数据结构---手撕图解单链表---phead的多种传参方式对比和辅助理解
文章目录
- 为什么要引入链表?
- 单链表
-
- 单链表的定义和原理
- 单链表的头插
- 对于指针的深层次理解
- 链表的尾插
-
- 封装malloc函数
- 尾删
- 头删
- 查找
- 链表中元素的插入
-
- 在某节点前插入
- 在某节点后插入
- 链表中元素的删除
-
- 删除pos位置的值
- 删除pos元素之后的值
- 链表的销毁
- 关于链表传参问题如何改变phead
- 所有图片
为什么要引入链表?
前面我们知道了顺序表,当顺序表的容量到达上限后就需要申请新的空间,而申请新空间就会遇到一些问题
1.当利用realloc函数进行申请新空间时,会涉及到开辟新空间–拷贝原有数据–释放原空间这三个步骤,而这三个步骤会有不小的损耗
2.增容一般是2倍的增长,势必会有一部分空间的浪费,如果我们扩容了100个单位大小的空间,但是我们只使用了五个,那么剩下的95个空间就造成了空间的浪费
因此,就引入了链表,链表可以解决上面提到的两个问题
链表的结构复杂多样,我们从单链表开始看
单链表
单链表的定义和原理
和顺序表一样,首先要定义一个链表
定义前我们要明确,链表是如何组成的,所谓链表,就是把数据像链条一样链接起来,这样就形成了一个链表,那么链表的基础结构分为数据部分和指针部分,数据部分存储的就是“表”中的数据,而指针部分就是所谓的“链条”,它可以把每一部分的数据都连接起来,通过第一个表中的指针可以找到第二个表,进而访问第二个表中的数据,再通过第二个表中的指针可以访问第三个表··· 依次就把它们都串了起来
下面是对链表的定义
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
从定义中可以看出,链表在定义的过程中引入了数据部分(data)和指针部分(next),与上面对于链表的组成是一致的,把定义结构体形象图示化如下所示
那么在实际应用中,链表究竟是如何运作的?
下面画出了链表的原理图

我们假设现在创建了1,2,3,4 四个数据部分和指针部分,那么在内存中创建的过程中,它们每一个部分都有一个对应的地址,要注意的是,它们的地址是随机的,并没有任何关系, 我们定义了一个头节点(phead),这个头节点就可以用来访问后面的链表
我们假设,数据部分分别为1,2,3,4的表编号为1,2,3,4
那么通过phead节点中存储的就是1号表的地址,通过phead这个节点我们就能访问到1号表中的信息,而1号表中也分为数据部分和指针部分,指针部分存的内容就是2号表中的地址,通过1号表中的指针部分就可以访问到2号表中的数据部分和指针部分,依次类推,我们就可以把整个链表的数据都进行访问,这个过程就是链表的遍历
那么我们就来写一个函数,用来表示链表的遍历,函数实现如下
void SLTprint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
对这个函数进行分析,它的功能是打印链表中所有的数据,也就是链表的遍历,它的实现过程就是上面所介绍的过程
在函数体中定义了一个cur (current–当前访问的节点),首先把phead中的地址传递给cur,此时cur中存储的就是编号为1的表中的地址,因此通过这个地址就可以访问第一个表中的信息,于是就可以print出编号为1的表的信息
下面重点理解这条语句是什么意思?
cur = cur->next;
要明确的一点是,cur是一个结构体指针,它的功能始终是指向一个结构体,用来对结构体的解引用操作,知道了这一点就不难理解,前面对结构体的定义我们知道,结构体中定义了一个数据部分和一个指针部分,而这个指针部分的数据类型就是结构体指针类型,于是cur的作用就是指向下一个结构体,再利用cur对下一个结构体的data进行解引用,达到遍历的效果,便达到了解引用的效果
那么phead和NULL是什么?
在上面了解完链表的中间部分是如何进行运转的,那么链表的前后部分是如何处理的?
首先,链表的开头会定义一个头节点,这个头指针指向的就是编号为1的表,这样就能开始对链表进行遍历,而当链表遍历到末尾时,链表的最后一个表的指针指向一个NULL,代表着链表已经结束了,NULL的值为0,因此最后一个地址也全为0
至此,对于链表的初步认识结束,我们已经知道了链表是如何进行遍历的,怎样把每一块的数据联系起来,接下来就要体现链表相较于顺序表来说它的优势在哪里
单链表的头插
相对于顺序表,单链表拥有更加高效和方便的插入和删除的功能,具体是如何工作的?
假设我们现在有一个新的节点,数据部分为0,我们把它的编号也记作0
先看图解:

