【STL迭代器源码解读】
OOP和GP
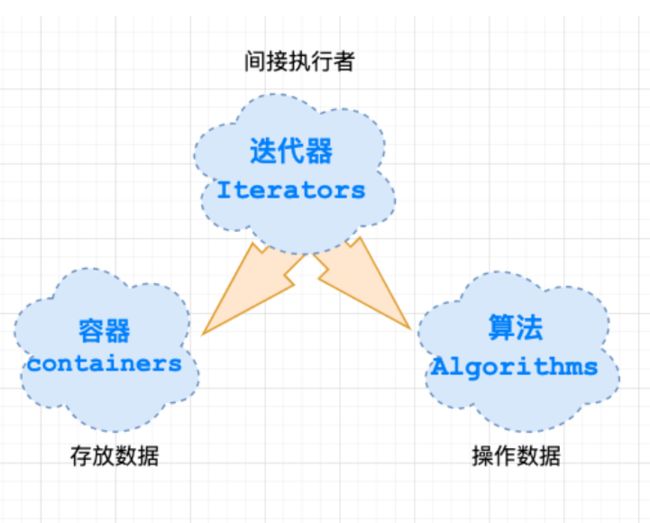
- 在STL编程中,容器和算法是独立设计的,容器里面存的是数据,而算法则是提供了对数据的操作,在算法操作数据的过程中,要用到迭代器,迭代器可以看做是容器和算法中间的桥梁,使用迭代器,可以操作容器,使得容器可以使用某种算法。
- iterator的描述:一种能够顺序访问容器中每个元素的方法,使用该方法不能暴露容器内部的表达方式。而类型萃取技术就是为了要解决和iterator有关的问题的。
OOP(面向对象编程)和GP(泛型编程)
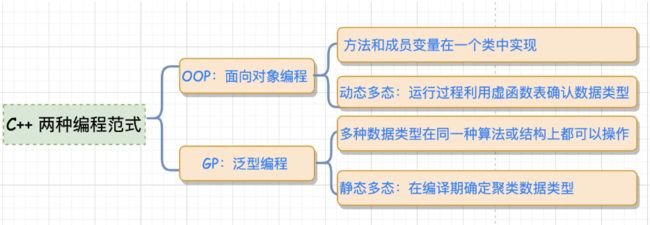
- OOP:将methods和datas关联到一起(通俗点就是方法和成员变量放到一个类中实现),通过继承的方式,
利用虚函数表(virtual)来实现运行时类型的判定,也叫"动态多态",由于运行过程中需根据类型去检索虚函数
表,因此效率相对较低。- GP:泛型编程,也被称为"静态多态",多种数据类型在同一种算法或者结构上皆可操作,其效率与针对某特定数
据类型而设计的算法或者结构相同,具体数据类型在编译期确定,编译器承担更多,代码执行效率高。在STL中
利用GP将methods和datas实现了分而治之
而C++STL库的整个实现采用的就是GP(GenericProgramming),而不是OOP(ObjectOrientedProgramming)。而GOF设计模式采用的就是继承关系实现的,因此,相对来讲,C++STL的实现效率会相对较高,而且也更有利于维护。
模板
- 在c++中模板分为三种:类模板、函数模板和成员模板
类模板
template <typename T>
class MyClass {
public:
MyClass(T r = 0, T i = 0):re(r), im(i){}
MyClass& operator += (const MyClass&);
T real()const {return re;}
T imag()const {return im;}
private:
T re, im;
};
MyClass<doouble>c2 (2.5, 1.5);
MyClass<int>c2(2, 6);
函数模板
template<class T>
inile
const T& min(const T& a, const T& b)
{
return b < a ? b : a
}
成员模板
class MyArray {
public:
template <typename T>
void set(int index, T value) {
data[index] = value;
}
template <typename T>
T get(int index) {
return data[index];
}
private:
int size;
T* data;
};
int main() {
MyArray intArray(10);
MyArray doubleArray(5);
intArray.set(0, 1);
doubleArray.set(0, 3.14);
int intValue = intArray.get<int>(0);
double doubleValue = doubleArray.get<double>(0);
}
泛化、特化(全特化)、偏特化
泛化
- 泛化是最基本的模板编程技术,它通过定义一个通用的模板来适用于不同的数据类型。
