前言
Scrapy 是一个流行的网络爬虫框架,它拥有很多简化网站抓取的高级函数。本章中,我们将学习使用 Scrapy 抓取示例网站,目标任务与第2章相同。然后,我们还会介绍 Portia ,这是一个基于 Scrapy 的应用,允许用户通过点击界面抓取网站。
8.1 安装
我们可以使用 pip 命令安装 Scrapy,如下所示。
pip install Scrapy
由于Scrapy依赖一些外部库,因此如果在安装过程中遇到困难的话,可以从其官方网站上获到更多信息,网址为http://doc.scrapy.org/en/latest/intro/install.html。
目前,Scrapy 仅支持Python2.7版本,比本书中介绍的其他包条件更加苛刻 。如果想支持更低的 Python 2.6版本,需要降级到 Scrapy 0.20 版本。而由 于依赖的Twisted 的原因,目前还无法支持 Python 3 版本,不过 Scrapy 团队向我确认他们正在解决这一 问题。
如果 Scrapy 安装成功,那么就可以在终端里执行 scrapy 命令了。
本章中我们将会使用如下几个命令。
startproject:创建一个新项目:
genspider:根据模板生成一个新爬虫:
crawl:执行爬虫:
shell:启动交互式抓取控制台。
要了解上述命令或其他命令的详细信息可以参考下面这个链接
http://doc.scrapy.org/en/latest/topics/commands.html
8.2 启动项目
安装好 Scrapy 以后,我们可以运行 startproject 命令生成该项目的默认结构。具体步骤为:打开终端进入想要存储 Scrapy 项目的目录,然后运行 scrapystartproject
下面是 s crapy 命令生成的文件结构。

其中,在本章比较重要的几个文件如下所示。
items.py:该文件定义了待抓取域的模型。
settings.py:该文件定义了一些设置,如用户代理、爬取延时等。
spiders/:该目录存储实际的爬虫代码。
另外, Scrapy 使用 scrapy.cfg 设置项目配置,使用 pipelines.py 处理要抓取的域,不过在本例 中无须修改这两个文件。
8.2.1 定义模型
默认情况下,example/items.py 文件包含如下代码。

Example IeItem 类是一个模板, 需要将其中的内容替换为爬虫运行时想要存储的待抓取国家信息。为了更好地聚焦 Scrapy 的执行过程,接下来我们只会抓取国家名称和人口数量,而不是抓取 国家的所有信息。下面是修改后支持该功能的模型代码。

8.2.2 创建爬虫
现在, 我们要开始编写真正的爬虫代码了,在 Scrapy 里又被称 为 spider通过genspider命令, 传入爬虫名、域名以及可选的模板参数,就可以生成初始模板。
这里使用内置的 crawl 模板,可以生成更接近我们想要的国家爬虫的初始版本。运行 genspider 命令之后,下面的代码将会在example/spiders/country.py中自动生成。

 最开始几行导入了后面会用到的 Scrapy 库,包括 8.2. 1 节中定义的 Example leltem 模型。然后创建了一个爬虫类,该类包括如下类属性。
最开始几行导入了后面会用到的 Scrapy 库,包括 8.2. 1 节中定义的 Example leltem 模型。然后创建了一个爬虫类,该类包括如下类属性。
name:该属性为定义爬虫名称的字符串。
start_urls:该属性定义 了爬虫起始 URL列表 。 不过 , start_urls 的默认值与我们想要的不一样,在 example.webscraping.com 域名之前多了 WWW 前缀
alloweddomains:该属性定义了可以爬取的域名列表。如果没有定义该属性,则表示可以爬取任何域名。
rules:该属性为一个正则表达式集合,用于告知爬虫需要跟踪哪些链接。
rules 属性还有一个 callback函数,用于解析下载得到的响应,而 parse_item( )示例方法给我们提供了一个从响应中获取数据的例子。
Scrapy 是一个高级框架,因此即使只有这几行代码,也还有很多需要了解的知识。官方文档中 包含了创建爬虫相关的更多细节,其网址为
http://doc.scrapy.org/en/latest/topics/spiders.html
1 . 优化设置
在运行前面生成的爬虫之前 , 需要更新 Scrapy 的设置 , 避免爬虫被封禁 。 默认情况下 , Scrapy 对 同一域名 允许最多 8 个并发下载 , 并且两次下载之间没有延时, 这样就会 比真实用 户 浏览时 的速度快很 多 , 所以很容易被服务器检测到 。 在前言 中 我们提到 , 当下载速度持续高于每秒一个请求时, 我们抓取 的示例 网 站会暂时封禁爬虫 , 也就是说使用 默认配置会造成我们 的爬虫被 封禁。 除非你在本地运行示例网站, 否 则我建议在 example / s etting s . py文件中 添加 如下几行 , 使爬虫 同 时只 能对每个域名 发起一个请求 , 并且每两次请求之间 存在延时 :

