程序编译连接加载过程详解
程序加载过程详解
可重定位的elf文件格式简介
首先我们打开目标文件看一下

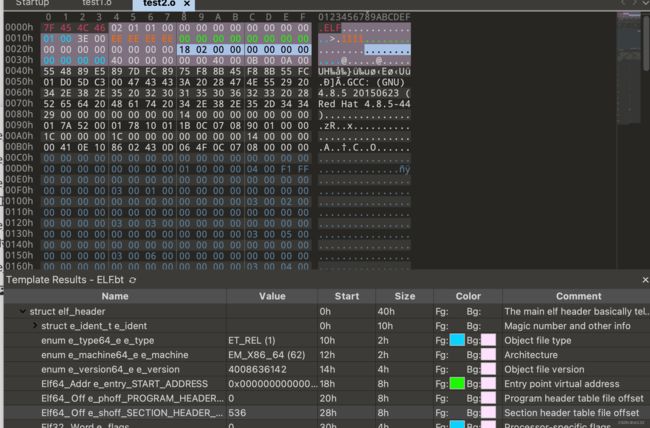
上面的图就是目标文件的格式了,这里使用的是010editer,这个二进制编辑器很好用
可以看到大致分为三部分,首先是header,然后是sectionheader,最后是symbiktable,下面我们来依次讲一讲这些部分都有什么用。
上面蓝色底色的是elfheader的部分,elfheader这里存放的主要是一些描述信息
首先是ei_dent:包含了Maigc Number和其它信息,共16字节。
0~3:前4字节为Magic Number,固定为ELFMAG。7f454c46就是.elf字符,这部分就是文件类型的魔数跟class文件的coffbaby还有dos文件的.dos是一样的东西,这部分不能修改是固定的
4(EI_CLASS):ELFCLASS32代表是32位ELF,ELFCLASS64 代表64位ELF。这部分对于加载和链接都毫无用处
5(EI_DATA):ELFDATA2LSB代表小端,ELFDATA2MSB代表大端。我们的文件里是ELFDATA2LSB小端
6(EI_VERSION):这也是个枚举固定为EV_CURRENT(1)。也没用
7(EI_OSABI):操作系统ABI标识(实际未使用)。
8(EI_ABIVERSION):ABI版本(实际 未使用)。
9~15:对齐填充,无实际意义。
剩下的elfheader的其余部分如下(这是从elf.h里copy出来的):
Elf_Half e_type; /* Object file type */
Elf_Half e_machine; /* Architecture */
Elf_Word e_version; /* Object file version */
Elf_Addr e_entry; /* Entry point virtual address */
Elf_Off e_phoff; /* Program header table file offset */
Elf_Off e_shoff; /* Section header table file offset */
Elf_Word e_flags; /* Processor-specific flags */
Elf_Half e_ehsize; /* ELF header size in bytes */
Elf_Half e_phentsize; /* Program header table entry size */
Elf_Half e_phnum; /* Program header table entry count */
Elf_Half e_shentsize; /* Section header table entry size */
Elf_Half e_shnum; /* Section header table entry count */
Elf_Half e_shstrndx; /* Section header string table index */
-
e_type:是一个枚举,代表elf文件类型,常用的就是重定位,可执行,可共享,core四种类型也就是除了0的前四个,我们当前的这个文件是1,就是可重定位文件类型我们可以通过file命令看一下
file test2.o test2.o: ELF 64-bit LSB relocatable, x86-64, version 1, not stripped
-
e_machine:代表了平台的一个枚举值
-
e_verison:文件版本,没啥用可以直接改为ee
-
e_entry:入口点,这个用于递交cpu所有权,但是我们现在还是可重定位文件所以入口点为0因为他还没有真正链接为可执行文件不存在入口点,真正的可执行文件可以通过修改这个地址到空白位置执行恶意代码
-
