数值分析第九章节 用Python实现常微分方程初值问题的数值解法
参考书籍:数值分析 第五版 李庆杨 王能超 易大义编 第9章 常微分方程初值问题的数值解法
文章声明:如有发现错误,欢迎批评指正
文章目录
- 欧拉法
- 后退的欧拉方法
- 梯形方法
- 改进欧拉公式
- 补充
-
- 龙格—库塔方法
- 线性多步法
-
- 阿当姆斯显示与隐式公式
9.1引言
科学技术中的很多问题可以使用常微分方程的定解描述,包括初值问题以及边值问题两个大类。考虑一阶常微分方程的初值问题, y ′ = f ( x , y ) , x ∈ [ x 0 , b ] , y ( x 0 ) = y 0 . y'=f(x,y),x \in[x_0,b],y(x_0)=y_0. y′=f(x,y),x∈[x0,b],y(x0)=y0.如果存在实数 L > 0 L>0 L>0,使得 ∣ f ( x , y 1 ) − f ( x , y 2 ) ∣ ≤ L ∣ y 1 − y 2 ∣ , ∀ y 1 , y 2 ∈ R , |f(x,y_1)-f(x,y2)|\leq L|y_1-y_2|,\forall y_1,y_2\in R, ∣f(x,y1)−f(x,y2)∣≤L∣y1−y2∣,∀y1,y2∈R,则称f关于y满足利普西茨条件, L L L为 f f f的利普西茨常数。 定理1(唯一性): 设 f f f在区域 D = { ( x , y ) ∣ a ≤ x ≤ b , y ∈ R } D=\{(x,y)|a\leq x\leq b,y \in R\} D={(x,y)∣a≤x≤b,y∈R}上连续,关于y则满足利普西茨条件,则对任意 x 0 ∈ [ a , b ] , y 0 ∈ R x_0\in[a,b],y_0\in R x0∈[a,b],y0∈R,常微分的初值问题在 x ∈ [ a , b ] x\in[a,b] x∈[a,b]上存在唯一的连续可微解 y ( x ) y(x) y(x)。 定理2(敏感性的分析): 设 f f f在区域 D D D上连续,且关于y满足利普西茨条件,设初值问题 y ′ ( x ) = f ( x , y ) , y ( x 0 ) = s y'(x)=f(x,y),y(x_0)=s y′(x)=f(x,y),y(x0)=s的解为 y ( x , s ) y(x,s) y(x,s),则 ∣ y ( x , s 1 1 ) − y ( x , s 2 ) ∣ ≤ e L ∣ x − x 0 ∣ ∣ s 1 − s 2 ∣ |y(x,s1_1)-y(x,s_2)|\leq e^{L|x-x_0|}|s_1-s_2| ∣y(x,s11)−y(x,s2)∣≤eL∣x−x0∣∣s1−s2∣。显然,当 L L L较大时认为坏条件,当 L L L较小时认为好条件。实际问题之中遇到的常微分方程大部分没有解析解,所以主要依靠数值解法。
9.2简单的数值解法
9.2.1欧拉法与后退欧拉法
欧拉法
欧拉方法:使用公式 y n + 1 = y n + h f ( x n , y n ) y_{n+1}=y_n+hf(x_n,y_n) yn+1=yn+hf(xn,yn)逐次地推导算出最终结果。
例1:求解初值问题
{ y ′ = y − 2 x y , 0 < x < 1 , y ( 0 ) = 1. \left\{\begin{matrix}y'=y-\frac{2x}{y},0
得到:
y n + 1 = y n + h ( y n − 2 x n y n ) y_{n+1}=y_n+h(y_n-\frac{2x_n}{y_n}) yn+1=yn+h(yn−yn2xn)
def func(x,y):
if x==None:
return 1
return y+0.1*(y-2*x/y)
x_initial,y_initial=None,None
for i in range(11):
y_initial=func(x_initial,y_initial);x_initial=i/10
print("数值解{:.4f} 解析解{:.4f}".format(y_initial,pow(1+2*i/10,0.5)))