请注意,Scrapy 在两次请求之间的延时并不是精确的,这是因为精确的延时同样会造成爬虫容易被检测到,然后被封禁而 Scrapy 实际使用的方法是在两次请求之间的延时上添加随机的偏移量 要想了解更多关于上述设置和其他设置的细节,可以参考
http://doc.scrapy.org/en/latest/topics/settings.html
2. 测试爬虫
想要从命令行运行爬虫,需要使用 c rawl 命令并且带上爬虫的名称。

和预期一样,默认的爬虫代码运行失败了,这是因为http://www.example. webscraping.com并不存在① 。 此外 , 你还会注意到命令中 有一个 - s LOG LEVE L=ERROR 标 记 , 这是一个 Scrapy 设 置 , 等同于 在sett ings . py 文件中 定义 LOG_LEVEL = ’ ERROR ’ 。 默认情况下 , Scrapy 会在终端上输 出 所有 日 志 信 息 , 而这里是将 日 志 级别提升至 只 显 示错 误 信 息
下面的代码更正 了 爬虫的起始 URL, 并且设定 了 要爬取的 网页。

第一条规则爬取索引 页 并跟踪其 中 的链接 , 而第二条规则爬取 国 家页面并 将下载 响 应传 给 ca l lback 函 数用 于抓取 。 下面让我们把 日 志 级别设为 DEBUG 以显示所有信息 , 来看下爬虫是如何运行的 。

输 出 的 日 志信息显示 , 索引页和 国 家页都可 以 正确爬取 , 并且 已经过滤 了 重复链接 。 但是 , 我们还会发现爬虫浪费了很多 资源来爬取每个 网 页上的登 录和注册表单链接, 因为它们也匹配 rules 里 的正则表达式 。 前面命令中 的 登录 URL 以_next= % 2 Findex%2 F l 结尾, 也就是_next= / i口dex / l 经过 URL 编码后 的结果 , 其 目 的 是让服务器端获取用户 登录后 的跳转地址 。 要想 避免爬取这些 URL, 我们可 以使用规则 的 de口y 参数 , 该参数 同样需要一个 正则表达式 , 用 于匹配所有不想爬取 的 U肚。 下面对之前 的代码进行 了修改, 通过避免 URL 包含/ user/来防止爬取用 户 登录和注册表单 。

8.2.3 使用 shell 命令抓取
现在 Scrapy 已经可 以爬取 国 家页面 了 , 下面还需要定义要抓取哪些数据 。 为 了 帮助测试如何从网页中抽取数据 , Scrapy 提供 了 一个很方便的命令一- sr时工 , 可 以下载 URL 并在 P严hon 解释器中给出 结果状态 。 下面是爬取某 个示例 国家时的结果 。
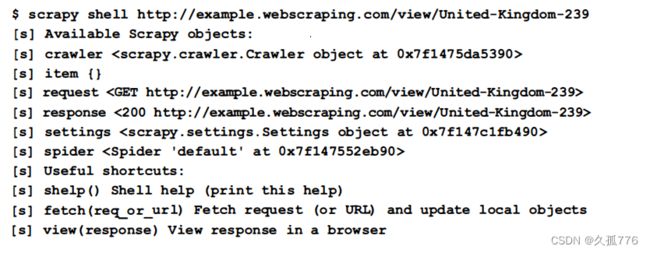
现在我们可 以查询这些对象 , 检查哪些数据可 以使用 。
Scrapy 使用 l xml 抓取数据 , 所以我们仍然可 以使用 第 2 章中用过的 css
选择器。

该方法返回一个 lxml 选择器 , 要想使用它 , 还需要调用 extract ()方法 。

然 后 , 可 以 在先前生成 的 example / spiders / country . py 文 件 的 parse_item ( ) 方法中 使用 这些 css 选择器 。