e_phoff:后面programheadertable在文件中的偏移,我们当前文件中没有programheader,这部分在加载时是十分重要的,我们这里记录的是0目标文件不需要被加载所以也不会存在programheader
-
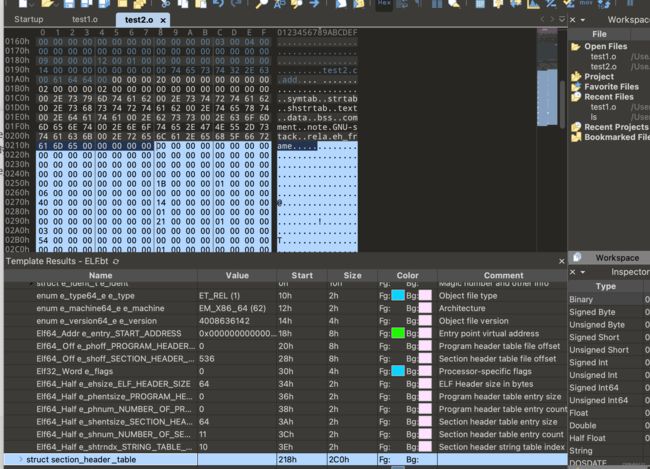
e_shoff:后面sectionheadertable在文件中的偏移,这里存的是0218也就是文件偏移0218的位置可以看到刚好是section header数组的开头
-
e_flags:处理器特定的标志,没啥用一般都是0
-
e_ehsize:Elf_Header的大小(字节)
-
e_phentsize:一个Program Header的大小(字节)。我们这里没有所以也是0
-
e_phnum:Program Header的数量。我们这里没有所以也是0
-
e_shentsize:一个Section Header的大小(字节)。
-
e_shnum:Section Header的数量。可以看出来我们这里有11个sectionheader
-
e_shstrndx:节字符串表的索引,字符串表也很重要这里最好不要改篡位其他位置都是在字符串表里通过索引找到字符,包括后面加载时的符号定位
然后就是sectionheader数组,每一个header都代表了一个section的描述信息,格式如下
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
最后是符号表,这两种数据结构我们在下面用到时候再做讲述
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;
加载过程
加载过程我们通过一个实验来理解,首先找到ls这个可执行程序然后复制一份到我们自己的工作目录
cp /usr/bin/ls /home/caohao/work/myls
下面我们会通过加载这个myls来理解加载过程
首先还是通过010editor来打开这个myls文件看一下他的结构
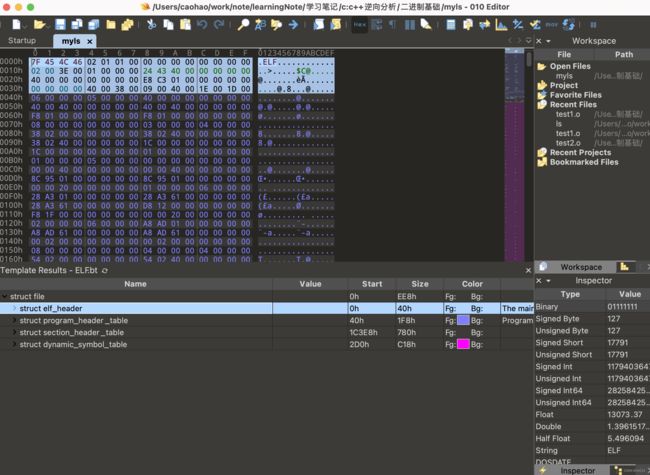
看上去跟之前链接时候使用的可重定位文件之间只是多了个programheadertable,加载过程最重要的一部分就是这个programheadertable,基本上全部的加载信息都通过此处来读取的。而sectionheader等在链接过程中使用的部分在加载时已经是无用的了甚至可以直接改坏。
我们可以做个实验将sectionheader相关的内容全部改成ee看看是不是也可以正常加载执行
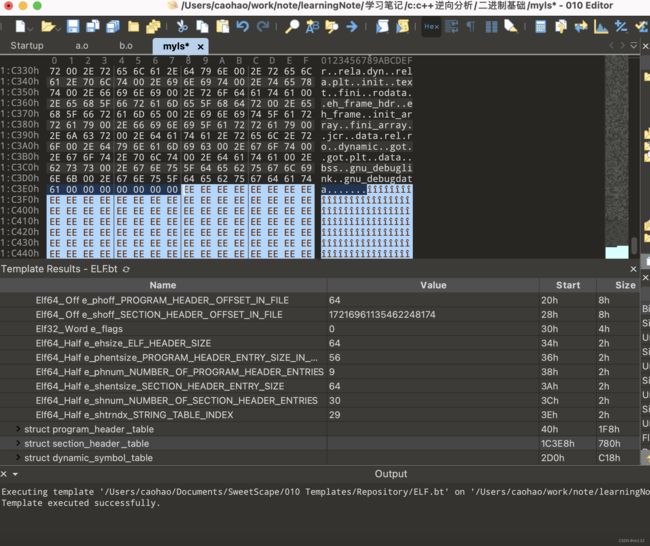
然后我们执行这个,会发现完全正常执行,说明这部分信息对程序的加载执行已经无用了
./myls
a.c a.o a.out b.c b.o icspa-public learnDir myls soft
下面我们看一下programheader都有哪些
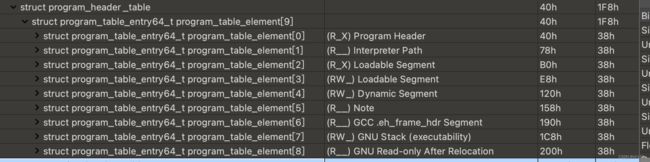
主要需要我们关注的是下面四种段
- ProgramHeader:这个段是冗余段,里面存储的信息大多无用只有代表了文件偏移的offset字段有用,系统可以通过这个offset反向找回elfheader的位置
- InterpreterPath:解释器路径,这个段无需加载它主要的作用是帮助程序找到加载器,加载器负责重定位程序的符号以及导入库表和导入表之类的加载,在pe中承担这个角色的是ntdll,在我当前的Linux版本下这个指向了ld.so
- dynamic Segment:这个段很重要,这个段里其实是存储了一系列其他的table信息,例如字符串表,符号表,导入库表,导入表等等一系列表信息
- loadableSegment:可加载的段,类型为pt_load(1),是真正被映射到内存的段信息的描述
- readonly afterrelocation:这部分段描述信息其实是指向可加载的读写段,在加载后这部分段会被改为只读
