【SAM模型超级进化】MobileSAM轻量化的分割一切大模型出现,模型缩小60倍,速度提高40倍,效果不减
目录
- 前言
- 1. 研究背景
- 2. 模型改进思路与对比说明
-
- 2.1 MobileSAM与SAM速度对比
- 2.2 MobileSAM与SAM不同分割结果对比
- 3. 模型使用说明
-
- 3.1 一键全景分割代码示例
- 3.2 提示点分割代码示例
- 4. 总结

论文名称:FASTER SEGMENT ANYTHING: TOWARDS LIGHTWEIGHT SAM FOR MOBILE APPLICATIONS
项目代码地址:https://github.com/ChaoningZhang/MobileSAM
关于MobileSAM模型的相关代码、论文PDF、预训练模型、使用方法等,我都已打包好,供需要的小伙伴交流研究,获取方式如下:
关注文末名片GZH:阿旭算法与机器学习,回复:【MobileSAM】即可获取MobileSAM相关代码、论文、预训练模型、使用方法示例等
前言
MobileSAM模型是在2023年6月27日发布的,其对之前的SAM分割一切大模型进行了轻量化的优化处理,模型整体体积缩小了60倍,运行速度提高40倍,但分割效果却依旧很好。
MobileSAM在使用方法上沿用了SAM模型的接口,因此可以与SAM模型的使用方法几乎可以无缝对接,真的是非常Nice。唯一的区别就是在模型加载的时候需要修改一点点。对于SAM模型的如何使用,博主之前有3篇博文进行了详细介绍。链接如下,对于不熟悉SAM模型使用的小伙伴,可以翻阅之前的博文进行参考:
- 《【CV大模型SAM(Segment-Anything)】真是太强大了,分割一切的SAM大模型使用方法:可通过不同的提示得到想要的分割目标》
- 《【CV大模型SAM(Segment-Anything)】如何保存分割后的对象mask?并提取mask对应的图片区域?》
- 《【CV大模型SAM(Segment-Anything)】如何一键分割图片中所有对象?并对不同分割对象进行保存?》
1. 研究背景
Segment anything model (SAM) 是一个基于提示的视觉基础模型,用于将感兴趣的物体从其背景中切割出来。自Meta研究团队发布SAM(Segment anything model)项目以来,引起了极大的关注,因为它具有令人印象深刻的零样本迁移特性和与其他模型兼容的高通用性,可用于高级视觉应用,如具有细粒度控制的图像编辑。许多这样的用例都需要在资源受限的边缘设备上运行,如移动应用程序。在这项工作中,我们的目标是通过用一个轻量级的图像编码器取代重量级的图像编码器,使SAM成为移动友好型的。最初的SAM模型体积较为庞大,分割效果最好的ViT-H 模型达632M,因此在推理速度上不尽人意。我们发现,这主要是由图像编码器和掩码解码器的耦合优化造成的,在此基础上,我们提出了解耦蒸馏法。具体来说,我们将原始SAM中的图像编码器ViT-H的知识提炼成1个轻量级的图像编码器,它可以与原始SAM中的掩码解码器自动兼容。训练可以在1天之内在单个GPU.上完成,由此产生的轻量级SAM被称为MobileSAM, 它的体积小了60多倍,但性能与原始SAM相当。就推理速度而言,MobileSAM每 张图像的运行时间约为10ms:图像编码器为8ms,掩码解码器为2ms。凭借卓越的性能和更高的通用性,我们的MobileSAM比同期的FastSAM小7倍,快4倍,使其更适合移动端的应用。
2. 模型改进思路与对比说明
在介绍MobileSAM之前,我们必须先了解一下SAM模型。SAM 是一个 label-free 的分割模型,可以和其他模型结合来进行进一步的下游任务,如 text-guided 分割、图像编辑等。
SAM 模型的结构如下图所示,包括两个部分:
ViT-based image encoder
prompt-guided mask decoder
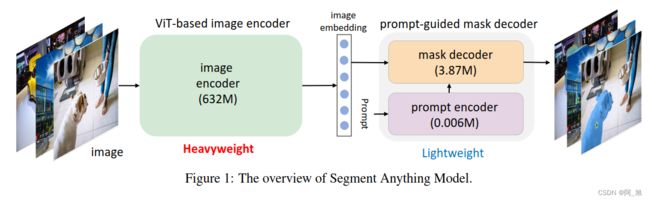
如上表 所示, 相比prompt-guided mask encoder只有 4M参数,ViT-based image encoder的参数量超过632M, 非常重量级,这使得部署SAM模型运行在移动设备端非常困难。因此,实现可移动地分割一切的关键在于保留SAM的所有功能和特性的前提下,用轻量级图像编码器取代官方中提供的重量级的ViT-based image encoder。
一种很自然的想法,就是根据官方训练SAM的做法,把重量级的image encoder替换成轻量级的image encoder再重新训练整个SAM,该训练过程称为knowledge distillation (KD)。然而,这种直接替换再重新训练的难度主要在于image编码器和mask解码器的耦合优化。基于分而治之算法 (divide-and-conquer) 的思想,我们可以固定编码器或者解码器,去优化另一个。
然而,根据经验,我们发现这种优化仍然具有挑战性,因为mask解码器端的prompt的选择是随机的,这使得掩码解码器可变,从而增加了优化难度。因此,我们项目方案的核心就是直接把 ViT-H 蒸馏到小型的图像编码器中, 如下图:
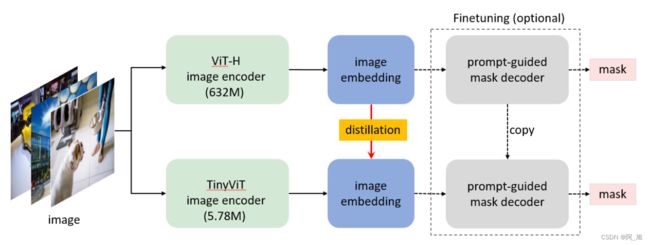
MobileSAM与SAM的参数对比:

MobileSAM与FastSAM的性能对比如下:
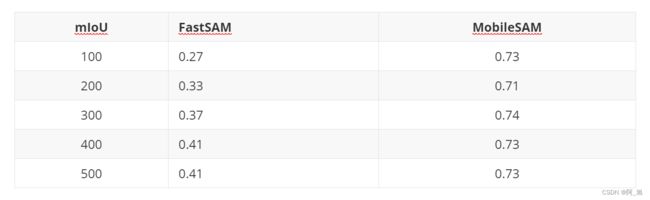
我们仅使用了官方SAM中提供的SA-1B 数据集的 1% (100k)样本进行8次迭代训练模型,在单个GPU (RTX 3090) 中使用不到一天的时间完成训练(对于ViT-H,SAM官方需要11T的数据,使用256个A 100 GPUs,训练超过68小时)。 总体而言,使用较小计算资源,同时实现了 0.70+ 的 mIoU 性能。上表.显示了MobileSAM和官方SAM在模型参数和在单个GPU上处理速度上的对比,MobileSAM处理一张图像仅需要8ms,官方SAM需要452ms。
2.1 MobileSAM与SAM速度对比
MobileSAM的性能与原始SAM相当(至少在视觉上),除了图像编码器的改变外,它与原始SAM保持完全相同的管道。具体来说,我们用一个小得多的Tiny-ViT(5M)取代了原来重量级的ViT-H编码器(632M)。在单个GPU上,MobileSAM每幅图像的运行时间约为12ms: 图像编码器为8毫秒,掩码解码器为4毫秒。
基于ViT的图像编码器的比较总结如下:

原始SAM和MobileSAM有完全相同的提示引导的掩码解码器:

整个模型管道的比较总结如下:

2.2 MobileSAM与SAM不同分割结果对比
【对比1—单个点作为提示结果对比】
原有的SAM和MobileSAM以单个点作为提示,分割结果对比如下:
【对比2—方框作为提示结果对比】
原有的SAM和MobileSAM用一个方框作为提示的分割结果对比如下:
【对比3—分割一切结果对比】

3. 模型使用说明
MobileSAM在使用方法上沿用了SAM模型的接口,因此可以与SAM模型的使用方法几乎可以无缝对接,真的是非常Nice。唯一的区别就是在模型加载的时候需要修改一点点。对于SAM模型的如何使用,博主之前有3篇博文进行了详细介绍。链接如下,对于不熟悉SAM模型使用的小伙伴,可以翻阅之前的博文进行参考:
- 《【CV大模型SAM(Segment-Anything)】真是太强大了,分割一切的SAM大模型使用方法:可通过不同的提示得到想要的分割目标》
- 《【CV大模型SAM(Segment-Anything)】如何保存分割后的对象mask?并提取mask对应的图片区域?》
- 《【CV大模型SAM(Segment-Anything)】如何一键分割图片中所有对象?并对不同分割对象进行保存?》
3.1 一键全景分割代码示例
#coding:utf-8
# 全景分割
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_anns(anns):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
ax = plt.gca()
ax.set_autoscale_on(False)
img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))
img[:,:,3] = 0
for ann in sorted_anns:
m = ann['segmentation']
color_mask = np.concatenate([np.random.random(3), [0.35]])
img[m] = color_mask
ax.imshow(img)
image = cv2.imread('notebooks/images/picture2.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# plt.figure(figsize=(20,20))
# plt.imshow(image)
# plt.axis('off')
# plt.show()
import sys
sys.path.append("..")
from mobile_encoder.setup_mobile_sam import setup_model
checkpoint = torch.load('weights/mobile_sam.pt',map_location=torch.device('cpu'))
mobile_sam = setup_model()
mobile_sam.load_state_dict(checkpoint,strict=True)
from segment_anything import SamAutomaticMaskGenerator
device = "cpu"
mobile_sam.to(device=device)
mobile_sam.eval()
mask_generator = SamAutomaticMaskGenerator(mobile_sam)
masks = mask_generator.generate(image)
print(len(masks))
print(masks[0].keys())
plt.figure(figsize=(20,20))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show()
分割结果如下:
3.2 提示点分割代码示例
#coding:utf-8
# 提示点分割示例
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
image = cv2.imread('images/picture1.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('on')
plt.show()
import sys
sys.path.append("..")
from mobile_encoder.setup_mobile_sam import setup_model
checkpoint = torch.load('../weights/mobile_sam.pt',map_location=torch.device('cpu'))
mobile_sam = setup_model()
mobile_sam.load_state_dict(checkpoint,strict=True)
from segment_anything import SamPredictor
device = "cpu"
mobile_sam.to(device=device)
mobile_sam.eval()
predictor = SamPredictor(mobile_sam)
predictor.set_image(image)
input_point = np.array([[400, 400]])
input_label = np.array([1])
plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show()
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()
分割结果如下所示:


4. 总结
从结果来看,MobileSAM相比于SAM,模型整体体积缩小了60倍,运行速度提高40倍,但分割效果却保持相当水平。个人认为,这对于视觉大模型在移动端的部署与应用是具有里程碑意义的。
关于MobileSAM模型的相关代码、论文PDF、预训练模型、使用方法等,我都已打包好,供需要的小伙伴交流研究,获取方式如下:
关注文末名片GZH:阿旭算法与机器学习,回复:【MobileSAM】即可获取MobileSAM相关代码、论文、预训练模型、使用方法示例等
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!