8.2.4 检查结果
下面是该爬虫 的 完整代码 。


要想保存结果 , 我们可 以在 parse i tem ( ) 方法中 添加额外 的 代码 , 用 于写入 己抓取 的 国 家数据 , 或是定义管道 。 不过 , 这一操作并不是必需的, 因 为 Scrapy 还提供了 一个更方便的一-output 选项 , 用 于 自 动保存 己抓取的 条 目 , 可选格式包括 csv、 JSON 和 XML 。 下面是该爬虫的最终版运行时 的 结果 , 该 结果将会输出 到一个 csv 文件中 , 此外该爬虫 的 日 志级别被设定为 INFO 以 过滤不重要 的信息 。
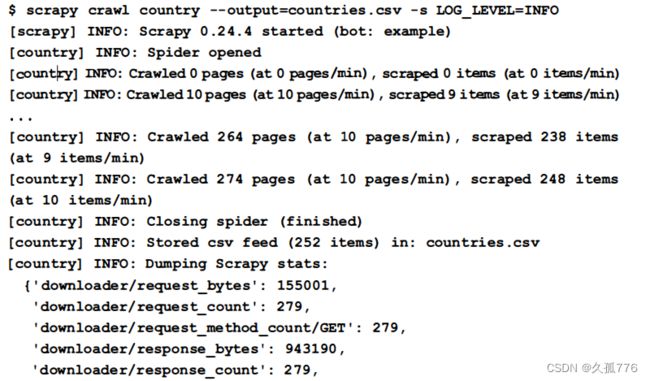

在爬取过程 的最后阶段 , Scrapy 会输出-些统计信息 , 给出 爬虫运行的一 些指标 。 从统计结果 中 , 我们可 以了解到爬虫总共爬取 了 279 个网页, 并抓 取到其中 的 252 个条 日 , 这与数据库 中 的 国家数量一致, 因 此我们知 道爬虫 己经找到 了 所有国家数据 。
要想验证抓取的 这些 国家信息正确与否,我们可以检查 count rie s.c sv 文件中 的 内 容 。

和预期一样 , 表格中 包含了每个国家的名 称和 人 口 数量 。 抓取这些数据所要编写的代码比第 2 章中 的原始爬虫要少很多 , 这是因为 Scrapy 提供了很多 高级功能。 在下一节 中 , 我们将使用 Portia 重新实现该爬虫 , 而且要编写 的 代码更少 。
8.2.5 中断与恢复爬虫
在抓取网站时, 暂停爬虫并于稍后恢复而不是重新开始 , 有 时会很有用 。 比如 , 软件更新后重启计算机 , 或是要爬取的网站出现错误需要稍后继续爬取时, 都可能会中断爬虫 。 非常方便的是, Scrapy 内置了对暂停与恢复爬取的支持 , 这样我们就不需要再修改示例爬虫了 。 要开启该功能 , 我们只需要定义用于保存爬虫当前状态目录的 JOBDIR 设置即可。 需要注意的是, 多个爬虫的状态需要保存在不同的目录当中。 下面是在我们的爬虫中使用该功能的示例 。
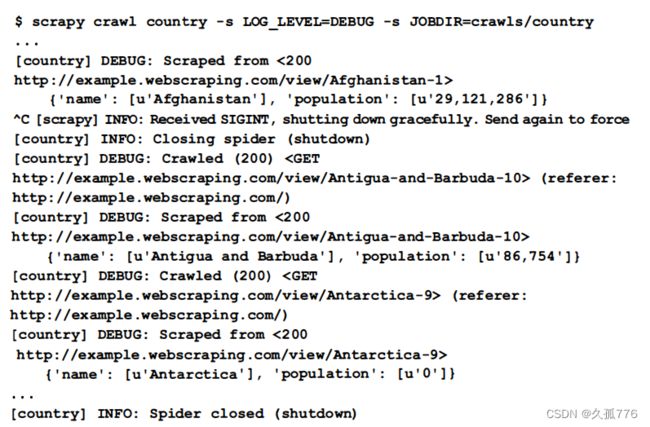
从上述执行过程可以看出,我们使用 AcCCtrl+C )发送终止信号,然后爬虫又完成了几个条目的 处理之后才终止。想要 Scrapy 保存爬虫状态 ,就必须等待它正常结束,而不能经受不住诱惑再次按下C创+C 强行立即终止!现在,爬虫状态保存在crawls/country目录中,之后可以运行同样的命令恢复爬虫运行。

