5道Mysql面试题
1.什么Mysql的事务?事务的四大特性?
Mysql中事务的隔离级别分为四大等级:读未提交(READ UNCOMMITTED)、读提交 (READ COMMITTED)、可重复读 (REPEATABLE READ)、串行化 (SERIALIZABLE,是最高的隔离级别)。
在Mysql中事务的四大特性主要包含:原子性(Atomicity)、一致性(Consistent)、隔离性(Isalotion)、持久性(Durable),简称为ACID。
2.你详细了解过MVCC吗?它是怎么工作的?
MVCC叫做多版本控制,实现MVCC时用到了一致性视图,用于支持读提交和可重复读的实现。
对于一行数据若是想实现可重复读取或者能够读取数据的另一个事务未提交前的原始值,那么必须对原始数据进行保存或者对更新操作进行保存,这样才能够查询到原始值。
在Mysql的MVCC中规定每一行数据都有多个不同的版本,一个事务更新操作完后就生成一个新的版本,并不是对全部数据的全量备份,因为全量备份的代价太大了:

如图中所示,假如三个事务更新了同一行数据,那么就会有对应的v1、v2、v3三个数据版本,每一个事务在开始的时候都获得一个唯一的事务id(transaction id),并且是顺序递增的,并且这个事务id最后会赋值给row trx_id,这样就形成了一个唯一的一行数据版本。
实际上版本1、版本2并非实际物理存在的,而图中的U1和U2实际就是undo log日志(回滚日志),这v1和v2版本是根据当前v3和undo log计算出来的。
InnoDB引擎就是利用每行数据有多个版本的特性,实现了秒级创建“快照”,并不需要花费大量的是时间。
3.Mysql的InnoDB和MyISAM有什么区别?
(1)InnoDB和MyISAM都是Mysql的存储引擎,现在MyISAM也逐渐被InnoDB给替代,主要因为InnoDB支持事务和行级锁,MyISAM不支持事务和行级锁,MyISAM最小锁单位是表级。因为MyISAM不支持行级锁,所以在并发处理能力上InnoDB会比MyISAM好。
(2) 数据的存储上:MyISAM的索引也是由B+树构成,但是树的叶子结点存的是行数据的地址,查找时需要找到叶子结点的地址,再根据叶子结点地址查找数据。
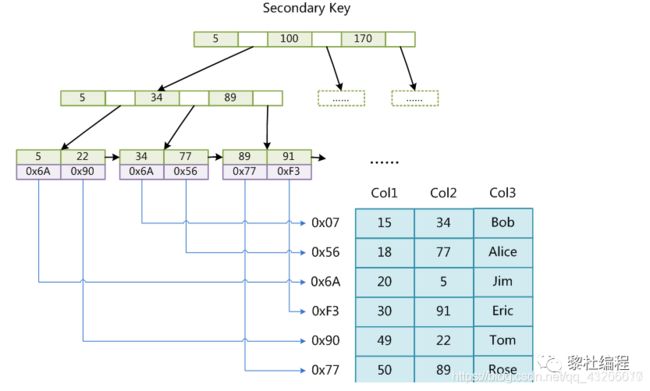
InnoDB的主键索引的叶子结点直接就是存储行数据,查找主键索引树就能获得数据:
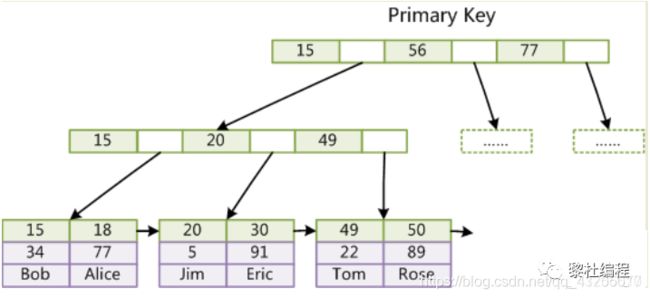
若是根据非主键索引查找,非主键索引的叶子结点存储的就是,当前索引值以及对应的主键的值,若是联合索引存储的就是联合索引值和对应的主键值。
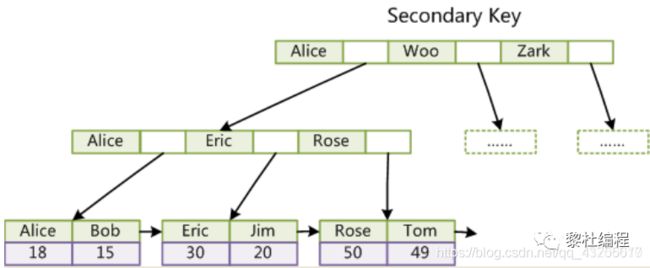
(3)数据文件构成:MyISAM有三种存储文件分别是扩展名为:.frm(文件存储表定义)、.MYD (MYData数据文件)、.MYI (MYIndex索引文件)。而InnoDB的表只受限于操作系统文件的大小,一般是2GB
(4)查询区别:对于读多写少的业务场景,MyISAM会更加适合,而对于update和insert比较多的场景InnoDB会比较适合。
(5)coun(*)区别:select count(*) from table,MyISAM引擎会查询已经保存好的行数,这是不加where的条件下,而InnoDB需要全表扫描一遍,InnoDB并没有保存表的具体行数。
(6)其它的区别:InnoDB支持外键,但是不支持全文索引,而MyISAM不支持外键,支持全文索引,InnoDB的主键的范围比MyISAM的大。
4.你知道执行一条查询语句的流程吗?
