postgresql 数据库 索引 介绍
postgresql 数据库 索引 介绍
文章目录
- postgresql 数据库 索引 介绍
- 前言
- 一 什么是索引?
- 二 简介
- 三 索引的种类
-
-
- B-tree
- Hash索引
- GiST索引
- GIN 索引
- BRIN 索引
- SP-GiST索引
-
- CREATE INDEX
-
- 1.大纲
- 2.描述
- 3. 参数
-
- UNIQUE
- CONCURRENTLY
- IF NOT EXISTS
- INCLUDE
- name
- ONLY
- method
- column_name
- expression
- collation
- opclass
- opclass_parameter
- ASC
- DESC
- NULLS FIRST
- NULLS LAST
- storage_parameter
- tablespace_name
- predicate
- 4.示例
- ALTER INDEX
-
- 1. 大纲
- 2.描述
- 3.参数
-
- IF EXISTS
- column_number
- name
- new_name
- tablespace_name
- extension_name
- storage_parameter
- value
- 4.示例
- DROP INDEX
-
- 1. 大纲
- 2.描述
- 3.参数
-
- CONCURRENTLY
- IF EXISTS
- name
- CASCADE
- RESTRICT
- 4.示例
- REINDEX
-
- 1.大纲
- 描述
- 参数
-
- INDEX
- TABLE
- SCHEMA
- DATABASE
- SYSTEM
- name
- CONCURRENTLY
- VERBOSE
- 4.示例
- 5.日常重建索引
- 6. 注解
- 7. Rebuilding Indexes Concurrently
- reindexdb
-
- 大纲
- 描述
- 参数
- 示例
- 九 索引的优缺点
-
- 索引的负面影响和相关成本
- 危害
-
- 指数级的开销
- 内存使用
- 随机写:更新索引成本高
- 索引比表需要更多的缓存
- WAL生成
- 越来越多的I/O
- 对VACUUM/AUTOVACUUM的影响
- 因小失大
- 更大的存储需求
- 索引更容易膨胀
- 改进的
- 总结
前言
大家在学习数据库的时候,是不是常常听到索引?那什么是索引呢?索引有哪些作用呢?索引有哪些种类呢?为什么要建索引呢?带着这些疑问,本文带你一起学习postgresql数据库的索引。
一 什么是索引?
索引是提高数据库性能的常用途径。比起没有索引,使用索引可以让数据库服务器更快找到并获取特定行。但是索引同时也会增加数据库系统的日常管理负担,因此我们应该聪明地使用索引。
索引其实就是一种数据结构,将数据库中的数据以一定的数据结构算法进行存储。当表数据量越来越大时查询速度会下降,建立合适的索引能够帮助我们快速的检索数据库中的数据,快速定位到可能满足条件的记录,不需要遍历所有记录。
官方文档
http://postgres.cn/docs/14/indexes.html
二 简介
假设我们有一个如下的表:
CREATE TABLE test1 (
id integer,
content varchar
);
而应用发出很多以下形式的查询:
SELECT content FROM test1 WHERE id = constant;
在没有事前准备的情况下,系统不得不扫描整个test1表,一行一行地去找到所有匹配的项。如果test1中有很多行但是只有一小部分行(可能是0或者1)需要被该查询返回,这显然是一种低效的方式。但是如果系统被指示维护一个在id列上的索引,它就能使用一种更有效的方式来定位匹配行。例如,它可能仅仅需要遍历一棵搜索树的几层而已。
