机器学习基石的泛化理论及VC维部分整理(第五讲)
第五讲 Training versus Testing
一、问题的提出
\(P_{\mathcal{D}}\left [ BAD \mathcal{D} \right ] \leq 2M \cdot exp(-2\epsilon^2N)\)
\(\Leftrightarrow P_{\mathfrak{D}}\left [ \left | E_{out} - E_{in} \right | > \epsilon \right ] \leq 2M \cdot exp(-2\epsilon^2N) \)
(1) 当\(M < \infty \) 时,\(N \) 足够大,则说明犯错误的概率是比较小的,可推导出 \(E_{in} \approx E_{out}\),如果\(E_{in}\)接近于 0 时,则 \(E_{out}\)接近于零。
(2) 上一节林老师也说了,当\(M = \infty \) 时,就没法学习了,因为上界比较大,犯错误的概率比较大,得出无法进一步的学习。学出来的错误概率比较大。
其中 \(M\) 是 Hypothesis Set 中 Hypothesis的个数
但是上一节的时候,算出的概率是 or 的关系,为各个犯错的概率之和, 那么这里面就应该有一部分可能存在着重复了,上界就显得过大了。当\(M = \infty \) 时,是无法进行有效学习的;实际上,由于不同的hypothesis下发生坏事情是有很多重叠的,其实我们可以得到比\(M\) 小很多的上界。
我们可以将这些具有很多重叠的hypothesis进行分组,根据组数来考虑hypothesis set的大小。
二、以二值分类为例来解决hypothesis set的个数上界问题。
从有限个输入数据的角度来看 hypothesis的种类,
(1)最简单的,一个数据,会有两种hypothesis, \(h_{1}(x) = +1 或 h_{2}(x) = -1 \)
(2)两个数据,会有四种hypothesis, 具体如下:
\(h_{1}(x_{1}) = +1, h_{1}(x_{2}) = +1\)
\(h_{2}(x_{1}) = +1, h_{2}(x_{2}) = -1\)
\(h_{3}(x_{1}) = -1, h_{3}(x_{2}) = +1\)
\(h_{4}(x_{1}) = -1, h_{4}(x_{2}) = -1\)
以此类推,对于\(N\)个点来说,最多有\(2^N\)个假设;这里说的是最多,也是最理想的,事实上还会小,那么在什么情况下会小呢? 比如有四个点时,对角线相同的四个点就是不可行的,如下图
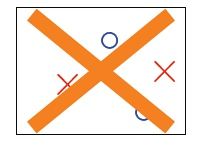
就是说找不到一条直线把上面四个点分开,那么上述四个点到底有多少个呢?除了上图,还有圈圈和叉叉交换的情况,应该是\(2^4 - 2 = 14 \) 种
同理可知,当\(N\) 比较大的时候,有效 hypothesis的数量应该是远远小于 \(2^N\)的,
在这种情况下,林老师给了一个定义,叫做dichotomy,字面意思是二分法,其实就是 Effective Hypothesis
看到论坛里也有同学问道什么叫 from the eyes of data, 其实就是从数据的角度去看,我们有多少个有效的Hypothesis,那么这里有效的Hypothesis个数会随着数据的个数变化而变化,从上面的例子可以看出来,这个个数将随着数据的个数增加而增加,在林老师的视频里,又给出了一个函数,叫做 Growth Function.
三、Growth Function
\(Growth Function = m_{H}(N)\),具体的函数就记为\(m_{H}(N)\)了。
林老师举例说明了几类问题的Growth Function:
(1)\(\mathcal{X}=\mathcal{R} \) (一维实属空间), \( positive ray, h(x) = sign(x-a) \),就是说当\(x > a \)时(\(a\) 是参数),\(h(x) = +1, otherwise h(x) = -1\)
它的Growth Function为:\( m_{\mathcal{H}}(N) = N + 1\),林老师在视频里也画了一条射线,把\(N\)个点标好,那么\(a\)的取值范围可有\(N + 1\)个,两个点之间的为\( N - 1\)个, 全是圈圈的一个,全是叉叉的还有一个,所以是\(N - 1 + 2 = N + 1\)个。
视频上还有个Fun time, 说如果是positive and negative rays,怎么办呢?也就是说可能有两种情况,原来 \(x > a \) 时,\(h(x) = +1, otherwise h(x) = -1\),如果还有negative的话,就还有一种\(x > a \) 时,\(h(x) = -1, otherwise h(x) = +1\),那么情况就有些变化了,如果\(a\)在两点之间的话会有\( 2(N - 1)\)个,而两端的还是只有一个分法,总共加起来就是会有\(2N\)个。
(2)\(\mathcal{X}=\mathcal{R} \) ,\( x \in [a,b), h(x) = +1, otherwise -1\),这有两个参数\(a,b\)。 则它的Growth Function为什么?
可以分析一下,假设在一条射线上标\(N\)个点,那么总共有\(N + 1\)个区间,这个问题可分为两类,一类是\(a, b \) 取不同区间的,那么就是\( \binom{N+1}{2}\) 种取法,还有一类是\(a, b \)在一个区间内,那么这个就只有一种取法,即所有点都为叉叉。 故Growth Function为 \( \binom{N+1}{2} + 1 = \frac{1}{2}N^2 + \frac{1}{2}N +1\)
(3)\(\mathcal{X}=\mathcal{R}^2 \) ,在二维实数空间里,凸集里,\(h(x)\)为一个任意的凸多边形,在多边形内部的为1,外部的为 -1,Growth Function为 \(2^N\)
(4)Perceptron的Growth Function不知道,但是我们知道最大可shatter的点个数,为3,4个时就没法shatter了,因为\(2^4 = 16, \)而在四个点时,有两种情况不能发生,所以四个点不能被shattered,
根据Growth Function可以得到另外一个重要概念,Break Point, 就是可被Shattered的最大点个数,也就是说当 \(m_{\mathcal{H}}(k) < 2^k\),这个\(k\)之后的就是Break Point,顾名思义,Break Point在这个点就Break了,什么Break呢?是全部shattered的情况被中断了。
后面讲到,这个就是VC Bound。
对于之前的几个例子我们可知,(1)的Break Point是2,(2)的Break Point是3,(3)的Break Point没有,(4)的Break Point是4。