go数据结构之slice与map
1. 切片
1. 切片结构定义
type slice struct {
array unsafe.Pointer
len int
cap int
}
array:引用的底层数组,动态数组,可以修改- 如果多个切片的array指针指向同一个动态数组,则它们都可以对底层这个动态数组元素进行修改。
len::长度cap:可以理解为底层动态数组的容量- 当切片添加的元素超过cap后,会引发切片底层数组扩容。
扩容后array指针指向可能会发生更改
- 当切片添加的元素超过cap后,会引发切片底层数组扩容。
2. 切片有长度
package main
import "fmt"
func main() {
slice1 := make([]int, 0, 4)
fmt.Println(len(slice1))
// panic
slice1[0] = 1
}
- 使用下标访问切片,访问范围不能超过切片len
2. 底层动态数组可能会被多个切片引用
package main
import "fmt"
func main() {
slice1 := make([]int, 4, 8)
// 4 8
fmt.Println(len(slice1), " ", cap(slice1))
slice2 := slice1[2:]
// 2 6
fmt.Println(len(slice2), " ", cap(slice2))
}
- 上述例子中两个切片引用的是同一个底层动态数组,slice1是从动态数组头部开始引用,而slice2则是从动态数组第二个元素开始引用
- 所以slice1能对底层动态数组全部八个位置都可以修改,而slice2则只能修改底层数组的后六位下标的位置
当底层动态数组只要有一个切片引用,则整个动态数组就不会被回收,即使这个切片引用的是动态数组的局部- 如slice2引用会导致整个动态数组八位不能回收,虽然它只能访问和修改后六位
3. 函数中,切片是值传递
package main
import "fmt"
func main() {
s1 := make([]int, 4, 8)
fmt.Printf("s1的指针是 %p \n", &s1)
printPoint(s1)
fmt.Printf("s1的底层数组是 %p \n", s1)
printArrPoint(s1)
}
func printPoint(s2 []int) {
fmt.Printf("s2的指针是 %p \n", &s2)
}
func printArrPoint(s2 []int) {
fmt.Printf("s2的底层数组是 %p \n", s2)
}
//s1的指针是 0xc000008078
//s2的指针是 0xc000008090
//s1的底层数组是 0xc000014240
//s2的底层数组是 0xc000014240
- 函数传递切片的时候,其实是把切片复制了一遍
- 但是两个切片指向了同一个底层动态数组
4. 当切片扩容时,(可能)会指向新的底层数组
package main
import "fmt"
func main() {
s1 := make([]int, 4, 4)
s2 := s1
fmt.Printf("s1的底层数组是 [%p], 容量是 [%v]\n", s1, cap(s1))
fmt.Printf("s2的底层数组是 [%p], 容量是 [%v]\n", s2, cap(s2))
s1 = append(s1, 1)
fmt.Printf("s1的底层数组是 [%p], 容量是 [%v]\n", s1, cap(s1))