类似的方法也被用于大部分非小说书籍中:经常被读者查找的术语和概念被收集在一个字母序索引中放在书籍的末尾。感兴趣的读者可以相对快地扫描索引并跳到合适的页而不需要阅读整本书来寻找感兴趣的材料。正如作者的任务是准备好读者可能会查找的术语一样,数据库程序员也需要预见哪些索引会有用。
正如前面讨论的,下列命令可以用来在id列上创建一个索引:
CREATE INDEX test1_id_index ON test1 (id);
索引的名字test1_id_index可以自由选择,但我们最好选择一个能让我们想起该索引用途的名字。
为了移除一个索引,可以使用DROP INDEX命令。索引可以随时被创建或删除。
一旦一个索引被创建,就不再需要进一步的干预:系统会在表更新时更新索引,而且会在它觉得使用索引比顺序扫描表效率更高时使用索引。但我们可能需要定期地运行ANALYZE命令来更新统计信息以便查询规划器能做出正确的决定。通过第 14 章的信息可以了解如何找出一个索引是否被使用以及规划器在何时以及为什么会选择不使用索引。
索引也会使带有搜索条件的UPDATE和DELETE命令受益。此外索引还可以在连接搜索中使用。因此,一个定义在连接条件列上的索引可以显著地提高连接查询的速度。
在一个大表上创建一个索引会耗费很长的时间。默认情况下,PostgreSQL允许在索引创建时并行地进行读(SELECT命令),但写(INSERT、UPDATE和DELETE)则会被阻塞直到索引创建完成。在生产环境中这通常是不可接受的。在创建索引时允许并行的写是可能的。
一个索引被创建后,系统必须保持它与表同步。这增加了数据操作的负担。因此哪些很少或从不在查询中使用的索引应该被移除。
三 索引的种类
PostgreSQL提供了多种索引类型: B-tree、Hash、GiST、SP-GiST 、GIN 和 BRIN。每一种索引类型使用了 一种不同的算法来适应不同类型的查询。默认情况下, CREATE INDEX命令创建适合于大部分情况的B-tree 索引。
SELECT * FROM pg_am where amtype='i';
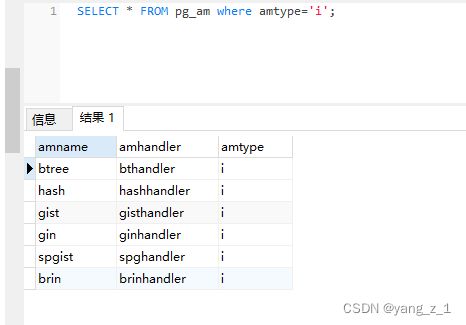
pg_am为每一种索引方法都包含一行(内部被称为访问方法)。PostgreSQL中内建了对表 常规访问的支持,但是所有的索引方法则是在pg_am中描述。可以通过编写必要的代码并且 在pg_am中创建一项来增加一种新的索引访问方法. 一个索引方法的例程并不直接了解它将要操作的数据类型。而是由一个操作符类标识索引方法用来操作一种特定数据类型的一组操作
B-tree
B-tree可以在可排序数据上的处理等值和范围查询。特别地,PostgreSQL的查询规划器会在任何一种涉及到以下操作符的已索引列上考虑使用B-tree索引:<、<=、=、>=、>。 将这些操作符组合起来,例如BETWEEN和IN,也可以用B-tree索引搜索实现。同样,在索引列上的IS NULL或IS NOT NULL条件也可以在B-tree索引中使用。
操作符类标识该列上索引要使用的操作符。例如,一个int4类型上的B树索引会使用int4_ops类,这个操作符类包括用于int4类型值的比较函数。实际上列的数据类型的默认操作符类通常就足够了。存在多个操作符类的原因是,对于某些数据类型可能会有多于一种的有意义的索引行为。例如,我们可能想要对一种复数数据类型按照绝对值排序或者按照实数部分排序。我们可以通过为该数据类型定义两个操作符类来实现,并且在创建一个索引时选择合适的类。操作符类会决定基本的排序顺序(可以通过增加排序选项COLLATE、 ASC/DESC和/或 NULLS FIRST/NULLS LAST来修改)。
下面的查询展示了所有已定义的操作符类:
SELECT am.amname AS index_method,
opc.opcname AS opclass_name,
opc.opcintype::regtype AS indexed_type,
opc.opcdefault AS is_default
FROM pg_am am, pg_opclass opc