- 泛化模板的定义通常包含一个或多个类型参数,用于指定可以适用的类型。
- 泛化模板可以用于定义类模板或函数模板。
template <typename T>
T myMax(T a, T b) {
return (a > b) ? a : b;
}
int main() {
int a = 10, b = 20;
double c = 1.23, d = 4.56;
int max_int = myMax<int>(a, b);
double max_double = myMax<double>(c, d);
return 0;
}
特化
- 特化是一种在泛化模板基础上定义特定类型的模板,它可以覆盖泛化模板的默认实现。
- 特化模板的定义通常包含一个或多个类型参数,用于指定特化的类型。
- 特化模板可以用于定义类模板或函数模板。
template <class Key>struce hash{ };
'特化'
template<>
struce hash<char>{
size_t operator()(char x) const {return x;}
}
struce hash<int>{
size_t operator()(char x) const {return x;}
}
'特化'
template <>
const char* myMax<const char*>(const char* a, const char* b) {
return (strcmp(a, b) > 0) ? a : b;
}
偏特化
- 偏特化是一种在泛化模板基础上定义部分类型的模板,它可以针对某些类型进行特定的实现。
- 偏特化模板的定义通常包含一个或多个类型参数和一个或多个非类型参数,用于指定偏特化的类型。
- 偏特化模板只能用于定义类模板。
- 比如模板当中有两个参数,而偏特化是将一个参数进行绑定,另一个参数根据传进来的类型,来进行判断。
template<class T, class Alloc = alloc>
class vector{...;}
'偏特化'
template<class Alloc>
class vector<bool, Alloc>{...;}
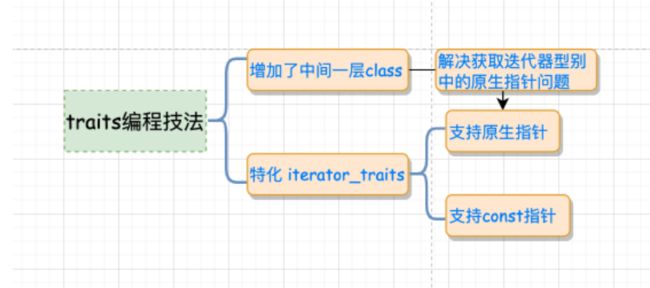
traits(类型萃取机)
- traits在泛型编程中编程中就是增加一层中间的模板class,以解决获取迭代
器的型别中的原生指针问题。利用一个中间层iterator_traits固定了func的形式,使得重复的代码大量减,唯一要做的就是稍稍特化一下iterator_tartis使其支持pointer和constpointer。 - traits就像一台“特性萃取机”,把迭代器放进去,就能榨取出迭代器的特性。
- traits用以分离,class iterator和non-class iterator。
加⼊萃取机前后的变化:
template<typename Iterator> //萃取前
typename Iterator::value_type func(Iterator iter) {
return *iter;
}
//通过 iterator_traits 作⽤后的版本
template<typename Iterator> //萃取后
typename iterator_traits<Iterator>::value_type func(Iterator iter) {
return *iter;
}
为什么还要增加 iterator_traits这⼀层封装,岂不是多此⼀举?