加载段
程序的加载过程首先就是通过InterpreterPath找到加载器,然后读取两个loadableSegment header,将可加载段映射到内存。我们可以通过一个实验看一下这两个段是怎么用的
cat c.c
#include
int main()
{
printf("123");
getchar();
return 0;
}
gcc c.c -o c
首先看一下这个c在被加载后他的内存映射信息
cat /proc/55111/maps
00400000-00401000 r-xp 00000000 08:03 51201797 /home/caohao/work/c
00600000-00601000 r--p 00000000 08:03 51201797 /home/caohao/work/c
00601000-00602000 rw-p 00001000 08:03 51201797 /home/caohao/work/c
7fb0edfb0000-7fb0ee174000 r-xp 00000000 08:03 374172 /usr/lib64/libc-2.17.so
7fb0ee174000-7fb0ee373000 ---p 001c4000 08:03 374172 /usr/lib64/libc-2.17.so
7fb0ee373000-7fb0ee377000 r--p 001c3000 08:03 374172 /usr/lib64/libc-2.17.so
7fb0ee377000-7fb0ee379000 rw-p 001c7000 08:03 374172 /usr/lib64/libc-2.17.so
7fb0ee379000-7fb0ee37e000 rw-p 00000000 00:00 0
7fb0ee37e000-7fb0ee3a0000 r-xp 00000000 08:03 374165 /usr/lib64/ld-2.17.so
7fb0ee585000-7fb0ee588000 rw-p 00000000 00:00 0
7fb0ee59c000-7fb0ee59f000 rw-p 00000000 00:00 0
7fb0ee59f000-7fb0ee5a0000 r--p 00021000 08:03 374165 /usr/lib64/ld-2.17.so
7fb0ee5a0000-7fb0ee5a1000 rw-p 00022000 08:03 374165 /usr/lib64/ld-2.17.so
7fb0ee5a1000-7fb0ee5a2000 rw-p 00000000 00:00 0
7ffec0ca3000-7ffec0cc4000 rw-p 00000000 00:00 0 [stack]
7ffec0d2a000-7ffec0d2c000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
可以看到
00400000-00401000 r-xp 00000000 08:03 51201797 /home/caohao/work/c
00600000-00601000 r–p 00000000 08:03 51201797 /home/caohao/work/c
00601000-00602000 rw-p 00001000 08:03 51201797 /home/caohao/work/c
这三块内存区域里的东西是从c这个可执行文件里映射过来的,在看一下我们elf文件里的可加载段是怎么描述的
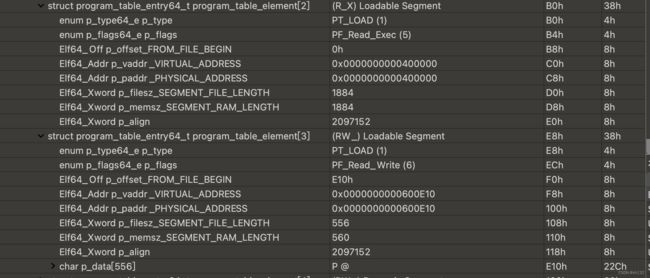
可以看到第一个代码段也就算可读可执行权限的segmentheader的virtualaddr的偏移是0x400000正好对应我们进程maps里记录的第一个可读可执行段,在header里记录他所需要的内存长度为1884在文件内也占据1884字节,但是可以看到其实他在程序内存中申请的内存大小并不是1884而是4k正好一个页,这是因为系统内存分配机制的导致的,在不满一个页的时候会用0填充到一个页大小