WHERE opc.opcmethod = am.oid
ORDER BY index_method, opclass_name;
B-tree索引也可以用于检索排序数据。这并不会总是比简单扫描和排序更快,但是总是有用的。B-tree索引是最常见的索引并且适合处理等值查询和范围查询的索引。
Hash索引
适用场景:hash索引存储的是被索引字段VALUE的哈希值,只支持简单的等值查询。hash索引特别适用于字段VALUE非常长(不适合b-tree索引,因为b-tree一个PAGE至少要存储3个ENTRY,所以不支持特别长的VALUE)的场景,例如很长的字符串,并且用户只需要等值搜索,建议使用hash index。 在pg10之前是不提倡使用hash索引的,因为hash索引不会写wal日志。不过从pg10开始解决了这一问题,并且对hash索引进行了一些加强hash索引其主要目的就是对于某些数据类型(索引键)的值,我们的任务是快速找到匹配的行的ctid。 Hash索引只能处理简单等值比较。不论何时当一个索引列涉及到一个使用了=操作符的比较时,查询规划器将考虑使用一个Hash索引。Hash索引只能处理简单的等值查询。
CREATE INDEX name ON table USING HASH (column);
GiST索引
iST索引并不是一种单独的索引,而是可以用于实现很多不同索引策略的基础设施。相应地,可以使用一个GiST索引的特定操作符根据索引策略(操作符类)而变化。作为一个例子,PostgreSQL的标准捐献包中包括了用于多种二维几何数据类型的GiST操作符类,它用来支持使用下列操作符的索引化查询:<<、&<、 &> 、>> 、<<、&<、&>、>>、@> 、<@ 、~= 、&&。

GIST是广义搜索树generalized search tree的缩写。这是一个平衡搜索树。用于解决一些B-tree,GIN难以解决的数据减少问题,例如,范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点
GIN 索引
GIN(Generalized Inverted Index, 通用倒排索引) 是一个存储对(key, posting list)集合的索引结构。GIN 索引是“倒排索引”或“反转索引”,它适合于包含多个组成值的数据值,例如数组。倒排索引中为每一个组成值都包含一个单独的项,它可以高效地处理测试指定组成值是否存在的查询。倒排索引来源于搜索引擎的技术,正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找、删除等操作。
GIN索引常用于查询索引字段中的部分元素值,如在text类型和json类型字段中检索某个关键字。相同的键值只存储一次。
在PG中,GIN索引会为每一个键建立一个B-tree索引,这会导致GIN索引的更新速度非常慢,因为插入或更新一条记录,所有相关键值的索引都会被更新。 PG提供gin_pending_list_limit参数来控制GIN索引的更新速度,适当将maintenance_work_mem参数增大,可以加快GIN索引的创建过程。如果查询返回的结果集特别大,则可以用gin_fuzzy_search_limit参数来控制返回的行数,默认为0,不限制,一般建议设置为5000~20000比较合适。
与 GiST 和 SP-GiST相似, GIN 可以支持多种不同的用户定义的索引策略,并且可以与一个 GIN 索引配合使用的特定操作符取决于索引策略。作为一个例子,PostgreSQL的标准贡献包中包含了用于数组的GIN操作符类,它用于支持使用下列操作符的索引化查询:
| 编号 | 操作符 |
|---|---|
| 1 | <@ |
| 2 | @> |
| 3 | = |
| 4 | && |

BRIN 索引
BRIN 索引是块级索引,有别于B-TREE等索引,BRIN记录并不是以行号为单位记录索引明细,而是记录每个数据块或者每段连续的数据块的统计信息。因此BRIN索引空间占用特别的小,对数据写入、更新、删除的影响也很小。
