Langchain
1 Langchain 基本介绍
Langchain官方文档:https://docs.langchain.com/docs/
Langchain Python官方文档:https://python.langchain.com/en/latest/index.html
Langchain中文文档:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
LangChain Simple Tutorial Vedio:https://www.youtube.com/watch?v=a89vqgK-Qcs
LangChain Simple Tutorial Codes:https://github.com/Coding-Crashkurse/Langchain-Full-Course
LangChain Tutorial Vedio:https://www.youtube.com/playlist?list=PL8motc6AQftk1Bs42EW45kwYbyJ4jOdiZ
LangChain Tutorial Codes:https://github.com/samwit/langchain-tutorials
LangChain是一个用于开发由大语言模型(Large Language Model)驱动的应用程序的框架。旨在帮助开发人员使用LLM构建端到端的应用程序。
LangChain的作用:开发人员在使用LLM 存在一定局限性,如不能联网搜索以及有限输入长度等等,从而影响开发效率。LangChain在此背景下应运而生,来解决这些问题,允许LLM与外部数据源连接并与环境进行交互。
2 LangChain模块介绍
LangChain的每个组件(Component)都是模块化的,不同组件组合在一起可以完成一个特定任务或者应用程序(Chain)。比如,一个Chain包含一个 Prompt 模板、一个语言模型和一个输出解析器,这些组件组合在一起来处理用户输入、生成响应并处理输出。
以下便是对每个模块的介绍:
2.1 Model I/O
模型是任何LLM应用的关键,LangChain提供了模型及其输入输出相关的模块。

2.1.1 Prompts
prompt(提示)是LLM的输入。有两种类型的Prompts。
Prompt templates:就是Prompt的模板,可能会包含一系列用户提供的参数。
from langchain import PromptTemplate
# 方法一
prompt_template = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}."
)
prompt = prompt_template.format(adjective="funny", content="chickens")
# 方法二
template = "Tell me a {adjective} joke about {content}."
prompt_template = PromptTemplate.from_template(template)
prompt_template.input_variables = ['adjective', 'content']
prompt = prompt_template.format(adjective="funny", content="chickens")
2.1.2 Language Models
LangChain整合了多种模型接口,比如 OpenAI、Hugging Face、AzureOpenAI …
模型类型主要包含LLMs和Chat Models这两种类型。二者的区别是LLMs的输入/输出是文本字符串,Chat Models的输入/输出是聊天消息。
(1)LLMs:
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="...") # 如果环境变量中有的话就不需要key
# 单次回答
llm("Tell me a joke")
# -> 'Why did the chicken cross the road?\n\nTo get to the other side.'
# 多次回答
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*15)
len(llm_result.generations)
# -> 30
(2)Chat Models:
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage, SystemMessage
chat = ChatOpenAI(open_api_key="...") # 如果环境变量中有的话就不需要key
# 单次回答
# 方法1
chat([HumanMessage(content="Translate this sentence from English to French: I love programming.")])
# -> AIMessage(content="J'aime programmer.", additional_kwargs={})
# 方法2
messages = [
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
]
chat(messages)
# -> AIMessage(content="J'aime programmer.", additional_kwargs={})
# 多次回答
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)
# -> LLMResult(generations=[[ChatGeneration(text="J'aime programmer.", generation_info=None, message=AIMessage(content="J'aime programmer.", additional_kwargs={}))], [ChatGeneration(text="J'aime l'intelligence artificielle.", generation_info=None, message=AIMessage(content="J'aime l'intelligence artificielle.", additional_kwargs={}))]], llm_output={'token_usage': {'prompt_tokens': 57, 'completion_tokens': 20, 'total_tokens': 77}})
2.1.3 Output parsers
这个的应用主要是格式化输出结果。比如实际开发中想要LLM生成json格式的数据是很难的,而langchain的StructuredOutputParser可以轻松将输出的格式设置为json格式。
2.2 Data connection (Index)
将LLM与外部数据相连,包括load, transform, embed, store and retrieve五个功能。即数据预处理的过程。
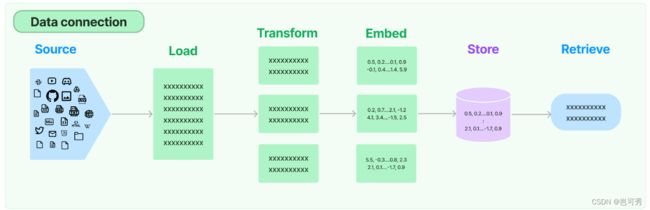
2.2.1 Document Loaders(文档加载器):
从各种来源加载文档的类,比如 CSV、Markdown、PDF、HTML等。当使用loader加载器读取到数据后,需要转换成 Document 对象方便后续使用。
from langchain.document_loaders import TextLoader
loader = TextLoader("./index.md")
loader.load()
