示
# select 字段集合 from 表1 full [outer] join 表2 on 条件
# MySQL不⽀持,可以使⽤UNION实现
SELECT * from 表1 LEFT JOIN 表2 on 条件;
UNION
SELECT * from 表1 RIGHT JOIN 表2 on 条件;four / 交叉连接
-- 语法⼀
select 字段集合 from 表1 [inner] join 表2 #sql server 使⽤关键字 cross
-- 语法⼆
select 字段集合 from 表1,表2five / ⾃连接
-- 语法⼀
select * from 表1 as 别名 join 表1 as 别名 on 条件
-- 语法⼆
select * from 表1 as 别名, 表1 as 别名 where 条件six / 联合查询
把多个查询的结果合并在⼀起
select f1,f2 from _1
union [ALL]
select f1,f2 from _2注意
- 两个查询的字段个数必须相同;
- 字段类型也要相同或兼容;
- union代表去重,union all代表不去重
✏️四、⼦查询
one / 概念
⼀条查询语句中被嵌套到另⼀条完整的查询语句中,其中被嵌套的查询语句,称之为⼦查询或内查询,⽽在外⾯的查询语句,称为主查询或外查询。⽤于⼦查询的关键字主要包括 in、not in、=、!=、exists、not exists 等。
- ⼦查询都放在⼩括号内;
- ⼦查询可以放在from后⾯、select后⾯、where后⾯、having后⾯,但常⽤于where后⾯;
- ⼦查询优先于主查询执⾏,⼦查询所得的结果服务于主查询;
- ⼦查询根据查询结果的⾏数不同分为以下两类
- 单⾏⼦查询:⼦查询的结果只有⼀⾏
- ⼀般结合单⾏操作符使⽤:>、<、=、 <>、 >=、 <=
- 多⾏⼦查询:⼦查询的结果有多⾏
- ⼀般结合多⾏操作符使⽤:any、all、in、not in
one / 三种实现
1、[NOT] IN
... where 字段 [NOT] IN (⼦查询|数值集合)案例
create table t1
(
n int
);
create table t2
(
n int
);
insert into t1 values (2);
insert into t1 values (3);
insert into t2 values (1);
insert into t2 values (2);
insert into t2 values (3);
insert into t2 values (4);
select * from t2 where n in (1,3);
select * from t2 where n =1 || n=3;
select * from t2 where n not in (1,3);
select * from t2 where !(n = 1 || n = 3);2、⽐较运算符 [any | some | all]
select * from xx where 字段 ⽐较运算符 [any | some | all] (⼦查询)
--如:=any,>any,>=all案例
-- all : 逻辑与(同时满⾜条件)
SELECT * FROM T2 WHERE N>all (SELECT N FROM T1)
SELECT * FROM T2 WHERE N>2 && N>3
-- some、any:逻辑或(满⾜其中之⼀)
SELECT * FROM T2 WHERE N>any (SELECT N FROM T1)
SELECT * FROM T2 WHERE N>some (SELECT N FROM T1)
SELECT * FROM T2 WHERE N>2 || N>3
-- =any、=some、in相同
SELECT * FROM T2 WHERE N=SOME (SELECT N FROM T1);
SELECT * FROM T2 WHERE N=ANY (SELECT N FROM T1);
SELECT * FROM T2 WHERE N IN (SELECT N FROM T1);
-- 思考:以下查询的结果是?