从图解中可以看出它的原理,原理就是保持phead始终指向链表中的第一个表,让phead指向编号为0的表,而编号为0的表的指针部分指向的是编号为1的表,这样就能通过phead访问编号为0的表,再通过编号为0的表的指针部分访问编号为1的数据和指针部分,进而进行链表的遍历
那么代码如何实现?
下面为代码实现,引入了二级指针
void SLPushFront(SLTNode** pphead, SLTDataType x)
{
//为链表开辟空间
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
//为新节点初始化数据
newnode->data = x;
newnode->next = NULL;
//把新节点插入到链表中
newnode->next = *pphead;
*pphead = newnode;
}
对于指针的深层次理解
在链表的学习中,我对指针有了更深入一部分的理解,具体想法如下:
为什么要引用二级指针?传参传的不就是指针了吗?
如果有这个疑惑,说明对传值和传址还有一些疑问,从函数栈帧的角度来看,如果传递的是一级指针,那么会在栈帧内创建一个指针形参,而这个指针形参并不会在结束后返回到函数实参中,而是会随着函数的结束而随之销毁,因此这里要引入的是二级指针,运用二级指针的目的就是使得传参的一级指针被函数体中的操作改变,才能输出合适的结果
在链表的应用中,可以把指针的想法应用如下:
假设我们创建了一个plist,图示如下:

假设在test1中函数传参传的是plist,那么在传递的就是一份plist的拷贝,随着SLPushFront的结束,形参也随之被销毁,此时plist还是指向NULL,那么后续对于plist的操作就不可能成功了
但如果传递的是地址,那这里的pphead就用来管理test函数中的plist,pphead有资格在SLPushFront函数中对plist进行操作,进而使test函数中的plist发生改变,因此在这里我们把newnode的地址给了*pphead,实际上就是把newnode的值给了plist,那么此时plist不再指向NULL,它有了新的指向,于是就完成了链表的插入
于是我们其实可以总结一下
想要修改一个值,就需要传递修改该值的地址,同理,想要修改指针,就需要修改指针的地址,也就是二级指针,想要修改一个结构体,就需要修改结构体的地址
链表的尾插
结束了前面对指针更深层次的理解,就到了对链表尾插的部分
链表的尾插相较于前面来说较为复杂,会利用到较多的结构体和指针的概念,我们把链表尾插这个过程分为多个部分逐个进行分析,最后总结链表尾插的核心和指针的深层次理解
封装malloc函数
为方便后续代码实现,我们把创建newnode节点这个过程可以封装成一个函数
函数实现也很简单,函数实现如下:
SLTNode* BuyLTNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
这样在创建新节点的过程中就可以略去重复的步骤
那么链表尾插的基本思路是什么?
将链表尾插的过程核心图示化如下所示
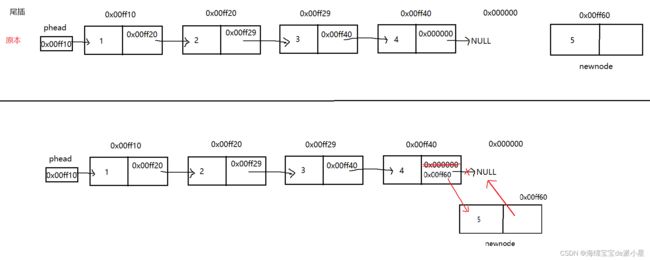
链表的尾插从逻辑来讲并不复杂,只需要把新节点的地址传给原链表的尾节点,让尾节点的指针部分指向新节点的地址,再把新节点置空,这样就结束了链表的创建
但这个过程的函数体实现并不容易,首先看这段错误的分析
下面的函数是错误示范
//错误的示范
void errSLPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
SLTNode* tail = *pphead;
while (tail != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
看起来上述代码没有问题,那么问题出在哪里?还是画图来解释较为方便
这里可以看出,问题就在于当tail找到了NULL后,此时要对tail->next进行修改可以修改吗?
->操作符相当于是一个解引用操作符,那么tail现在都指向了一个NULL,对NULL进行解引用很明显是错误的行为,在vs中也对这个行为进行了警告
![]()
那么就知道原因了,我们要找到尾节点的指针部分,修改指针部分才能到达预期效果,那么更改代码如下
//错误的代码示范
void errSLPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
代码相较前面来说,已经可以有尾插的功能了,但并不能解决所有场景,例如,我们要在空链表中直接插入一个数据,此时依旧不能达到预期,这是因为plist还是NULL,我们在尾插函数中并没有对plist进行操作,plist不能有遍历的效果
由于这里并没有对plist进行操作,所以实际上这里不写二级指针也可以,但不能完全实现尾插功能
解决方案也相当简单,分类讨论即可,直接分类讨论即可得出正确答案
于是将代码更改为:
//正确的示范
void SLPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyLTNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
至此,才能真正完成尾插的功能
尾删
相较于尾插头插,尾删头删相对简单一些
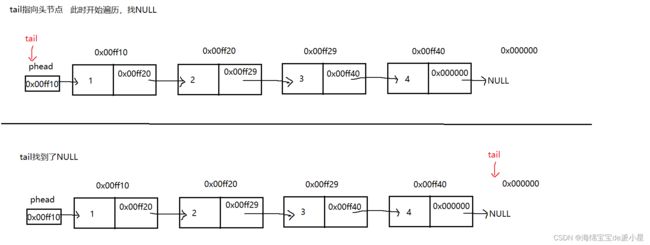
先画模式图,如下图所示
第一种方法如下所示
首先定义tail和prev,tail负责找最后一个节点,prev负责找尾节点前面的节点,再把prev节点的指针指向空即可