# -> [Document(page_content='---\nsidebar_position: 0\n---\n# Document loaders\n\nUse document loaders to load data from a source as `Document`\'s. A `Document` is a piece of text\nand associated metadata. For example, there are document loaders for loading a simple `.txt` file, for loading the text\ncontents of any web page, or even for loading a transcript of a YouTube video.\n\nEvery document loader exposes two methods:\n1. "Load": load documents from the configured source\n2. "Load and split": load documents from the configured source and split them using the passed in text splitter\n\nThey optionally implement:\n\n3. "Lazy load": load documents into memory lazily\n', metadata={'source': '../docs/docs_skeleton/docs/modules/data_connection/document_loaders/index.md'})]
2.2.2 Document transformers(文档转换器)/Text Splitters(文本拆分器):
在导入文档后,一般都需要将文档进行转换,最简单的例子就是将文本拆分为更小并且有语义的段。这么做的意义是防止与LLM交互时超过token限制以及后续的相关性查询。
文本拆分本质上是先根据一些标点符号,如[“\n\n”, “\n”, " ", “”]进行切分,然后根据一些参数再对这些文本进行合并。
from langchain.text_splitter import RecursiveCharacterTextSplitter
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100, # 文本片段的长度
chunk_overlap = 20, # 文本片段之间的重合程度(为了保存上下文)
length_function = len, # 文本长度的计算方法
add_start_index = True, # 文本片段开头的位置
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
# -> page_content='Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and' metadata={'start_index': 0}
print(texts[1])
# -> page_content='of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.' metadata={'start_index': 82}
对于LLM来说都存在token限制,因此在进行拆分时最好计算token的数量。但是tokenizers(分词器)有很多种,我们在使用的时候记得使用跟LLM一样的分词器。
from langchain.text_splitter import CharacterTextSplitter, TokenTextSplitter
with open('../../state_of_the_union.txt') as f:
state_of_the_union = f.read()
# 方法1
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
# 方法2
text_splitter = TokenTextSplitter(chunk_size=10, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
2.2.3 Text embedding models(文本嵌入模型):

Embeddings(嵌入)就是为一段文本创建一个向量。这么做的好处是可以进行语义相关的搜索,而相关性搜索本质上就是向量运算。在LangChain中嵌入分为两种类型,一种是embedding documents(多个文本输入),另一种是embedding a query(单个文本输入)。这是因为embedding providers (OpenAI, Cohere, Hugging Face, etc)采用了不同嵌入方式。
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...") # 如果环境变量中有的话就不需要key
# embed_documents
embeddings = embedding_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
# -> (5, 1536)
# embed_query
embedded_query = embedding_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
# -> [0.0053587136790156364, -0.0004999046213924885, 0.038883671164512634, -0.003001077566295862, -0.00900818221271038]
2.2.4 VectorStores(向量数据库)
文本嵌入后,如果想要持久化就可以存入向量数据库(最为常用)。(转换很简单,只需存储到对应的向量数据库中即可完成向量的转换,内部已经封装好了嵌入的过程,但是注意大部分需要依赖embedding。)
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
query = "What did the president say about Ketanji Brown Jackson"
# Similarity search(字符串作为参数)
docs = db.similarity_search(query)
print(docs[0].page_content)
# Similarity search by vector(向量作为参数)
embedding_vector = embeddings.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
2.2.5 Retrievers(检索器)
对接向量存储与搜索,比如 Chroma、Weaviate,主要任务是提供“get_relevant_documents”的方法。
2.3 Chains
对于比较简单的应用可以只使用单一的LLMs,但是比较复杂的应用需要使用chaining LLMs。Chain可以被比较笼统地定义为一个调用组件的序列。
Chain的好处:能够简化复杂应用程序的实现并使之模块化。并且其不仅可以将多个模块合并成一个chain,也可以多个chain合并成一个复杂的chain,并且可以把上一个chain的output作为下一个chain的input传入,甚至还可以使用条件判断对不同的结果做出不同的反应。
2.4 Memory
默认情况下Chains和Agents都是无状态的,也就是说只能处理单次的请求。而很多应用程序,比如说聊天机器人,记住human和bot之间的对话历史是十分重要的(both in the short and long-term)。Memory就是干这个的。
需要注意只有一些特定的Chain才支持Memory,如ConversationChain、ConversationalRetrievalChain等。
2.5 Agents
LangChain中的Agent是驱动决策制定的实体。它使用 LLM 来确定执行哪些操作以及执行顺序。Agent可是访问一组工具,并根据用户的输入决定调用哪个工具,或者直接将结果返回给用户。
Agent可以构建复杂的应用程序,这些应用程序需要自适应和特定于上下文的响应。当存在取决于用户输入和其他因素的未知交互链时,它们特别有用。
Tool工具是Agent中的核心概念:Tools就是Agent可以采取的行动。(common utilities (e.g. search), other chains, or even other agents.)