Linux CPU性能优化 —— CPU平均负载及高负载排查
文章目录
- 了解系统CPU负载:uptime 和 top
-
- 什么是平均负载
- 平均负载合理区间
- 补:使用top命令查看CPU核心数
- 平均负载和CPU使用率的区别
- 高负载模拟排查
-
- 安装系统压力测试工具
- CPU密集型高负载排查:stress、mpstat和pidstat
- CPU密集型高负载排查:stress、mpstat和pidstat
- 参考文献
写在前面:
由于之前在开发分布式系统中由于云服务器性能原因,导致系统总是断连等错误。但是之前一般只是简单gdb调试一下,定位错误异常艰难,所以决定开设此专栏,系统的记录我学习Linux 性能优化的历程。
作者邮箱:2107810343@qq.com
时间:2021/04/28 18:28
实现环境:Linux
系统:ubuntu 18.04
了解系统CPU负载:uptime 和 top
当我们发现我们系统运行明显变慢的时候,我们就可以使用 uptime命令查看一下:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ uptime
18:36:24 up 1 day, 5:18, 0 users, load average: 1.00, 1.00, 1.00
下面详细解释一下每一个输出的意义:
18:36:24 //当前时间
up 1 day, 5:18 //系统运行时间,表示运行了一天零5小时18分钟
0 users // 当前登录用户数
load average: 1.11, 1.07, 1.01 //每1分钟、5分钟、15分钟的平均负载
什么是平均负载
平均负载是指在单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数,它和CPU使用率并没有直接关系。简单的来说,平均负载其实也就是单位时间内平均活跃进程数。
可运行状态:正在使用CPU或正在等待CPU的进程,也就是在运行态和就绪态的进程。
不可中断状态:正处于内核态关键流程中的进程,并且这些流程是不可被打断的。和阻塞态还是有不同的
好了,我们大概知道了平均负载的概念了,那么了解它有什么意义呢?
假如说,我们的平均负载为2,大家这么一看是不是以为它超载了?
不是这样的,这个跟CPU核心数也有关系的:
- CPU核心数=1:有一般的进程单位时间内竞争不到CPU资源
- CPU核心数=2:刚好所有CPU都被占用
- CPU核心数=4:有CPU有50%的空闲
平均负载合理区间
了解了平均负载的概念,那么这个值一般在什么区间会比较合理呢?我们需要引入负载率这个概念:负载率=平均负载/CPU核心数,那么一般来说,这个负载率在(0,2] 应该是正常区间。
补:使用top命令查看CPU核心数
刚刚在讲平均负载的时候,提到了CPU核心数的概念。那么如何查看CPU核心数呢?
这个就需要使用 top 了:
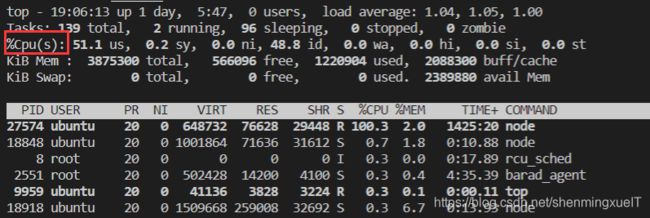
红框位置表示的是CPU的平均使用率,后面的参数会在这个系列专栏的后面讲到。但是现在还是没有看到有几个核心,这个时候我们需要在这个界面输入一个1,然后就会出现如下信息:
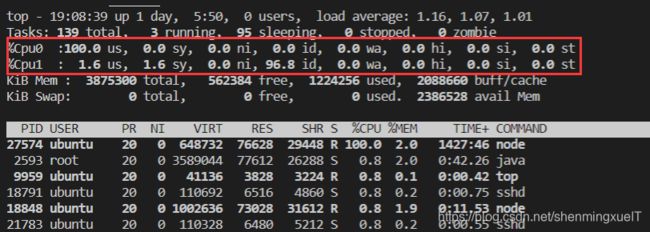
可以看到,有两个核心。嗯,我买的也是2核4G的云服务,腾讯没有糊弄我。
平均负载和CPU使用率的区别
大家刚刚接触平均负载的概念,很容易和CPU使用率相混淆,但是这两个是有着本质区别的。
可能大家会理解,平均负载高了不就意味着CPU的使用率高了么? 不是这样的,平均负载的定义大家可以再看一下,它不仅包括了正在使用CPU的进程还包括等待CPU和等待I/O的进程。
而CPU使用率,是单位时间内CPU的繁忙情况,跟平均负载不一定对应。这是有进程的类型所决定的:
- 如果进程是CPU密集型:此时两者一致。
- 如果进程是I/O密集型:由于进程都是I/O密集的,就算单位时间内执行的进程很多,也不会导致CPU使用率的增长。
注意:
如果有大量等待CPU的进程调度也会导致二者一起增高,因为CPU需要频繁的调度进程。
高负载模拟排查
安装系统压力测试工具
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ sudo apt install stress sysstat
