ChatGPT 学习与使用总结
ChatGPT 学习与使用总结
最近ChatGPT大火,2023有可能就是AGI元年了。近两个月使用下来,ChatGPT给我最深刻的感觉就是它所具备的理解和思维能力,第一次体验时真的是非常震撼,完全是之前各种『人工智障』智能助理所不能比拟的,第一次感觉这才是真正的『人工智能』,项目组里小伙伴也各个都玩的乐此不疲,连百度的弱智吧也跟着大火了一把,各种ChatGPT相关的自媒体文章视频纷纷出来,都要蹭上这波热度。然后各种AI创业公司也纷纷诞生,各大IT公司的AI竞争进入白热化阶段,颇有当年移动互联网大潮时的军备竞赛百花齐放的感觉。
紧随时代的热点,下面总结一下自己这段时间对ChatGPT的学习与使用。
ChatGPT是什么
ChatGPT 是 OpenAI 发布的基于 GPT(Generative Pre-training Transformer)模型的生成式AI聊天机器人,意在实现通用人工智能。
B站的这个科普视频很不错,推荐看看:
大语言模型为什么这么厉害?涌现?思维链?万字科普GPT-4
GPT 模型
GPT(Generative Pre-training Transformer) 是一种类型的大型语言模型(LLM),也是一个优秀的生成人工智能的框架,由OpenAI在2018年提出,基于Transformer架构。发展历程:
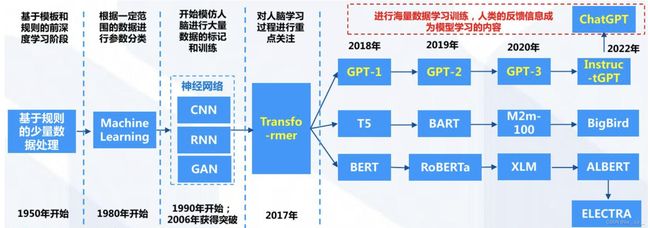
GPT 采用的半监督方法使得大规模生成系统成为可能,并且是首个使用Transformer模型实现这一方法。该方法包括两个阶段:
- 无监督的生成“预训练”阶段,使用语言建模目标来设置初始参数;
- 有监督的判别“微调”阶段,将这些参数适应于目标任务;
Transformer 架构由Google 2017年提出,通过在大规模无标签文本数据集上进行预训练,能够生成类似人类输出的文本。与之前NLP常用的循环神经网络(RNN)不同,具有下面的优势:
- Transformer 解决了RNN在处理长序列时产生的梯度消失和计算效率低下的问题。在RNN中,梯度需要通过时间步反向传播,随着序列长度的增加,梯度在传播过程中容易产生消失或爆炸的问题。这会导致RNN难以处理长序列,并且难以捕捉序列中的长距离依赖关系。而Transformer模型通过引入自注意力机制,可以在模型中直接捕捉输入序列中的长距离依赖关系,避免了需要沿时间步反向传播的问题,更有效地捕捉了输入序列的信息。
- Transformer 可以同时处理整个输入,而不是逐个处理。它的注意力机制为输入序列的任何位置提供上下文信息。相比于RNN,这种并行化处理方式减少了训练时间,使得在更大的数据集上进行训练成为可能;
基于RLHF(Reinforcement Learning from Human Feedback)从人类反馈中进行强化学习方法进行训练的InstructGPT,使其能够遵循人类指示并生成相应的输出。在泛化到新的指令时也显示出良好的性能。
还有下面一些概念要简单了解一下,然后才好理解什么是ChatGPT说的Token:
| 概念 | 介绍 |
|---|---|
| Embedding | Embedding, 是一种将离散变量(如词、图片等)转化为连续向量表示的技术。具体来说,Embedding通过将离散变量映射到一个低维稠密向量空间中,能够意义化处理数据,提高数据的表达能力,使得机器学习等领域中的任务(如分类、聚类、推荐等)更加精准和高效。 |
| Few-shot | Few-shot, 是指在模型只经过少量特定任务的训练,就能够对新任务进行预测或生成结果的能力。这种能力通常是通过在训练阶段使用少量的训练样本和元学习技术来实现的。 |
| Zero-shot | Zero-shot, 是指在模型未经过特定任务的训练,却能够对该任务进行预测或生成结果的能力。这种能力通常是通过在训练阶段暴露模型于各种语言和任务来实现的。例如直接向ChatGPT提问,不给示例。 |
ChatGPT使用一种基于字节对编码(Byte Pair Encoding,BPE)的 tokenization method,可以有效处理罕见单词和超出词汇表的tokens。这种 tokenization 过程将输入文本切分成文本片段,每个片段被表示为一个token,token是文本的数值表示形式,用于在模型中进行后续处理。ChatGPT将每个单词都会转换为相应的token,然后转换成 embedding representations,embedding 是表示文本语义和上下文信息的向量。