fmt.Printf("s2的底层数组是 [%p], 容量是 [%v]\n", s2, cap(s2))
}
//s1的底层数组是 [0xc000150020], 容量是 [4]
//s2的底层数组是 [0xc000150020], 容量是 [4]
//s1的底层数组是 [0xc0001200c0], 容量是 [8]
//s2的底层数组是 [0xc000150020], 容量是 [4]
- 当指向同一个底层数组时,s1对数组元素的修改对s2是可见的,当s1指向新的底层数组时,s1则对数组元素的修改则对s2是不可见了,因为它俩指向了不同的底层动态数组
5. 与空比较
package main
import "fmt"
func main() {
var a []int
b := make([]int, 0)
fmt.Printf("a==nil? %v \n", a == nil)
fmt.Printf("b==nil? %v \n", b == nil)
fmt.Printf("len(a)==0? %v \n", len(a))
fmt.Printf("len(b)==0? %v \n", len(b))
fmt.Printf("a的指针是 [%p]\n", &a)
fmt.Printf("b的指针是 [%p]\n", &b)
fmt.Printf("a的底层数组是 [%p]\n", a)
fmt.Printf("b的底层数组是 [%p]\n", b)
}
//a==nil? true
//b==nil? false
//len(a)==0? 0
//len(b)==0? 0
//a的指针是 [0xc000008078]
//b的指针是 [0xc000008090]
//a的底层数组是 [0x0]
//b的底层数组是 [0xe6b438]
- 切片只声明未初始化则不会分配底层数组
- 切片可以和 nil 进行比较,只有当切片底层数据指针为空时切片本身为 nil,这时候切片的长度和容量信息将是无效的。如果有切片的底层数据指针为空,但是长度和容量不为 0 的情况,那么说明切片本身已经被损坏了。
2. map
1. map底层数据结构
type hmap struct {
count int // map 中键值对的数量
flags uint8 // map 的标志位,如是否为引用类型等
B uint8 // map 的桶大小的对数
noverflow uint16 // 溢出桶的数量
hash0 uint32 // 哈希种子值
buckets unsafe.Pointer // 存储桶的指针
oldbuckets unsafe.Pointer // 旧桶的指针,用于扩容时的过渡
nevacuate uintptr // 扩容时,已迁移的桶的数量
extra *mapextra // 用于存储特殊情况下的扩展信息
}
type mapextra struct {
overflow *[]*bmap // 溢出桶的数组,当哈希表中的键值对数量超过某个阈值时会使用溢出桶
oldoverflow *[]*bmap // 旧溢出桶的数组,用于扩容时的过渡
nextOverflow *bmap // 链接下一个溢出桶的指针
}
type bmap struct {
tophash [bucketCnt]uint8
}
//在编译期间会产生新的结构体
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
keys [8]keytype //key数组
values [8]valuetype // value数组