在看一下第二个可读可写的segmentheader描述的addr偏移为0x600e10,那么系统给他分配内存时候不会从600e10开始而是以页对齐到600000开始刚好对应内存中只读那段的开始,header里描述这个段需要在内存中申请560字节转换16进制就是230,600e10+230=601040那么就意味着他要页对齐到602000的位置跟maps里记录的刚好一样
有人会有疑问为什么00600000-00601000这段变成了只读,我们看一下之前说的那个readonly afterrelocation段header的信息
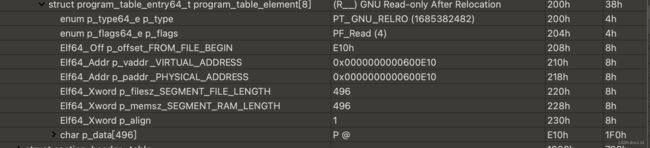
可以发现这个段的addr刚好是600e10,刚好是可读可写段的addr的开始位置,其实这个段header就是一个记录,他负责记录从哪里开始是只读数据以及到哪里结束,所有的需要加载到内存的数据位置都是由可加载段记录的,而这个readonly afterrelocation段就好像为其他段打了补丁,在加载完之后就通过这个补丁在进行一次修复修改他的段type
在加载文件到内存的映射之后,就不在需要这个elf文件了剩下的步骤就是加载dynamic Segment这个段了,这个段加载完这个程序基本上就可以跑起来了
从将文件到内存的映射完成开始就不会再使用到文件了,只会使用addr也就是通过地址空间里的虚拟地址来到可读或者可读写段中去找从文件映射进来的数据

从图中可以看出来是在虚拟内存的600e28位置去找这个段,而我们刚刚看的maps信息中600000-601000之间刚好是从文件映射来之后通过补丁变成只读内存的位置

上面图里就是这个段的内容,他其实也是一个数组是一系列的其他段描述组成的数组,每16个字节是一个段描述的结构体,这个数组的最后一个对象的type为0,当遇到type为0的地方则代表dynamic段已经结束了
这八个字节的前8个字节是一个类型的枚举值,后8个字节则是代表了地址或者是字符表的下标(64位环境下)
字符串表
字符串表的type值为5,我们在dynamic段里找到type为5的结构体如下

他的地址为400330,正好在我们从文件映射到内存的地址空间里,也就是文件里的330的偏移位置
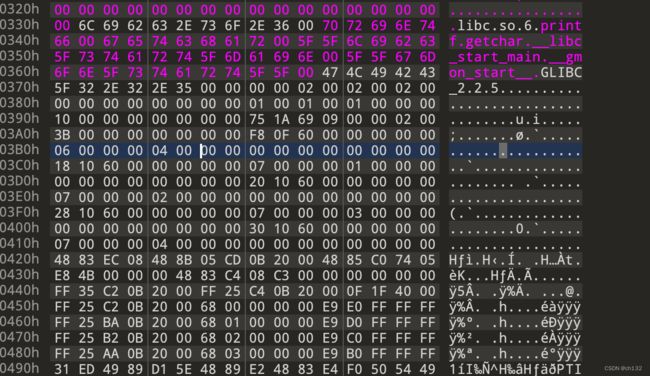
字符串表的开始为00,也代表了空字符串,字符串表的并不会记录多大到哪里结束之类的,只是从1偏移开始,0偏移默认为空字符串0,使用字符串表都是通过给予一个字符串表的下标然后到这个330的位置开始往后找找到下标所代表的字符串即可
导入库表
导入库表代表了一个外部库,他在在dynamic段里type为1翻译过来对应needed这个枚举符号
这里要先讲一下Elf64_Dyn这个结构体,dynamic段里放的就是Elf64_Dyn的数组,在elf.h里可以看到这些结构体的描述
typedef struct {
Elf64_Xword d_tag;
union {
Elf64_Xword d_val;
Elf64_Addr d_ptr;
} d_un;
} Elf64_Dyn;
其中d_tag决定这个是什么类别信息,以及该如何解析d_un内部变量。
其中有一个约定如果d_tag是偶数那么你使用d_ptr。奇数不包证一定使用d_val,但大多数情况下是。
d_ptr: 表示一个虚拟地址
d_val:需要根据d_tag才能决定表示的意思
d_tag 有很多类别下面举我们遇到的这两个
DT_NEEDED(1):所需要的动态库,d_val指向字符表的下标(字符表由DT_STRTAB确定)
DT_STRTAB(5):字符串表,d_ptr是字符串表地址
我们在内存里找到一个type为needed的结构体看一下

可以看出来指向的strtab下标为1,我们回上面看一下strtab那个图,发现下标为1的字符串是libc.so.6,一个type为1的结构就代表了一个导入库