BRIN 索引(块范围索引的缩写)存储有关存放在一个表的连续物理块范围上的值摘要信息。与 GiST、SP-GiST 和 GIN 相似,BRIN 可以支持很多种不同的索引策略,并且可以与一个 BRIN 索引配合使用的特定操作符取决于索引策略。对于具有线性排序顺序的数据类型,被索引的数据对应于每个块范围的列中值的最小值和最大值,使用这些操作符来支持用到索引的查询:<、<=、=、>=、>
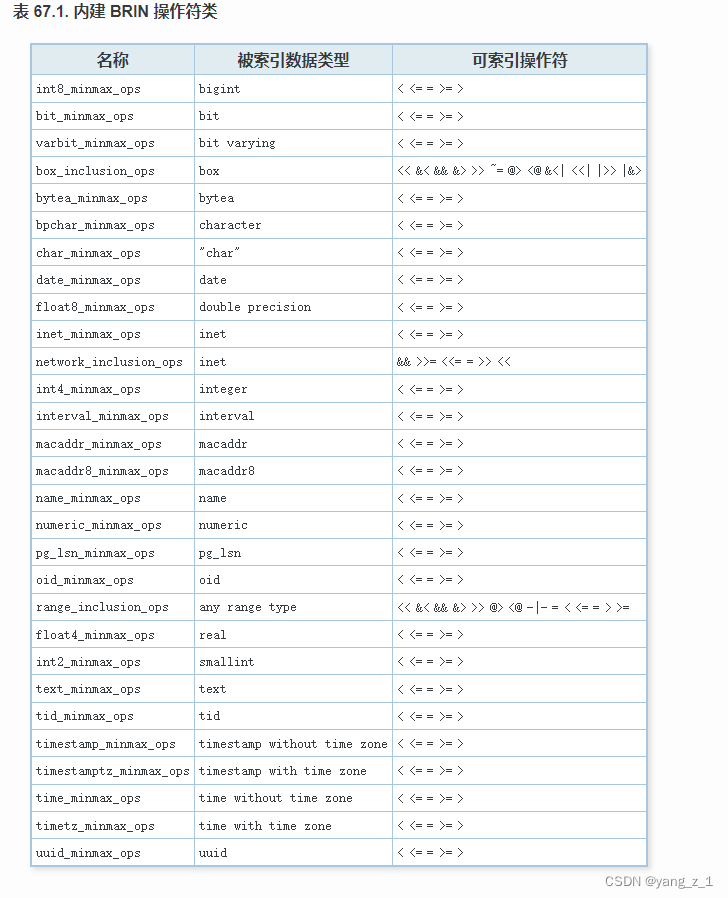
BRIN属于LOSSLY索引,当被索引列的值与物理存储相关性很强时,BRIN索引的效果非常的好。例如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很好。与我们已经熟悉的索引不同,BRIN避免查找绝对不合适的行,而不是快速找到匹配的行。BRIN是一个不准确的索引:不包含表行的ctid。
表被分割成ranges(好多个pages的大小):因此被称作block range index(BRIN)。在每个range中存储数据的摘要信息。作为规则,这里是最小值和最大值,但有时也并非如此。假设执行了一个查询,该查询包含某列的条件;如果所查找的值没有进入区间,则可以跳过整个range;但如果它们确实在,所有块中的所有行都必须被查看以从中选择匹配的行。在元数据页和摘要数据之间,是reverse range map页(revmap)。是一个指向相应索引行的指针(TIDs)数组。
在BRIN索引中,PostgreSQL会为每个8k大小的存储数据页面读取所选列的最大值和最小值,然后将该信息(页码以及列的最小值和最大值)存储到BRIN索引中。一般可以不把BRIN看作索引,而是看作顺序扫描的加速器。如果我们把每个range都看作是一个虚拟分区,那么我们可以把BRIN看作分区的替代方案。BRIN适合单值类型,当被索引列存储相关性越接近1或-1时,数据存储越有序,块的边界越明显,BRIN索引的效果就越好。
SP-GiST索引
SP代表空间分区。这里的空间通常就是我们所说的空间,例如,一个二维平面。但我们会发现,任何搜索空间,实际上都是任意值域。不相交的特性简化了在插入和搜索时的决策。另一方面,作为规则,树是低分枝的。例如,四叉树的一个节点通常有四个子节点(与b树不同,b树的节点有数百个),而且深度更大。像这样的树很适合在内存中工作,但索引存储在磁盘上,因此,为了减少I/O操作的数量,必须将节点打包到页中。此外,由于分支深度的不同,在索引中找到不同值所需的时间也会不同。
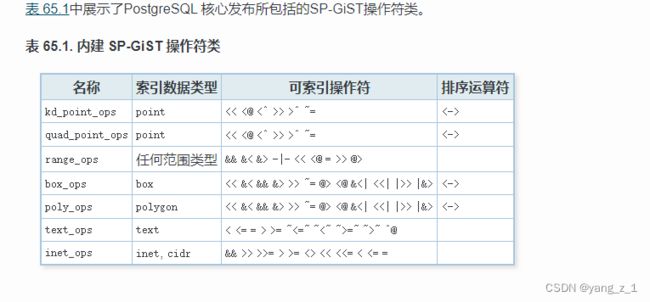
和GiST相似,SP-GiST索引为支持多种搜索提供了一种基础结构。SP-GiST 允许实现众多不同的非平衡的基于磁盘的数据结构,例如四叉树、k-d树和radix树。作为一个例 子,PostgreSQL的标准捐献包中包含了一个用于二维点的SP-GiST操作符类,它用于支持使用下列操作符的索引化查询:<<、>>、~=、<@、<、>。
CREATE INDEX
1.大纲
CREATE INDEX — 定义一个新索引
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name [ USING method ] ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] ) [ INCLUDE ( column_name [, ...] ) ] [ WITH ( storage_parameter [= value] [, ... ] ) ] [ TABLESPACE tablespace_name ] [ WHERE predicate ]
2.描述
CREATE INDEX在指定关系的指定列上构建 一个索引,该关系可以是一个表或者一个物化视图。索引主要被用来提升 数据库性能(不过不当的使用会导致性能变差)。