pad uintptr
overflow *bmap //溢出bucket的地址
}
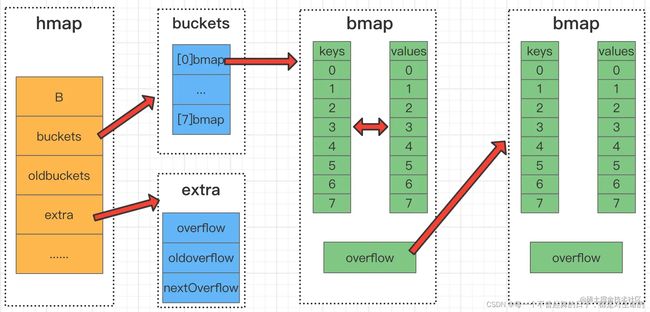
- map的底层结构时 hmap
- 桶数组中每个桶可以存储8个元素,超过了则使用overflow链接到下一个桶(溢出桶),所以使用的是链接法
2. get操作
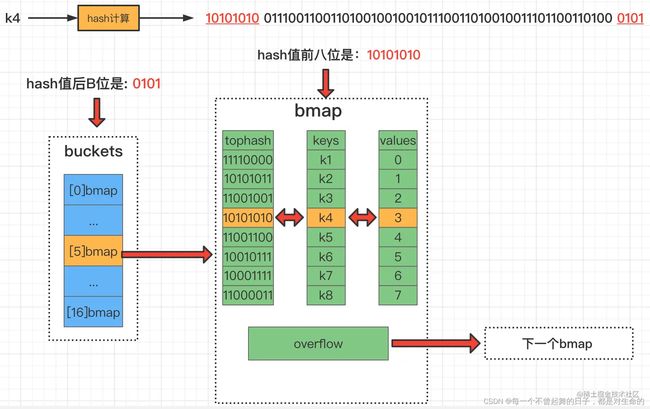
- 首先通过hash函数计算key的哈希值
- 通过后B位来定位到哪个桶
- 定位到桶之后,首先通过hash值高8位去便利tophash数组(
起到一种加速的作用),找到对应的下标i。 - 然后比较keys[i]==key,如果为true,则返回values[i]
- 如果没有找到,则继续便利tophash数组,找到下一个符合的下标i,重复3,4两步
- 如果都没有找到,则去溢出桶里寻找
3. tophash数组的作用
- 主要起到加速的作用
- tophash数组是值数组,每个元素物理位置连续
- 而key数组不一定是值数组,如果key是字符串,则key数组里的元素其实存的不是字符串内容本身,而是一个引用。我们需要再根据这个引用(指针)找到字符串去比较。
- 所以如果只根据key数组去比较的话,则这个过程中访问的内存地址其实不是连续的,速度会慢很多。
4. put操作

- 先根据key进行查找(
过程跟get差不多),如果找到了,则替换value - 如果没找到,定位到对应的桶,找到一个空闲的位置i,进行插入(三个数组对应下标i处都要插入)
- 如果对应桶没有空闲位置,则通过overflow插入到溢出桶中
- 必要时可能会引发扩容
5. 等量扩容
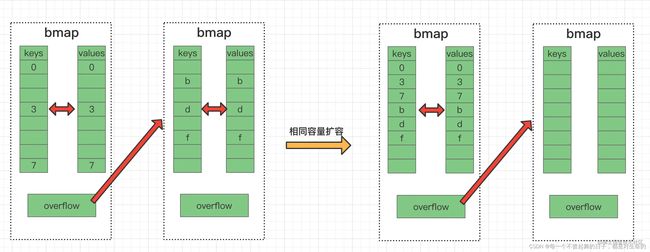
- 当不停地在map中put和delete操作,导致一个桶的溢出桶链很长,但是每个桶里面key存的断断续续也不是很多的时候,会出发等量扩容。
- 所谓等量扩容本不是真的扩容了,而是碎片整理,将key都整理到一起去
- 这种情况下元素会发生重排,但不会产生新的桶(正常桶和溢出桶)
6. 二倍扩容
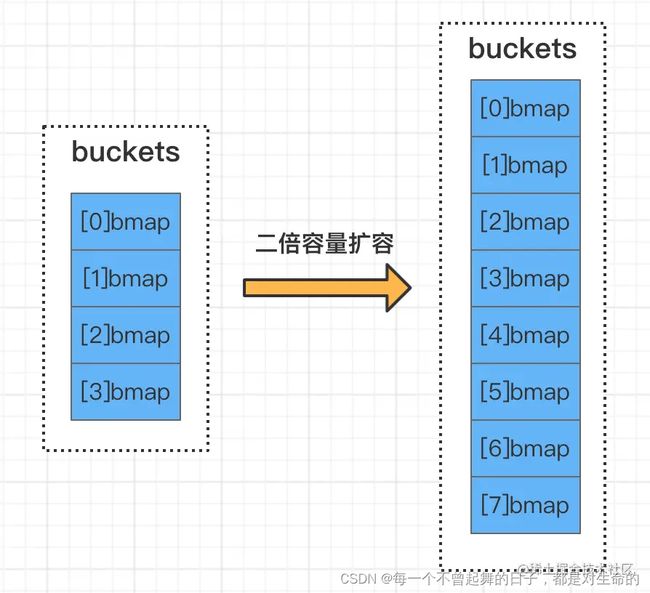
- 正常桶的桶数组大小会翻倍
- 存储的元素会重排,元素所在的桶数组下标可能会改变
- 比如扩容前B=2,扩容后B=3,之前根据key的hash后两位定位,现在看hash的后三位定位。所以对于一个key它新的同下标要么还是原来的
i,要么就是i+len(原来桶数组)
7. 扩容条件
- 当装载因子大于6.5时扩容(
ladFactor=count/(2^B)) - 当溢出桶过多时会扩容
- B<15时,溢出桶数量超过2^B
- B>=15时,溢出同数量超过2^15
8. 在函数中,也是值传递
- 跟切片一样,在函数中也是值传递
- 但是由于底层共享存储结构,所以函数中对map内容修改,出了函数仍是可见
9. map只能与nil比较
package main
import "fmt"
func main() {
a := make(map[string]int, 0)
// false
fmt.Println(a == nil)
var b map[string]int
// true
fmt.Println(b == nil)
}
- 且只有当map底层数据结构未初始化的时候map==nil才为true
参考:https://juejin.cn/post/7029679896183963678#heading-1