SELECT * FROM T2 WHERE N <> any(SELECT * FROM T1);说明
- 其中,ANY与SOME相同,对⼦查询的结果进⾏逻辑或运算; ⽽All则对⼦查询的结果进⾏逻辑与运算;
- =any 或 =some 等同于 in
- =any 或 =some 后⾯必须要是⼦查询,不能是具体某些数据;⽽in语句后⾯可以是⼦查询,也可以是具体的某
- 些数据
3、[not] exists
-- 判断⼦查询是否有查询结果,有返回true,否则返回false
... where [NOT] EXISTS (⼦查询)three / 特殊使⽤
⼦查询也可以使⽤在SELECT、INSERT、UPDATE或DELETE语句中
✏️五、常⽤函数
one / 字符函数

案例
# 任何字符串与 NULL 进⾏连接的结果都将是 NULL
SELECT concat('aaa','bbb','ccc') ,concat('aaa',NULL);
SELECT substring('beijing2008',8,4),substring('beijing2008',1,7);
SELECT INSERT('beijing2008you',12,3, 'me') ;
SELECT LEFT('beijing2008',7),LEFT('beijing',NULL),RIGHT('beijing2008',4);
SELECT lpad('2008',20,'beijing'),rpad('beijing',20,'2008');two / 字符函数
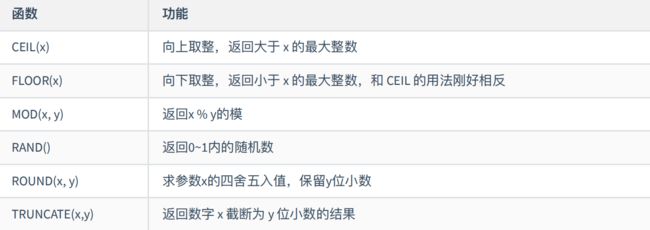
案例
# 如果不写 y,则默认 y 为 0,即将 x 四舍五⼊后取整
select ROUND(1.1),ROUND(1.1,2),ROUND(1,2);
select RAND(),RAND();
# 模数和被模数任何⼀个为 NULL 结果都为 NULL
select MOD(15,10),MOD(1,11),MOD(NULL,10);
select CEIL(-0.8),CEIL(0.8);
select FLOOR(-0.8), FLOOR(0.8);
select ROUND(1.235,2),TRUNCATE(1.235,2);three / ⽇期函数
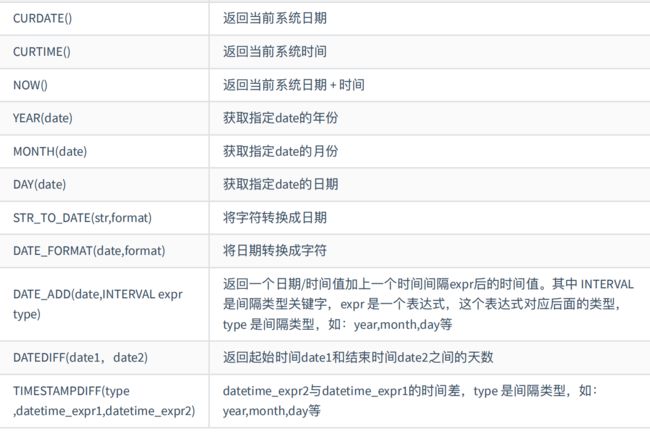
案例
select str_to_date('2021年03⽉09⽇','%Y年%m⽉%d⽇');
select date_format(now(),'%Y年%m⽉%d⽇');
# 两天后
select now() 当前时间,date_add(now(),INTERVAL 2 day) ;
select DATEDIFF('2021-05-01',now());
select TIMESTAMPDIFF(MONTH, '1985-06-24', '1985-08-24') ;four / 流程控制函数
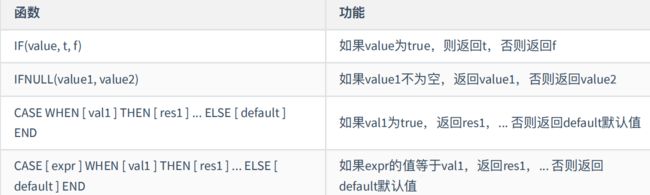
1、if:处理双分⽀
# 如果value是真,返回t;否则返回f
if(value,t,f)
select if(5>1,'你好','我好');2、IFNULL(value1,value2)
如果 value1 不为空返回 value1,否则返回 value2
select IFNULL('你好','我好') ;
select IFNULL(NULL,'我好') ;3、case语句:处理多分⽀
# 情况1:处理等值判断
# 如果 expr 等于 value,返回 result,否则返回 default
CASE expr WHEN value THEN result ... ELSE default END
# 情况2:处理条件判断
# 如果 value 是真,返回 result,否则返回 default
CASE WHEN [value] THEN [result] ... ELSE [default] END
# 案例
create table salary
(
userid int,
salary decimal(9,2)
);
insert into salary values(1,1000),(2,2000), (3,3000),(4,4000),(5,5000), (1,null);
select userid,salary,if(salary>2000,'high','low') from salary;
select ifnull(salary,0) from salary;
select case when salary<=2000 then 'low' else 'high' end from salary;
select case salary when 1000 then 'low' when 2000 then 'mid' else 'high' end from salary;five / 其他函数

select version() ;
select database() ;
select user() ;✏️总结
基础打得好,才便于后面的学习,以及未来的发展!加油!.