符号表
首先我们要知道符号表是干什么的,符号的意义就是能通过一个符号找到一个地址,而符号表就是在符号和地址之间的一个桥梁,他保存了符号和地址之间的对应关系,一个符号在strtab里的下标对应一个地址然后存在符号表里,这样就可以通过符号找到地址了
符号表的type为6,他的后8位为虚拟地址ptr
![]()
可以看到他指向4002b8也就是文件偏移2b8的位置,跟字符串表一样第一项是全0的不使用的

符号表是如下结构体的一个数组(32位的在elf.h里叫elf32_sym)
typedef struct elf64_sym {
Elf64_Word st_name; /* Symbol name, index in string tbl */2字节
unsigned char st_info; /* Type and binding attributes */1字节
unsigned char st_other; /* No defined meaning, 0 */1字节
Elf64_Half st_shndx; /* Associated section index */4字节
Elf64_Addr st_value; /* Value of the symbol */8字节
Elf64_Xword st_size; /* Associated symbol size */8字节
} Elf64_Sym;
我们看一下第一个符号结构体,他的st_name为0b我们将330+0b就是33b也就是对应里printf这个字符串,然后他的addr字段为0
我们再来看一个,第二个的name为1a,330+1a=34a,在字符串表里对应着__libc_start_main这个字符,addr依旧是0
两个addr都是0是因为我们是在二进制文件里看的,只有在被加载到内存里之后才会根据系统的机制去决定什么时候导入这个符号的实现,这个addr才会被填充值,其次因为我们的代码里并没有导出符号所以没有存在addr具体值的符号映射
导入表
导入表的type为23,也就是16进制的17
![]()
导入表是有尺寸的也存储在dynamic段里type为2,后八个字节为导入表的尺寸
![]()
通过上面两个数据就可以知道导入表起始地址是4003c0,总共有96/24=4项
typedef struct
{
Elf64_Addr r_offset; /* Address */8字节
Elf64_Xword r_info; /* Relocation type and symbol index */8字节
Elf64_Sxword r_addend; /* Addend */8字节
} Elf64_Rela;
导入表就是有上述结构体构成
我们来看一下二进制的导入表是什么样的

看一下第一项:addr是601018,意思就是在601018的位置存放的字节替换为符号实现的真正地址
type是7,symbol index是1在符号表里的偏移是1那么就代表这个导入符号是printf然后要替换到601018位置的地址是符号表第一个的addr字段,如果还没有加载进来这个函数就会遍历所有的导入库表然后进去找对应的符号之后加载进来
重定位表
重定位表的type为11,重定位表size的type为12
重定位表的解析方式跟导入表基本一致,只不过这边重定位表基本可以说是包含两类内容
- 存的是其他库里的全局变量以及函数指针之类的重定位,这部分可以看做是导入表的扩展部分,甚至在系统源码里这个部分调的解析函数和导入表解析时候调的是一样的
- 编译时在代码中已经写死的一些地址的偏移,在未被加载到内存时是不知道他的地址的所以在加载后要对这些位置进行修改使他们加上一个基址,这也是重定位表最原始的目的
导出表(哈希表)
这个段主要是在库文件里才会存在,这个东西的解析过程在新老版本下的区别也是蛮大的甚至type都变了,在老版本下好像是4,新版本下就不太清楚了,其实这是一个比较复杂的数据结构,他的设计想法是能够提供一种能快速查找的能力,在这里就不详细展开了