索引的键域被指定为列名或者写在圆括号中的表达式。如果索引方法支持 多列索引,可以指定多个域
。
一个索引域可以是一个从表行的一列或者更多列值进行计算的表达式。 这种特性可以被用来获得对基于基本数据某种变换的数据的快速访问。 例如,一个在upper(col)上计算的索引可以允许子句 WHERE upper(col) = 'JIM’使用索引。
PostgreSQL提供了索引方法 B-树、哈希、GiST、SP-GiST、GIN 以及 BRIN。用户也可以定义自己的索引 方法,但是相对较复杂。
当WHERE子句存在时,会创建一个 部分索引。部分索引只包含表中一部分行的项, 通常索引这一部分会比表的其他部分更有用。例如,如果有一个表包含了 已付和未付订单,其中未付订单占了整个表的一小部分并且是经常被使用 的部分,可以通过只在这一部分上创建一个索引来改进性能。另一种可能 的应用是使用带有UNIQUE的 WHERE在表的一个子集上强制唯一性。
WHERE子句中使用的表达式只能引用底层表的列,但 它可以引用所有列而不仅仅是被索引的列。当前, WHERE中也禁止使用子查询和聚集表达式。同样的 限制也适用于表达式索引中的表达式域。
所有在索引定义中使用的函数和操作符必须是“不可变的”, 就是说它们的结果必须仅依赖于它们的参数而不受外在因素(例如另 一个表的内容和当前的时间)的影响。这种限制确保了索引的行为是 良定的。要在一个索引表达式或者WHERE子句中 使用用户定义的函数,记住在创建函数时把它标记为不可变。
3. 参数
UNIQUE
导致系统在索引被创建时(如果数据已经存在)或者加入数据时 检查重复值。会导致重复项的数据插入或者更新尝试将会产生一 个错误。当唯一索引被应用在分区边上时会有额外的限制
CONCURRENTLY
当使用了这个选项时,PostgreSQL在构建索引时 不会取得任何会阻止该表上并发插入、更新或者删除的锁。而标准的索引 构建将会把表锁住以阻止对表的写(但不阻塞读),这种锁定会持续到索 引创建完毕。对于临时表,CREATE INDEX始终是非并发的,因为没有其他会话可以访问它们,并且创建非并发索引的成本更低。
IF NOT EXISTS
如果一个同名关系已经存在则不要抛出错误。这种情况下会发出一个提示。 注意着并不保证现有的索引与将要创建的索引有任何相似。当 IF NOT EXISTS被指定时,需要指定索引名。
INCLUDE
可选的INCLUDE子句指定一个列的列表,其中的列将被包括在索引中作为非键列。非键列不能作为索引扫描的条件,并且该索引所强制的任何唯一性或者排除约束都不会考虑它们。不过,只用索引的扫描可以返回非键列的内容而无需访问该索引的基表,因为在索引项中就能直接拿到它们。因此,非键列的增加允许查询使用只用索引的扫描,否则就无法使用。保守地向索引中增加非键列是明智的,特别是很宽的列。如果一个索引元组超过索引类型允许的最大尺寸,数据插入将会失败。在任何情况下,非键列都会重复来自索引基表的数据并且让索引的尺寸膨胀,因此可能会拖慢搜索。此外,B树重复数据删除永远不会与具有非关键列的索引一起使用。INCLUDE子句中列出的列不需要合适的操作符类,甚至数据类型没有为给定的访问方法定义操作符类的列都可以包括在这个子句中。不支持把表达式作为被包括列,因为它们不能被用在只用索引的扫描中。当前,有B-树和GiST索引访问方法支持这一特性。在B-树和GiST索引中,INCLUDE子句中列出的列的值被包括在对应于堆元组的叶子元组中,但是不包括在用于树导航的上层索引项中。
name
要创建的索引名称。这里不能包括模式名,因为索引总是被创建在其基表所在 的模式中。如果索引名称被省略,PostgreSQL将基于基 表名称和被索引列名称选择一个合适的名称。
ONLY
如果该表是分区表,指示不要在分区上递归创建索引。默认会递归创建索引。 table_name 要被索引的表的名称(可以被模式限定)。
method
要使用的索引方法的名称。可以选择 btree、hash、 gist、spgist、 gin以及brin。 默认方法是btree。