- 回想萃取之前的版本有什么缺陷:不⽀持原⽣指针。⽽通过萃取机的封装,我们可以通过类模板的特化来⽀持原⽣ 指针的版本!如此⼀来,⽆论是智能指针,还是原⽣指针,iterator_traits::value_type 都能起作⽤,这就解决了前 ⾯的问题。
#include - 上述的过程是首先询问iterator_traits::value_type,如果传递的I为指针,则进入特化版本,
iterator_traits直接回答T;如果传递进来的I为classtype,就去询问T::value_type。
通俗的解释可以参照下图:
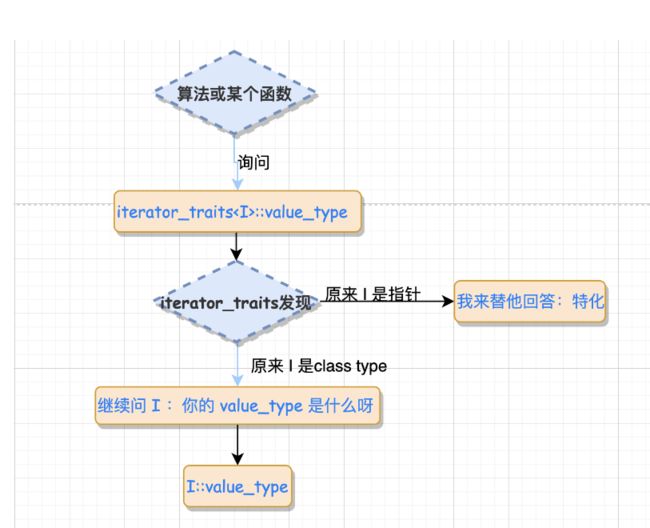
- 总结:核心知识点在于模板参数推导机制+内嵌类型定义机制,为了能处理原生指针这种特殊的迭代器,引入了偏特化机制。
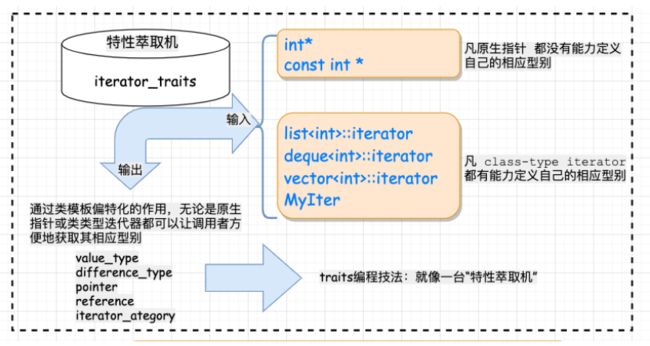
迭代器型别和种类
迭代器的型别
- value_type :迭代器所指对象的类型,原⽣指针也是⼀种迭代器,对于原⽣指针 int*,int 即为指针所指对 象的类型,也就是所谓的 value_type 。
- difference_type : ⽤来表示两个迭代器之间的距离,对于原⽣指针,STL 以 C++ 内建的 ptrdiff_t 作为原 ⽣指针的 difference_type。
- reference_type : 是指迭代器所指对象的类型的引⽤,reference_type ⼀般⽤在迭代器的 * 运算符᯿载 上,如果 value_type 是 T,那么对应的 reference_type 就是 T&;如果 value_type 是 const T,那么对应的 reference_type 就是 const T&。
- pointer_type : 就是相应的指针类型,对于指针来说,最常⽤的功能就是 operator* 和 operator-> 两个 运算符。
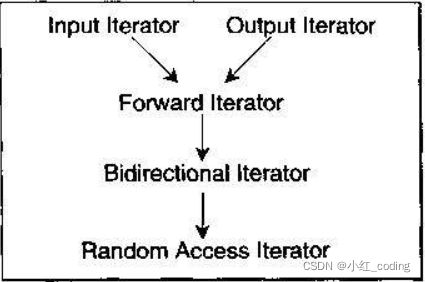
- iterator_category : 的作⽤是标识迭代器的移动特性和可以对迭代器执⾏的操作,从 iterator_category 上,可将迭代器分为 Input Iterator、Output Iterator、Forward Iterator、Bidirectional Iterator、Random Access Iterator 五类,这样分可以尽可能地提⾼效率。
template<typename Category,
typename T,
typename Distance = ptrdiff_t,
typename Pointer = T*,
typename Reference = T&>
struct iterator //迭代器的定义
{
typedef Category iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef Pointer pointer;
typedef Reference reference;
};