LLM 大语言模型
LLM(Large Language Model)是NLP领域一种重要模型,于2018年左右出现,并在各种任务上表现出色,这使得自然语言处理研究的重点从以前专门针对特定任务训练专用模型的范式转变过来到通用模型上。LLM能够在已知文本的多个层面上找出规律,如识别单个词语在段落中的上下文联系,以及辨识句子在文本框架中如何承上启下等。LLM具有以下特点:
- LLM 具有大量的参数(通常是数十亿个或更多的权重),通过使用自监督学习或半监督学习在大量无标签文本上进行训练。
- LLM 通常在预训练数据集上进行预训练,常用的文本数据集包括Common Crawl、The Pile、MassiveText、Wikipedia和GitHub等。这些数据集的规模可达到10万亿个单词。
- LLM 通常使用Transformer架构,这是自2018年以来成为顺序数据的标准深度学习技术(之前,循环架构如LSTM最为常见)。
- LLM 的输出是其词汇表上的概率分布,常用的实现方式是使用softmax函数将输出向量转换为概率向量。
- LLM 的训练通常通过生成式预训练来进行,即给定文本标记的训练数据集,模型预测数据集中的标记。通常使用平均负对数似然损失作为特定损失函数进行训练。
- LLM 的训练成本高昂,通常需要巨大的计算资源。对于基于Transformer的LLM,在一个标记上训练每个参数需要6次浮点运算。而在推断阶段,每个参数在一个标记上的推断仅需1到2次浮点运算。
涌现 Emergent
ChatGPT的文章介绍中,很多能力是随着模型规模的扩大而涌现出来的,业界也有很多研究涌现的文章,比如:Emergent Abilities of Large Language Models。微软介绍GP4的论文也提到了这些涌向的能力,比如:
In-context learning, 上下文学习学习能力,一种说法是OpenAI 训练的 GPT-3时,比 GPT-2 整整用了 15倍的语料,同时模型参数量扩展了 100 多倍,使其涌现了In-context learning 能力,可以说有很大程度来自于其庞大的参数量和训练数据,但是具体能力来源仍然难以溯源。Chain-of-Thought, 思维链能力,没有确定性的结论说明 CoT 特性来自于具体哪些迭代优化, 没有确定性的结论说明 COT 特性来自于具体哪些迭代优化:有些观点说是通过引入强化学习;有些观点说是通过引入了指令微调的训练方式;有些观点说是通过引入庞大的代码预训练语料;推测的方式则是根据不同时间节点上的模型版本能力差进行排除法。
深度学习从一开始就有不可解释性的特点,再加上ChatGPT很多能力说是涌现出来的,好奇宝宝就更多了,知乎还看到了一个这样的问题:
大语言模型中的涌现现象是不是伪科学?
不光是涌现,关于复杂系统的很多研究都经常被诟病是伪科学。之所以被说伪科学是因为它无法用科学里流行的还原论来解释,还原论是说“如果你理解了整体的各个部分,以及把这些部分‘整合’起来的机制,你就能够理解这个整体”。
只要数据量足够且真实,且模型没有硬错误的前提下,不断的训练说不定真的能够产生一些意想不到的效果。
总之,模型增大,是有可能产生意想不到的能力,但是现在还不可解释。
使用初体验
日常开发使用
作为一名程序员,用ChatGPT查资料和写一些短程序片段是我近阶段最常用到的场景,只要你把问题描述的足够清晰,尤其要用结构化的语言来描述你的需求或者问题效果会更好,那么ChatGPT基本会给你很满意的答案。说几个场景:
- 开源项目中,很多关键缩写的函数或者变量名字,查缩写的全称的含义。
- 帮助理解代码内容,直接贴上去代码,就可以给出解释。
- 帮助生成代码片段,各种Utils接口,正则表达式等等。
- 查询错误的信息,直接全部贴进去报错,就可以给出可用的解决方案。
- 学习新语言新框架入门,提问+demo+练习,体验很棒。
- 查一个领域的各种术语概念,反复提问,加配合Google与相关的AI总结插件。
文案邮件生成
还有就是一些文案的生成,比如根据主题来生成一些场景的文案,通过不断的反馈来调整具体的内容,最后再自己润色,效率比自己从头写高出很多。
使用GPT4开发游戏AI
B站UP主使用GPT4开发的AI: 格斗之王!AI写出来的AI竟然这么强!