代码实现如下
void SLPopBack(SLTNode** pphead)
{
SLTNode* tail = *pphead;
SLTNode* prev = NULL;
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
第二种方法如下所示

原理和上面的类似,只不过用了next->next的方法,整体看和上面方法基本类似
代码实现如下
void SLPopBack(SLTNode** pphead)
{
SLTNode* tail = *pphead;
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
头删
头删与尾删类似,如下所示

代码实现如下:
void SLPopFront(SLTNode** pphead)
{
SLTNode* del = *pphead;
(*pphead) = (*pphead)->next;
free(del);
}
查找
链表的查找较为简单,只需要把链表遍历一遍即可
SLTNode* SLFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
链表中元素的插入
链表的插入较为复杂,首先,链表的插入通常是在节点后,但也有节点前插入
为什么通常是在节点后?
假设我们现在知道一个节点,要在它前面插入数据就必须知道它前面一个表的指针部分,才能进行插入,因此我们还需要寻找要插入节点前面一个节点,较为复杂
在某节点前插入
由前面的分析可知,我们要找到要插入表前面的地址,我们画出示意图
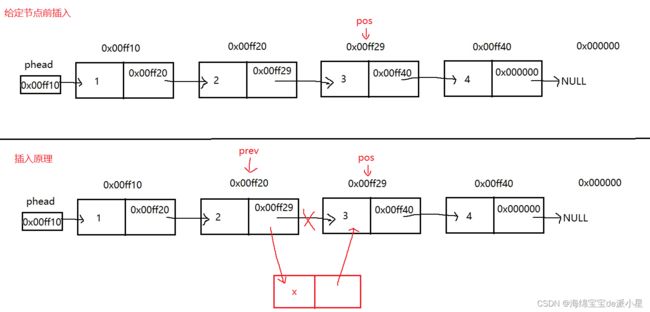
看似已经完成了工作,但是还遗漏了一种特殊情况,假设我们这里是空链表,那么对于代码并不适用,因此要分类讨论

最终代码实现如下
void SListInsertBefore(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);
SLTNode* newnode = BuyLTNode(x);
SLTNode* prev = *pphead;
//如果头节点插入
if (pos == *pphead)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
在某节点后插入
搞清楚节点前插入,节点后插入就很简单了,只需要pos就可以完成插入
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = BuyLTNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
链表中元素的删除
删除pos位置的值
// 删除pos位置的值
void SLErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
删除pos元素之后的值
void SLEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* next = pos->next;
pos->next = next->next;
free(next);
}
整体难度偏低,画图简单分析即可
链表的销毁
链表销毁也是逐层销毁,具体实现原理如下所示
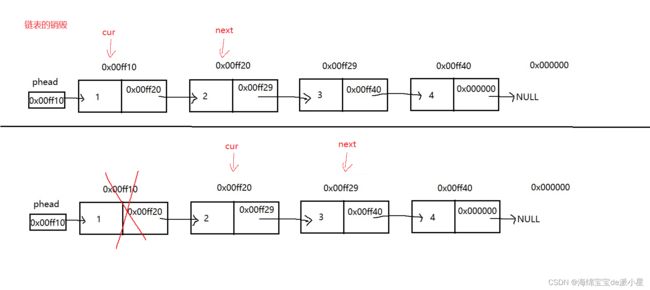
首先,定义cur节点和next节点,利用cur找到next节点,再把cur节点销毁,逐次向后遍历就能把整个链表销毁,最后释放pphead即可
代码实现如下
void SListDestroy(SLTNode** pphead)
{
assert(pphead);
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* next = cur->next;
free(cur);
cur->next;
}
*pphead = NULL;
}
函数传擦过程中phead的多种传参方式和对比辅助理解
关于链表传参问题如何改变phead
- 用二级指针
链表phead指向的是结构体,如果传递的是一级指针,改变的是phead的临时拷贝
如果想要改变phead的指向,即改变phead指向什么就用二级指针
- 返回值就不用二级指针
之所以用二级指针,是因为用一级指针相当于在函数体中创建出了一个phead(这个phead就是实参中的一份临时拷贝),在函数中进行的所有操作会让这个临时拷贝的phead改变,这个phead除了和真实的phead地址不一样以外都一样
因此可以把这个phead当作返回值,把它返回到调用这个函数的函数中,让原来的phead接收一下这个经过函数体的临时拷贝的phead
这两个方法区别之一就是,如果用二级指针,那么phead全程都是一个地址,但如果用返回值的方法,phead在内存中的地址会一直变化,因为每调用一次包含返回值的函数就相当于重新创建了一个phead把原来的phead覆盖掉了,进入函数体内的phead在函数体内完成一系列操作后返回出来,把原来的phead覆盖掉,这样就变临时拷贝为永久拷贝,永久的代替了传参前phead的位置
- 用哨兵位就不用二级指针
哨兵位相当于在堆上创建出一个结构体,把phead放到这个结构体中,这样就相当于是管理了结构体中的成员,这个结构体中的成员就是phead,那么后续对phead进行改变就相当于改变结构体的成员,只需要结构体的指针
所有图片