- iterator class 不包含任何成员变ᰁ,只有类型的定义,因此不会增加额外的负担。由于后⾯三个类型都有默认值, 在继承它的时候,只需要提供前两个参数就可以了。这个类主要是⽤来继承的,在实现具体的迭代器时,可以继承 上⾯的类,这样⼦就不会漏掉上⾯的 5 个型别了。
迭代器萃取机设计如下:
tempalte<typename I>
struct iterator_traits {//特性萃取机,萃取迭代器特性
typedef typename I::iterator_category iterator_category;
typedef typename I::value_type value_type;
typedef typeanme I:difference_type difference_type;
typedef typename I::pointer pointer;
typedef typename I::reference reference;
};
//需要对型别为指针和 const 指针设计特化版本看
迭代器的分类
迭代器型别 iterator_category 对应的迭代器类别,这个类别会限制迭代器的操作和移动 特性。 除了原⽣指针以外,迭代器被分为五类:
- Input Iterator : 此迭代器不允许修改所指的对象,是只读的。⽀持 ==、!=、++、*、-> 等操作。
- Output Iterator :允许算法在这种迭代器所形成的区间上进⾏只写操作。⽀持 ++、* 等操作。
- Forward Iterator :允许算法在这种迭代器所形成的区间上进⾏读写操作,但只能单向移动,每次只能移 动⼀步。⽀持 Input Iterator 和 Output Iterator 的所有操作。
- Bidirectional Iterator :允许算法在这种迭代器所形成的区间上进⾏读写操作,可双向移动,每次只能 移动⼀步。⽀持 Forward Iterator 的所有操作,并另外⽀持 – 操作。
- Random Access Iterator :包含指针的所有操作,可进⾏随机访问,随意移动指定的步数。⽀持前⾯四种Iterator 的所有操作,并另外⽀持 [n] 操作符等操作。
五种 iterator_category继承关系
混淆
__type_traits负责萃取型别的特性。
型别的特性有:trivial ctor, copy ctor,assignment,dtor以及non-trivial ctor, copy ctor,assignment,dtor,如果答案是不重要的,那我们在对型别进行构造,析构,拷贝,赋值等操作时就可以采用最有效的措施(例如不需要调用constructor,destructor),而是采用内存直接处理操作如 malloc(),nencpy()等。
调用函数的流程:
- 比如调用destory(…),首先会询问iterator_traits::value_type,判断传进的的原生指针类型还是class类型
- 如果传递的I为指针,则进入特化版本,iterator_traits直接回答T;
- 如果传递进来的I为classtype,默认为泛化版本,就去询问它的T::value_type是什么。
- 进入泛化版本后,就会根据它的__type_traits,来判断是否为trivial.