分析欧拉方法误差:通过对 y n + 1 y_{n+1} yn+1进行泰勒二阶展开。 y ( x n + 1 ) = y ( x n ) + y ′ ( x n ) h + y ′ ′ ( ξ n ) 2 ! h 2 y(x_{n+1})=y(x_n)+y'(x_n)h+\frac{y''(\xi_n)}{2!}h^2 y(xn+1)=y(xn)+y′(xn)h+2!y′′(ξn)h2。称 y ( x n + 1 ) − y ( x n ) = y ′ ( x n ) h + y ′ ′ ( ξ n ) 2 ! h 2 y(x_{n+1})-y(x_n)=y'(x_n)h+\frac{y''(\xi_n)}{2!}h^2 y(xn+1)−y(xn)=y′(xn)h+2!y′′(ξn)h2此方法为局部截断误差。另外一种分析方法:我们对 y ′ = f ( x , y ) , x ∈ [ x 0 , b ] y'=f(x,y),x \in[x_0,b] y′=f(x,y),x∈[x0,b]进行微分。 y ( x n + 1 ) + y ( x n ) = ∫ x n x n + 1 f ( t , y ( t ) ) d t y(x_{n+1})+y(x_n)=\int^{x_{n+1}}_{x_n}f(t,y(t))dt y(xn+1)+y(xn)=∫xnxn+1f(t,y(t))dt。如果使用左矩形公式则可以得到上述公式,如果使用右矩形公式则可以得到另外一公式 y n + 1 = y n + h f ( x n + 1 , y n + 1 ) y_{n+1}=y_n+hf(x_{n+1},y_{n+1}) yn+1=yn+hf(xn+1,yn+1)。称为后退的欧拉法。后退的欧拉方法是隐式,欧拉方法则是显式。
后退的欧拉方法
设用欧拉公式 y n + 1 ( 0 ) = y n + h f ( x n , y n ) y_{n+1}^{(0)}=y_n+hf(x_n,y_n) yn+1(0)=yn+hf(xn,yn)给出迭代初值 y n + 1 ( 0 ) y_{n+1}^{(0)} yn+1(0)不断迭代则得到 y n + 1 ( k + 1 ) = y n + h f ( x n , y n ( k ) ) , k = 0 , 1 , … , n y_{n+1}^{(k+1)}=y_n+hf(x_n,y_n^{(k)}),k=0,1,\dots,n yn+1(k+1)=yn+hf(xn,yn(k)),k=0,1,…,n。只要 h L hL hL<1就可以收敛到解 y n + 1 y_{n+1} yn+1了。误差分析同欧拉方法是差不多的。我们这里使用例4进行演示同时探讨两个方法绝对稳定性以及绝对稳定域。
例4:求解初值问题
{ y ′ = − 100 y , y ( 0 ) = 1. \left\{\begin{matrix}y'=-100y,\\y(0)=1.\end{matrix}\right. {y′=−100y,y(0)=1.
可以解得:
y ( x ) = e − 100 x y(x)=e^{-100x} y(x)=e−100x
lt1=[]
x_initial=0;y_initial=1
for i in range(4):
y_initial=y_initial+1/40*(-100*y_initial);x_initial=i/40
lt1.append(y_initial)
lt2=[]
x_initial=0;y_initial=1
for i in range(4):
y_initial=y_initial/(1+100*0.025)
lt2.append(y_initial)
for i in range(4):
print("欧拉法:{:>8.4f} 后退的欧拉法:{:>8.4f}".format(lt1[i],lt2[i]))
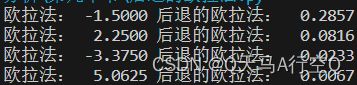
可以看到 h h h为0.025时,欧拉法不稳定但是后退的欧拉法稳定。 h h h为0.005时,欧拉法变稳定(这个部分我没有做)。所以得出结论稳定性不仅与方法还与步长有关。现在我们来具体地探讨欧拉方法的稳定性。模型方程 y ′ = λ y y'=\lambda y y′=λy的欧拉公式为 y n + 1 = ( 1 + h λ ) y n y_{n+1}=(1+h\lambda)y_n yn+1=(1+hλ)yn。设在节点 y n y_n yn有一扰动值 ϵ n \epsilon_n ϵn,在 y n + 1 y_{n+1} yn+1产生大小为 ϵ n + 1 \epsilon_{n+1} ϵn+1扰动值。所以有 ϵ n + 1 = ( 1 + h λ ) ϵ n \epsilon_{n+1}=(1+h\lambda)\epsilon_n ϵn+1=(1+hλ)ϵn。假设差分方程解是不增长的,根据稳定性的定义有 ∣ 1 + h λ ∣ ≤ 1 |1+h\lambda|\leq1 ∣1+hλ∣≤1。对于后退的欧拉法有 y n + 1 = 1 1 − h λ y n y_{n+1}=\frac{1}{1-h\lambda}y_n yn+1=1−hλ1yn则 ∣ 1 1 − h λ ∣ < 1 |\frac{1}{1-h\lambda}|<1 ∣1−hλ1∣<1则稳定域为 ∣ 1 − h λ ∣ > 1 |1-h\lambda|>1 ∣1−hλ∣>1。
