Linux进程编程、fork函数范例详解 ( 5 ) -【Linux通信架构系列 】
系列文章目录
C++技能系列
Linux通信架构系列
C++高性能优化编程系列
深入理解软件架构设计系列
高级C++并发线程编程
期待你的关注哦!!!

现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。
Now everything is for the future of dream weaving wings, let the dream fly in reality.
Linux进程编程、fork函数范例详解
- 系列文章目录
- 一、认识fork函数及简单范例
- 二、僵尸进程的产生、解决,SIGCHLD
- 三、进程的内存空间及进程的产生
- 四、判断父进程进程和子进程的执行分支
- 五、一个和fork执行有关的逻辑判断
- 六、fork失败的可能原因总结
进程的概念:
一个可执行程序执行一次就是一个进程,再执行一次就有是一个进程(多个进程共享同一个可执行文件),换句话说,进程一般定义为程序为程序执行的一个实例。
一、认识fork函数及简单范例
在一个进程中可以使用fork创建一个子进程,当该子进程创建时, 它从fork函数的下一条语句(或者说fork的返回处)开始执行与父进程相同的代码。 换句话说, fork函数产生一个和当前进程完全一样的新进程,并和当前进程一样从fork函数调用中返回。
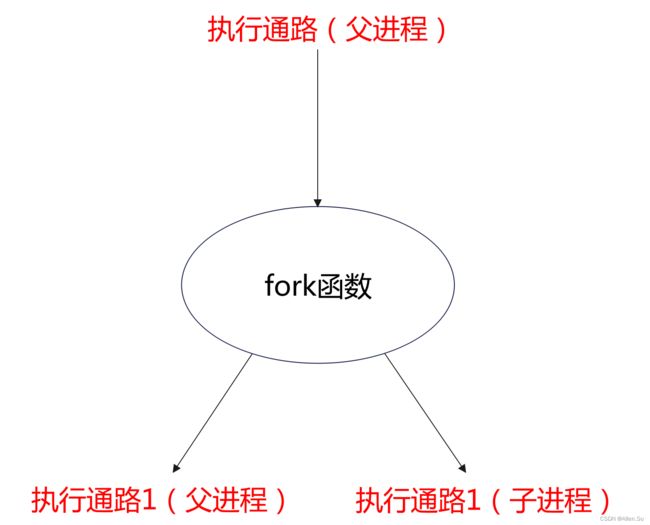
试想,原来只有1个父进程在运行,是1条执行通路,调用fork之后,就变成了2条执行通路(父进程一条,子进程1条)。如图1.1所示:
看如下范例:
#include 编译、链接并运行,结果如下:
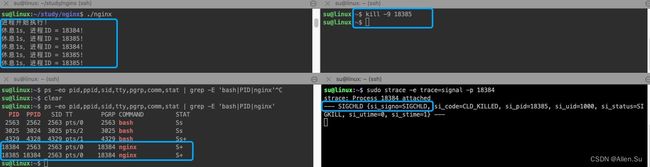