- 如果为trivial,则采取有效措施,(例如不需要调用constructor,destructor,而是采用内存直接处理操作如 malloc(),nencpy()等)
- 如果为non-trivial,则直接调用destroy函数。
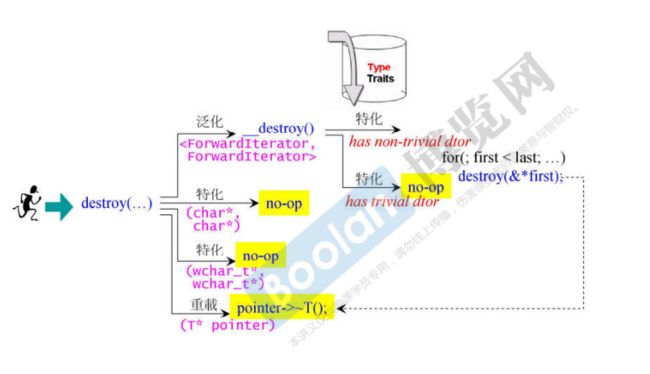
简单说一下traits技法
- traits技法利用“内嵌型别“的编程技巧与编译器的template参数推导功能,用于在编译时根据类型特性进行特定操作的策略选择。。常用的有iterator_traits和type_traits。
- 常用的有iterator_traits和type_traits。
iterator_traits
被称为特性萃取机,萃取迭代器的型别,一共有5种:
- value_type:迭代器所指对象的型别
- difference_type:两个迭代器之间的距离
- pointer:迭代器所指向的型别
- reference:迭代器所引用的型别
- iterator_category:三两句说不清楚,建议看书
type_traits
关注的是型别的特性,例如这个型别是否具备non-trivial defalt ctor(默认构造函数)、non-trivial copy ctor(拷贝构造函数)、non-trivial assignment operator(赋值运算符) 和non-trivial dtor(析构函数),如果答案是否定的,可以采取直接操作内存的方式提高效率,一般来说,type_traits支持以下5中类型的判断:
解释一下什么是trivial destructor
- “trivial destructor”一般是指用户没有自定义析构函数,而由系统生成的,这种析构函数称为不重要的析构函数(trivial destructor)
- 首先利用value_type()获取所指对象的型别,再利用__type_traits判断该型别的析构函数是否trivial,若是(__true_type),则什么也不做,若为(__false_type),则去调用destory()函数。
迭代器:++it、it++哪个好,为什么
- 前置返回一个引用不需要创建临时副本,效率高,后置返回一个对象
// ++i实现代码为——前置:
int& operator++(){
*this += 1;
return *this;
}
- 前置不会产生临时对象,后置必须产生临时对象,临时对象会导致效率降低
//i++实现代码为—后置:
int operator++(int){
int temp = *this;
++*this;
return temp;
}
说一下STL每种容器对应的迭代器
| 容器 | 迭代器 |
|---|---|
| vector、deque | 随机访问迭代器 |
| stack、queue、priority_queue | 无 |
| list、(multi)set/map | 双向迭代器 |
| unordered_(multi)set/map、forward_list | 前向迭代器 |
STL中迭代器失效的情况有哪些?
以vector为例:
插入元素:
- 尾后插入:size < capacity时,首迭代器不失效尾迭代失效(未重新分配空间),size == capacity时,所有迭代器均失效(需要重新分配空间)。
- 中间插入:中间插入:size < capacity时,首迭代器不失效但插入元素之后所有迭代器失效,size == capacity时,所有迭代器均失效。
删除元素:
- 尾后删除:只有尾迭代失效。
- 中间删除:删除位置之后所有迭代失效。
- deque 和 vector 的情况类似
- list双向链表每一个节点内存不连续, 删除节点仅当前迭代器失效,erase返回下一个有效迭代器;
- map/set等关联容器底层是红黑树删除节点不会影响其他节点的迭代器, 使用递增方法获取下一个迭代器 mmp.erase(iter++);
- unordered_(hash) 迭代器意义不大, rehash之后, 迭代器应该也是全部失效
STL迭代器如何实现
- 在STL中的迭代器是一种抽象的概念,它提供了一种统一的方式来访问容器(例如vector、list等)中的元素。STL中的迭代器实际上是一个类模板,由不同容器提供具体的实现。它作为容器和算法的粘合剂。
- 它的作用就是提供把一个遍历容器内部所有元素的接口,因此迭代器内部必须保存一个与容器相关联的指针,然后重载各种运算操作来遍历,其中最重要的是*运算符与->运算符,以及++、–等可能需要重载的运算符重载。
- 最常用的迭代器的相应型别有五种:value type、difference type、pointer、reference、iterator catagoly
- 迭代器分类有5种:输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器。