这个真的是太强了,后面如果想学一下机器学习入门,网上看资料+练习+ChatGPT指导,效率直接起飞啊。当然,作为意在实现AGI通用人工智能,在很多领域都是如此,真是给每个人配一个超级顾问,答疑解惑,还能辅助搬砖。
五分钟开发一个留言板网站
这个是我自己突发奇想,自己现编的一个题目。使用ChatGPT 3.5, 就能5min完成这个小demo,自己一行代码不修改, 全部用AI生成的。
过程全纪录,7个Prompt就完成了这个project:
1. 编写一个留言板网站,使用python flask框架,代码尽量短,不用数据库,使用一个文本文件做后台持久化数据存储,不需要用户注册
#ChatGPT: AI 给出了一个 app.py 的源代码,里面引用了一个 index.html 文件
2. index.html 内容呢
#ChatGPT: AI 给出了一个 index.html 的源代码
3. 如何部署,工程的文件结构是什么
#ChatGPT: AI 给出了工程文件结构
4. 如何启动?
#ChatGPT: AI 给出网站启动命令
5. 我在本机访问,网址是多少呢?
#ChatGPT: AI 给出了本机访问的URL网址
6. 上面的app.py运行报错了 // 注意:我空了一行,然后用 > 这种 Markdown 引用格式写了报错内容
> return redirect('/')
> NameError: name 'redirect' is not defined
#ChatGPT: 给出了bug原因
7. 修改app.py的这个bug
#ChatGPT: 给出了bug修复方法
效果显著,我这个还是使用的免费版的ChatGPT3.5,如果是GPT4,估计效果会更好,一把就是正确的了。不过这也隐藏了一个点,你必须有一定的经验,才能把你要做的需求描述清楚,GPT4让有厉害的程序员效率翻好几倍,尤其是在平时的一些小的常见的场景上的编程。
插件与应用推荐
自从ChatGPT开放了API,各种应用和浏览器插件层出不穷,这里就只推荐两个我用的最多的:
- chatgpt-glarity-summarize: Chrome浏览器插件,使用ChatGPT的能力来生成网页内容摘要。这个使用下来很方便,尤其是把当前搜索结果页面的多个搜索结果进行分析汇总总结。本文的很多内容就来自这个插件的总结,然后自己修改润色。
- chatbox: 非常好用ChatGPT桌面客户端,无限制存储对话历史记录,更前大的编辑功能,以及一些有用的内置prompt模板,使用体验很好。上面的那个小网站project我就是在这个app里面实现的。
还有更多的,大家可以慢慢探索。
相关学习资料搜集
ChatGPT爆火后,网上相关资料文章也是铺天盖地,有时候资料太多反而不好筛选了。下面是我搜集的一些比较好的资料:
- OpenAI官网博客:https://openai.com/blog/chatgpt
- ChatGPT中文指南: https://github.com/yzfly/awesome-chatgpt-zh
- 吴恩达Prompt工程课程:https://github.com/datawhalechina/prompt-engineering-for-developers
- Prompt教程:https://learningprompt.wiki/
- Midjourney官网文档: https://docs.midjourney.com
- ChatGPT的前世今生: https://lipiji.com/slides/ChatGPT_ppf.pdf
- ChatGPT业界资料汇总: https://github.com/shawshany/ChatGPT_Project
- 微软GPT4论文: Sparks of Artificial General Intelligence: Early experiments with GPT-4
- LLM论文集合: Understanding Large Language Models – A Transformative Reading List
总结
也许ChatGPT就是AI时代的iPhone4时刻,技术的革新不知不觉就会带来社会的变革,保持一颗好奇心,感受科技带来的美好!