梯形方法
使用 y n + 1 = y n + h 2 [ f ( x n , y n ) + f ( x n + 1 , y n + 1 ) ] y_{n+1}=y_n+\frac{h}{2}[f(x_n,y_n)+f(x_{n+1},y_{n+1})] yn+1=yn+2h[f(xn,yn)+f(xn+1,yn+1)]为公式作为单步推导的方法叫梯形方法。求解方法等同后退的欧拉法。
使用例4作为演示(就是上面的那一个)
lt=[]
x_initial=0;y_initial=1
for i in range(4):
y_initial=(1-50*0.025)*y_initial/(1+50*0.025)
lt.append(y_initial)
for i in range(4):
print("梯形方法:{:>8.4f}".format(lt[i]))

同样我们这里讨论梯形方法的稳定性: y n + 1 = 1 − h 2 λ 1 + h 2 λ y n + 1 y_{n+1}=\frac{1-\frac{h}{2}\lambda}{1+\frac{h}{2}\lambda}y_{n+1} yn+1=1+2hλ1−2hλyn+1则 ∣ 1 − h 2 λ 1 + h 2 λ ∣ ≤ 1 |\frac{1-\frac{h}{2}\lambda}{1+\frac{h}{2}\lambda}|\leq1 ∣1+2hλ1−2hλ∣≤1,同时这里,我们给出一个定义: 如果一个数值方法的稳定域包含了 { h λ ∣ R e ( h λ ) < 0 ∣ \{h\lambda|Re(h\lambda)<0| {hλ∣Re(hλ)<0∣,那么称此方法是A-稳定的。后退的欧拉法以及梯形方法都是A-稳定的不需要考虑步长 h h h。
改进欧拉公式
先用一次欧拉公式得到 y n y_n yn值,因为效果可能很差所以使用梯形公式进行校准。公式如下,十分简单:
{ 预测 y ˉ n + 1 = y n + h f ( x n , y n ) , 校正 y n + 1 = y n + h 2 [ f ( x n , y n ) + f ( x n + 1 , y ˉ n + 1 ) ] . \left\{\begin{matrix}预测\;\bar{y}_{n+1}=y_n+hf(x_n,y_n),\\\\校正\;y_{n+1}=y_n+\frac{h}{2}[f(x_n,y_n)+f(x_{n+1},\bar{y}_{n+1})].\end{matrix}\right. ⎩ ⎨ ⎧预测yˉn+1=yn+hf(xn,yn),校正yn+1=yn+2h[f(xn,yn)+f(xn+1,yˉn+1)].
我们使用例2演示:emmm,这个例2就是让你使用改进欧拉方法做遍例1,题目欧拉法那已经写了我就不再写了。
def func(x,y):
y1=y+0.1*(y-2*x/y)
y2=y+0.1/2*(y-2*x/y+y1-2*(x+0.1)/y1)
return y2
x_initial,y_initial=0,1
for i in range(1,11):
y_initial=func(x_initial,y_initial);x_initial=i/10
print("数值解{:.4f} 解析解{:.4f}".format(y_initial,pow(1+2*i/10,0.5)))
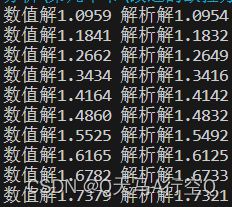
这个的稳定域还得看 f ( x , y ) f(x,y) f(x,y)(这句话可能有问题,我不是特别地确定)。
现在我们讨论一下单步法局部稳定性和阶。显式单步法的局部截断误差: T n + 1 = y ( x n + 1 ) − y ( x n ) − h φ ( x n , y ( x n ) , h ) T_{n+1}=y(x_{n+1})-y(x_n)-h\varphi(x_n,y(x_n),h) Tn+1=y(xn+1)−y(xn)−hφ(xn,y(xn),h)。欧拉法的局部截断误差为 T n + 1 = y ( x n + 1 ) − y ( x n ) − h f ( x n , y ( x n ) ) = h 2 2 y ′ ′ ( x n ) + O ( h 3 ) T_{n+1}=y(x_{n+1})-y(x_n)-hf(x_n,y(x_n))=\frac{h^2}{2}y''(x_n)+O(h^3) Tn+1=y(xn+1)−y(xn)−hf(xn,y(xn))=2h2y′′(xn)+O(h3)(泰勒展开,简单得很)。然后两个一般概念,P阶精度以及局部误差主项。这两个定义我感觉还是挺重要的,鉴于篇幅原因还是请回到书本吧。