此时, 爬虫从刚才暂停的 地方恢复运行 , 和 正常启 动一样继续进行爬取 。 该功 能对于我们 的 示例 网 站而言用处不大 , 因 为 要下载的页面数量非常小 。 不过, 对于那些需要爬取几个 月 的大型 网 站而言 , 能够暂停和恢复爬虫就非 常方便 了 。
需要注意的是, 有一些边界情况在这里没有覆盖, 可能会在恢复爬取时产生 问题, 比如 cookie 过期等 , 此类问题可以从 Scrapy 的官方文档中进行详细了解, 其网址为 http://doc.s crapy.org/en/latest/topics/jobs.html 。
8.3 使用 Portia 编写可视化爬虫
Portia 是一款基于 Scrapy 开发的 开源工具 , 该工具可 以通过点击要抓取的 网 页部分来创建爬虫 , 这样就 比手工创建 css 选择器的 方式更加方便 。
8.3.1 安装
Portia是一款非常强大的工具 , 为了实现其功能需要依赖很多外部库 。 由于该工具相对较新, 因此下面会稍微介绍一下它的安装步骤。 如果未来该工具的安装步骤有所简化,可以从其最新文档 中 获 取安装方法 , 网 址 为https : / /gi thub . com/scrapinghub/portia#running-portia 。
推荐安装方式的第一步是使用 vi rtua l env 创 建一个虚拟 Py由on 环境 。 这里我们将该环境命名为 portia_example,当然你也可以将其替换成其他任何名称。


然后, 在 vi rtual env 中 安装 Portia 及其依赖 。

Portia目前处于活跃开发期 , 因此在你阅读本书时其接口可能已经发生变化。如果你想使用和本书相同的版本进行开发,可以运行如下git命令 。

如果你还没有安装 git ,可以直接下载 Portia 的最新版 , 其网址为 https : / /gi thub . com/ s crapinhub/portia/archive/master.zip。
安 装完成后 , 可 以进入 slyd 目 录运行服务器端来启 动 Portia。

如果安装成功,就可以在浏览器中访问到 Portia 工具, 网址为 http://localhost:9001/static/main. html 。
下图为初始屏幕
如果你在安装过程中遇到 了 问题, 可 以 查 看 Portia 的 问 题 页 , 网址为 https : / / github . com/ scrapinghub /port ia/issues , 也许其他人 已 经经历过相 同 的 问 题并且找到 了 解决方案。
8.3.2 标注
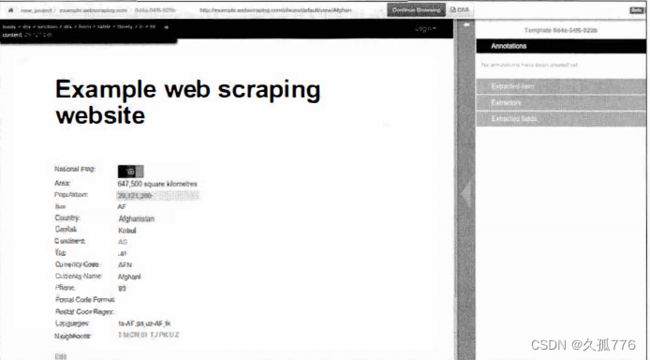
在 Portia 的启动页 , 有一个用 于输入待抓取网站 URL 的 文本 框 , 比如 http:/ / example . webscrapi r可 . com。 输入后 , Portia 会在其主面板加载 该网页,如下图所示
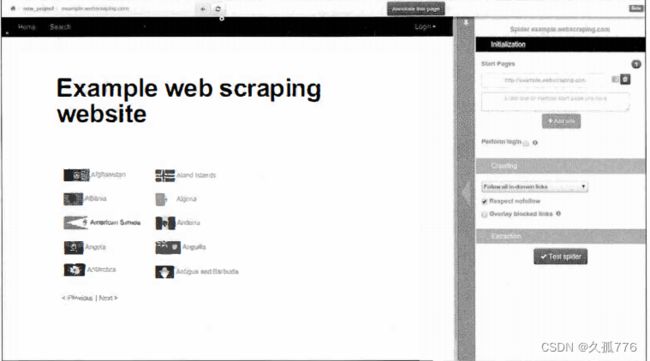
默认情况下 , 项 目 名称被设为 new_project, 而爬虫名称则被设为待爬取 域名 Cexample.webscraping.com ) , 这两项都可以通过单击相应标签进行修改。接下来,浏览器会定位到一个示例国家网页, 让你标注感兴趣的数据,如下图所示
单击 Annotate this page 按钮, 然后再单击国家人口数量 , 就会弹出如下图所示