CPU密集型高负载排查:stress、mpstat和pidstat
这里我们需要使用两个工具:stress和mpstat
- stress:顾名思义,其是压力模拟测试工具
- mpstat:多核CPU性能分析工具,试试查看每个CPU的性能指标以及所有CPU的平均指标
- pidstat:常用进程性能分析工具,实时查看进程的CPU、内存和I/O及上下文切换等性能指标
首先我们先查看一下当前的系统CPU负载:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ uptime
19:24:54 up 1 day, 6:06, 0 users, load average: 1.06, 1.02, 1.00
然后用 stress 工具模拟 CPU 100%使用场景:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ stress --cpu 1 --timeout 600
stress: info: [13556] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
现在再查看一下当前的系统CPU负载情况:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ watch -d uptime
Every 2.0s: uptime VM-0-2-ubuntu: Wed Apr 28 19:27:42 2021
19:27:42 up 1 day, 6:09, 0 users, load average: 2.01, 1.39, 1.14
可以看到是负载是2.01,在2核心的情况下,代表我们的CPU是全部使用了的。
我们再开一个页面,去使用 mpstat 查看一下当前CPU使用率的情况:
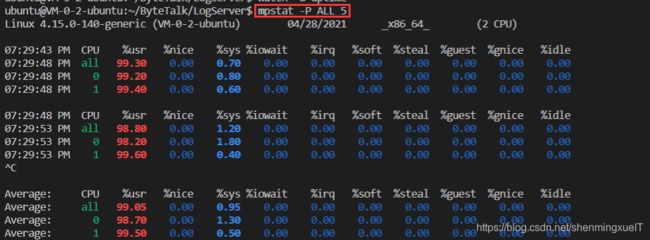
可以看到,无论是核心1 还是核心2 中的CPU使用率都十分接近 100%。
注:
这里-P ALL的意思表示监控所有CPU并且每隔5s输出一次
出现了高负载情况,我们肯定需要去排查一下,可以使用以下命令:
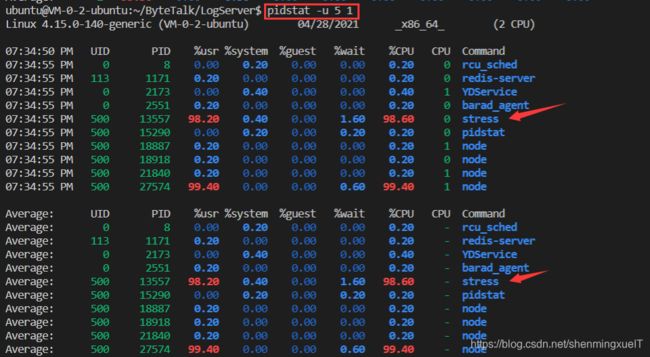
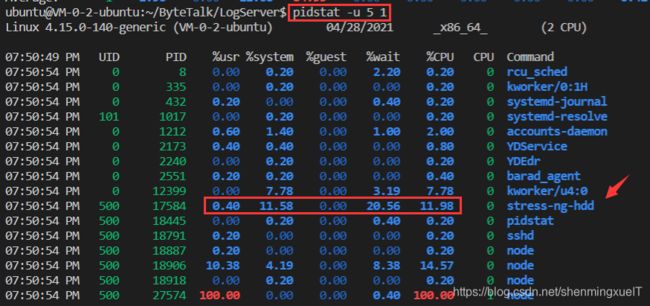
可以明显看到 stress占用了大量的CPU资源。
注:
pidstat -u 5 1表示每隔五秒输出一组数据
CPU密集型高负载排查:stress、mpstat和pidstat
和I/O密集型步骤基本一致。
这里因为博主的虚拟机比较新,可能缓冲区比较小,无法产生大的I/O压力,需要安装一下stress的下一代,stress-np:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ sudo apt install stress-ng
先模拟I/O压力:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ stress-ng -i 1 --hdd 1 --timeout 600
stress-ng: info: [17582] dispatching hogs: 1 io, 1 hdd
查看当前负载情况:
ubuntu@VM-0-2-ubuntu:~/ByteTalk/LogServer$ watch -d uptime
Every 2.0s: uptime VM-0-2-ubuntu: Wed Apr 28 19:46:39 2021
19:46:39 up 1 day, 6:28, 0 users, load average: 2.53, 1.88, 1.62
查看CPU使用率情况:
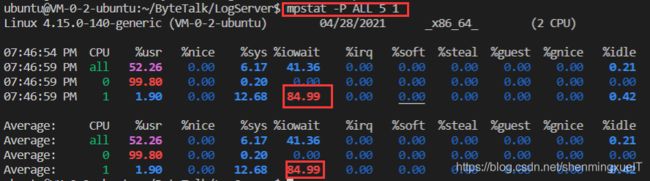
可以看到现在的平均负载已经超过2了,但是一个CPU负载在1.9的时候%iowait已经升高到84.99,这说明平均负载的升高时由于iowait的升高导致的。
再使用pidstat 看看是哪个进程占用了I/O资源:
参考文献
[1] 倪朋飞.Linux性能优化实战.极客时间