现在我们讨论一下单步法收敛性与相容性。数值解法基本思想:将微分方程化为差分方程吧。好了这里好像一大堆的公式,鉴于篇幅原因还是请回到书本吧。其实感觉可以不用去看推导。知道有就好了。数值方法收敛性的定义;关于收敛性的定理;相容定义;判断相容与否定理。
补充
补充内容感觉不考但是工程中都挺重要的,所以还是来做做吧。这个部分知识点还是自己研究吧。我用Py做一下例题。
龙格—库塔方法
例3:使用4阶龙格库塔方法求解例1
def K1(x,y):
return y-2*x/y
def K2(x,y):
return y+0.2/2*K1(x,y)-(2*x+0.2)/(y+0.2/2*K1(x,y))
def K3(x,y):
return y+0.2/2*K2(x,y)-(2*x+0.2)/(y+0.2/2*K2(x,y))
def K4(x,y):
return y+0.2*K3(x,y)-(2*(x+0.2))/(y+0.2*K3(x,y))
x,y=0,1
for i in range(5):
y=y+0.2/6*(K1(x,y)+2*K2(x,y)+2*K3(x,y)+K4(x,y));x+=0.2
print("数值解{:.4f} 解析解{:.4f}".format(y,pow(1+2*i/10,0.5)))

PS1:我这样写效率不高因为重复算了很多东西,可以自己试着修改。
PS2:可以自己试着求解四阶龙格库塔方法的稳定域(直接让你浪费生命的10分钟)。
线性多步法
在逐步推进求解过程中,计算 y n + 1 y_{n+1} yn+1之前事实上已经求出了一系列近似值 y 0 , y 1 , … , y n y_0,y_1,\dots,y_n y0,y1,…,yn,如果充分利用前面多步信息预测 y n + 1 y_{n+1} yn+1则可以获得较高精度。一般的线性多步法公式表示为 y n + k = ∑ i = 0 k − 1 α i y n + i + h ∑ i = 0 k β f n + i y_{n+k}=\sum\limits_{i=0}^{k-1}\alpha_iy_{n+i}+h\sum\limits_{i=0}^k\beta f_{n+i} yn+k=i=0∑k−1αiyn+i+hi=0∑kβfn+i。还是有必要看一下线性多步法的构造途径但是这里我们不再过多赘述。感觉原书这一部分排版不是很好。
阿当姆斯显示与隐式公式
考虑形 y n + k = y n + k − 1 + h ∑ i = 0 k β i f n + i y_{n+k}=y_{n+k-1}+h\sum\limits_{i=0}^k\beta_if_{n+i} yn+k=yn+k−1+hi=0∑kβifn+i 的 k 的k 的k步法,称为阿当姆斯方法。当 β k \beta_k βk为0时,显示方法;不为0时,隐式方法。
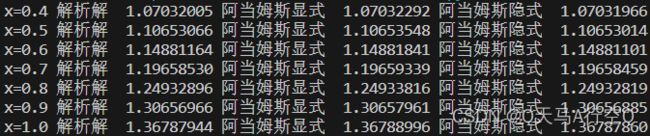
例6:使用四阶阿当姆斯显示以及隐式方法求初值问题 y = − y + x + 1 , y ( 0 ) = 1 y=-y+x+1,y(0)=1 y=−y+x+1,y(0)=1,取步长 h = 0.1 h=0.1 h=0.1。
import math
lt1=[]
def func1():
for i in range(11):
lt1.append(pow(math.e,-i/10)+i/10)
func1()
def f(x,y):
return -y+x+1
lt2=lt1[:4]
def func2():
for i in range(4,11):
lt2.append(lt2[-1]+0.1/24*(55*f(i/10-0.1,lt2[-1])-59*f(i/10-0.2,lt2[-2])+37*f(i/10-0.3,lt2[-3])-9*f(i/10-0.4,lt2[-4])))
func2()
lt3=lt1[:3]
def func3():
for i in range(3,11):
lt3.append(1/24.9*(22.1*lt3[-1]+0.5*lt3[-2]-0.1*lt3[-3]+0.24*(i-3)+3))
func3()
for i in range(4,11):
print("x={:.1f}".format(i/10),end=" ")
print("解析解{:>12.8f} 阿当姆斯显式{:>12.8f} 阿当姆斯隐式{:>12.8f}".format(lt1[i],lt2[i],lt3[i]))
搞定。