单击+field 按钮创建一个名 为 popul at ion 的新域,然后单击 Done 保存 。 接下来 , 对国家名称以及你感兴趣的其他域进行相同操作 。 被标注的域会在网页中高亮显示 , 并且可以在右边栏的面板中进行编辑如下图所示
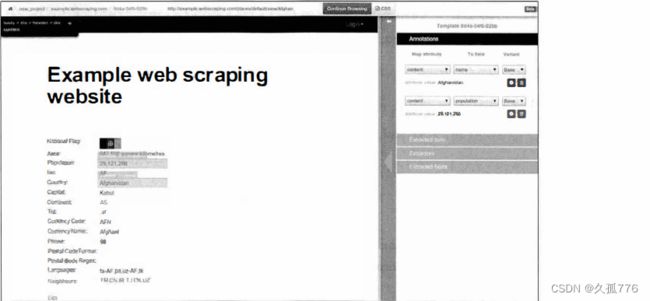
完成标注后 , 单击顶部 的蓝色按钮 Continue Browsing 。
8.3.3 优化爬虫
标注完成后 , Portia 会 生成一个 Scrapy 项目, 并将产生的文件保存到 data/projects 目录中。 要运行爬虫 , 只需执行 port iacrawl 命令,并带上项目名和爬虫名即可。不过,如果爬虫使用默认设置运行的话 , 很快就会遇到服务器错误 。

这和 “优化放置 ” 小节中遇到的问题是一样的 , 因为 Portia 生成的项目使用了默认的 Scrapy 爬取设置,导致下载速度过快。我们仍然可以在设置文件中修改这些设置 ( 文件位于 data/projects /newproject/spiders/settings.py ) 。 不过 , 为了演示一些新方法 , 这次我们改为使用命令行进行设置 。


当运行这个放慢速度的爬虫时,就可以避免被封禁的问题了。不过,接下来同样也会遇到下载非必要网页( 比如登录和注册页 ) 这个降低效率的问题。默认情况下,Portia 生成的爬虫会爬取给定域名的所有URL。要想只爬取特定URL,可以配置右边栏面板中的 Crawling 选项卡, 如下图所示

这里,我们添加/index/ 和/view/作为爬虫跟踪模式,并且将/user/ 作为排除模式,这些都和之前 Scrapy 项目中的用法相似。如果勾选了底部的Overlay blocked links 复选框, Portia 就会把跟踪链接高亮为绿色,排除链接,高亮为红色
8.3.4 检查结果
现在就可以执行 Portia 生成的爬虫了,另外和之前一样,我们使用一output 选项指定输出的 csv 文件。

当运行如上命令时 , 该爬虫将会产生和手工创建的 Scrapy 版本相同的输出。
Portia 是一个非常方便的与 Scrapy 配合的工具 。 对于简单的网站, 使用 Portia 开发爬虫通常速度更快。相反,对于复杂的网站(比如 依赖 JavaScript 的界面),则可以选择使用 Python 直接开发 Scrapy 爬虫。
8.4 使用 Scrapely 实现自动化抓取
为了抓取标注域, Portia 使用了 Scrapely 库 , 这是一款独立于 Portia 之外的非常有用的开源工具,该工具可以从https://github .com/scrapy/scrapely获取。Scrapely 使用训练数据建立从网页中抓取哪些内容的模型,并在以后抓取相同结构的其他网页时应用该模型。下面是该工具的运行示例。

首先 , 将我们想要从 Afghani s tan 网页中抓取的数据传给 Scrapely , 本 例中是 国家名称和人口数量。然后,在另一个 国家页上应用该模型, 可以看出 Scrapely 使用该模型返回了 正确的国家名称和人口数量。
这一工作流允许我们无须知晓网页结构,只把所需内容抽取出来作为训练案例,就可以抓取网页。如果网页内容是静态的,在布局发生改变时,这种方法就会非常有用 。例如一个新闻网站,己发表文章的文本一般不会发生变化,但是其布局可能会更新。这种情况下 Scrapely 可以使用相同的数据重新训练,针对新的网站结构生成模型。
在测试 Scrapely 时,此处使用的示例网页具有良好的结构,每个数据类型的标签和属性都是独立的,因此Scrapely可以正确地训练模型 。但是,对于更加复杂的网页,Scrapely可能在定位内容时失败,因此在其文档中会警告你应当“谨慎训练”。也许今后会有更加健 的自动化爬虫库发布。
8.5 本章小结
本章首先介绍了网络爬虫框架Scrapy,该框架拥有很多能够改善抓取网站效率的高级功能。然后介绍了 Portia,它提供了生成Scrapy爬虫的可视化界面。最后我们试用 Scrapely,Portia 正是使用该库根据给定模型自动化抓取网页的。