(1)可以注意到,进程ID为1183的父进程ID是1182,说明1182这个进程调用fork函数创建1183进程。另外注意这2个进程的状态都是S+。S是休眠因为进程大部分时间执行的是sleep,所以休眠是正常的;+表示位于前台进程组。
(2)但这里注意一点,调用fork函数创建出一个子进程后,后续的代码是父进程先执行还是子进程先执行并不确定,不代表父进程一定快,因为存在进程的时间片调度问题(这与内核调度算法有关)。
(3)从打印结果中可以看出,父进程和子进程都能收到这个信号,说明信号捕捉这段代码,是子进程和父进程的公共代码(对父进程和子进程都有效,或者说这段代码既在父进程中,也在子进程中 - 虽然子进程是后面fork函数创建出来的,但在子进程创建出来之前父进程执行的所有代码都相当于子进程执行过了)。
(4)也可以注意到,我们通过kill -9 命令(-9代表SIGKILL信号,该信号不能被拦截,不能被捕获)把子进程杀掉,父进程收到了SIGCHLD信号。
(5)从图1.3中我们可以看到被杀掉的1183子进程仍旧存在于ps命令的列表中,但这COMMAND列显示defunct(失效的意思),而STAT列显示Z+(Z状态表示僵尸进程)。总之,无论是Z状态还是defunct字样,都是僵尸进程的典型标记。
二、僵尸进程的产生、解决,SIGCHLD
⚠️(1)僵尸进程是怎么产生的能呢?
在Linux操作系统中,如果一个子进程终止了,但父进程还活着,当该父进程没有调用(wait / waitpid)函数来进行一些额外处置(处置子进程终止这件事),那么这个子进程会变成一个僵尸进程。
这种僵尸进程已经被终止了,不工作了,但是依旧没有被内核丢弃,因为内核认为父进程可能还需要该子进程的一些信息。
僵尸进程是占用资源的,至少会占用进程ID(PID)。整个操作系统中进程号是有限的,所以,作为开发者不应该允许僵尸进程的存在。
⚠️(2)那么怎么能让僵尸进程消失呢?
重启计算机?手动把这个僵尸进程的父进程杀掉?这两个都不是好办法。
我们应该从代码的角度来避免僵尸进程的产生。
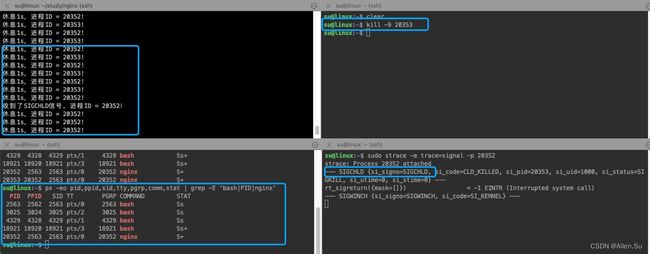
当子进程被杀掉的时候,父进程收到了一个SIGCHLD信号。所以,对于源码中fork的行为(会创建子进程)的进程,我们应该拦截并处理SIGCHLD信号。
看如下范例:
#include 编译、链接并运行,结果如下:
三、进程的内存空间及进程的产生
fork 产生新进程的速度非常快, 产生的新进程并不复制原来进程的内存空间,而是和原来进程(父进程)一起共享一个内存空间。 这个内存空间的特性是"写时复制",也就是说,原来的进程和fork出来的子进程可以同时自由读取内存,但如果子进程(或者父进程)对内存进行修改,这个内存就会复制一份给该进程单独使用,以免影响该内存空间的其他进程的使用。
看如下范例:
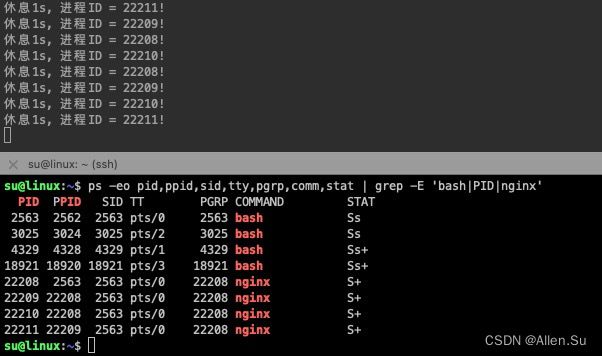
#include ⚠️上面的代码执行后会产生几个进程?
fork的能力简单说就是一分二(一条路线分成两条路线 / 一个进程变成了2个进程)。
代码中,第一个fork一分二,2条线同时往下走,2条线都经历了第2个fork,每个fork又分出2个,所以二分四(最终产生了4个进程)
接下来我们看下执行结果:
四、判断父进程进程和子进程的执行分支
一执行fork,1条路线变成了2条路线,所以fork函数的实际返回了2次(父进程返回了1次;子进程中也返回了1次)。
fork函数在父进程中返回的值和在子进程中返回的值是不同的,据此可以编写代码分别识别出当前是父进程还是子进程,从而让父子进程执行不同的代码分支。
通过观察下面的代码范例,可以发现,程序正是 通过判断fork的返回值来决定父进程执行哪些代码、子进程执行哪些代码。
#include 运行结果如下:

观察上面的结果,重点关注g_mygbltest全局变量的值,可以看到,父进程和子进程的该全局变量的值是不同的,每个进程都是单独计数的。
通过上面的范例,可以得出一个结论:
fork对于子进程,返回值0;对于父进程,返回值是新建立的子进程的ID。
父进程和子进程的全局量g_mygbltest值也不同,每个进程都有不同的值,因为这2个进程都有写的动作(改写全局变量g_mygbltest的值,也就是改写内存),内核会给每个进程单独分配一块内存供其单独使用,所以每个进程的g_mygbltest值是互不干扰的。
五、一个和fork执行有关的逻辑判断
#include运行结果如下:
六、fork失败的可能原因总结
(1)系统中进程太多:
-
肯定出了问题,如僵尸进程太多。整个系统中,使用ps命令列出进程时看到的进程ID(PID)是有限的,创建子进程ID值比父进程ID值大于1,进程ID是可以复用的,例如某个进程结束(终止)之后,过一段时间,操作系统又会把这个进程的ID分配给其他的新创建的进程使用(循环使用)。
-
默认情况下,最大的进程ID值一般都是32767,如果0~32767这些数字全部都被占用,fork就会失败,当然,这是一种比较极端的情况。
(2)创建的进程数超过了当前用户允许创建的最大进程数。
- 每个用户会有一个允许开启的进程总数。
printf("每个用户允许创建的最大进程数 = %ld\n", sysconf(_SC_CHILD_MAX));