当Mysql执行一条查询的SQl的时候大概发生了以下的步骤:
-
客户端发送查询语句给服务器。
-
服务器首先进行用户名和密码的验证以及权限的校验。
-
然后会检查缓存中是否存在该查询,若存在,返回缓存中存在的结果。若是不存在就进行下一步。注意:Mysql 8就把缓存这块给砍掉了。
-
接着进行语法和词法的分析,对SQl的解析、语法检测和预处理,再由优化器生成对应的执行计划。
-
Mysql的执行器根据优化器生成的执行计划执行,调用存储引擎的接口进行查询。服务器将查询的结果返回客户端。
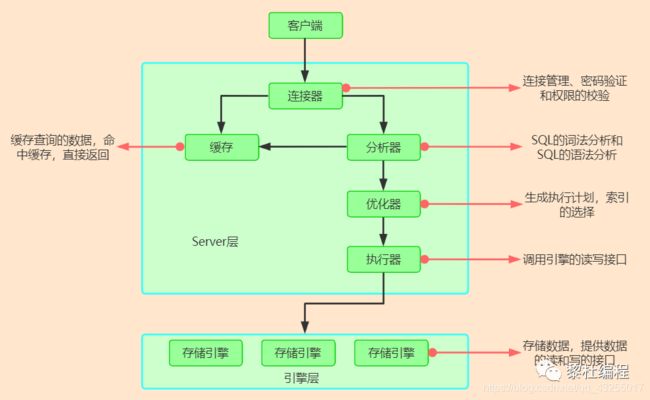
Mysql中语句的执行都是都是分层执行,每一层执行的任务都不同,直到最后拿到结果返回,主要分为Service层和引擎层。
在Service层中包含:连接器、分析器、优化器、执行器。引擎层以插件的形式可以兼容各种不同的存储引擎,主要包含的有InnoDB和MyISAM两种存储引擎。具体的执行流程图如下所示:
5.redo log和binlog了解过吗?
redo log日志也叫做WAL技术(Write- Ahead Logging),他是一种先写日志,并更新内存,最后再更新磁盘的技术,为了就是减少sql执行期间的数据库io操作,并且更新磁盘往往是在Mysql比较闲的时候,这样就大大减轻了Mysql的压力。
redo log是固定大小,是物理日志,属于InnoDB引擎的,并且写redo log是环状写日志的形式:
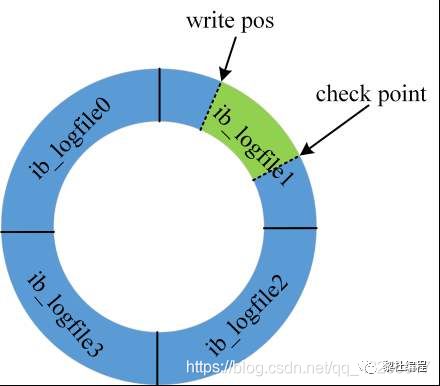
如上图所示:若是四组的redo log文件,一组为1G的大小,那么四组就是4G的大小,其中write pos是记录当前的位置,有数据写入当前位置,那么write pos就会边写入边往后移。
check point记录擦除的位置,因为redo log是固定大小,所以当redo log满的时候,也就是write pos追上check point的时候,需要清除redo log的部分数据,清除的数据会被持久化到磁盘中,然后将check point向前移动。
redo log日志实现了即使在数据库出现异常宕机的时候,重启后之前的记录也不会丢失,这就是crash-safe能力。
binlog称为归档日志,是逻辑上的日志,它属于Mysql的Server层面的日志,记录着sql的原始逻辑,主要有两种模式:一个是statement格式记录的是原始的sql,而row格式则是记录行内容。
redo log和binlog记录的形式、内容不同,这两者日志都能通过自己记录的内容恢复数据。
之所以这两个日志同时存在,是因为刚开始Mysql自带的引擎MyISAM就没有crash-safe功能的,并且在此之前Mysql还没有InnoDB引擎,Mysql自带的binlog日志只是用来归档日志的,所以InnoDB引擎也就通过自己redo log日志来实现crash-safe功能。