column_name
一个表列的名称。
expression
一个基于一个或者更多个表列的表达式。如语法中所示,表达式通常必须 被写在圆括号中。不过,如果该表达式是一个函数调用的形式,圆括号可 以被省略。
collation
要用于该索引的排序规则的名称。默认情况下,该索引使用被索引列 的排序规则或者被索引表达式的结果排序规则。当查询涉及到使用非 默认排序规则的表达式时,使用非默认排序规则的索引就能排上用场。
opclass
一个操作符类的名称。
opclass_parameter
运算符类参数的名称。
ASC
指定上升排序(默认)。
DESC
指定下降排序。
NULLS FIRST
指定把空值排序在非空值前面。在指定DESC时, 这是默认行为。
NULLS LAST
指定把空值排序在非空值后面。在没有指定DESC时, 这是默认行为。
storage_parameter
索引方法相关的存储参数的名称。详见 Index Storage Parameters。
tablespace_name
在其中创建索引的表空间。如果没有指定,将会使用 default_tablespace。或者对临时表上的索引使用 temp_tablespaces。
predicate
部分索引的约束表达式。
4.示例
在表films中的列title上创建一个 B-树索引:
CREATE UNIQUE INDEX title_idx ON films (title);
要在表films的列title上创建一个唯一的B-树索引并且包括列director和rating:
CREATE UNIQUE INDEX title_idx ON films (title) INCLUDE (director, rating);
要创建禁用重复数据删除的 B 树索引:
CREATE INDEX title_idx ON films (title) WITH (deduplicate_items = off);
在表达式lower(title)上创建一个索引来允许高效的大小写 无关搜索:
CREATE INDEX ON films ((lower(title)));
(在这个例子中我们选择省略索引名称,这样系统会选择一个名字, 通常是films_lower_idx)。
创建一个具有非默认排序规则的索引:
CREATE INDEX title_idx_german ON films (title COLLATE "de_DE");
创建一个具有非默认空值排序顺序的索引:
CREATE INDEX title_idx_nulls_low ON films (title NULLS FIRST);
创建一个具有非默认填充因子的索引:
CREATE UNIQUE INDEX title_idx ON films (title) WITH (fillfactor = 70);
创建一个禁用快速更新的GIN索引:
CREATE INDEX gin_idx ON documents_table USING GIN (locations)
WITH (fastupdate = off);
在表films中的列code上创建一个而索引并且 把索引放在表空间indexspace中:
CREATE INDEX code_idx ON films (code) TABLESPACE indexspace;
在一个点属性上创建一个 GiST 索引,这样我们可以在转换函数的结果 上有效地使用 box 操作符:
CREATE INDEX pointloc
ON points USING gist (box(location,location));
SELECT * FROM points WHERE box(location,location) && '(0,0),(1,1)'::box;
创建一个表而不排斥对表的写操作:
CREATE INDEX CONCURRENTLY sales_quantity_index ON sales_table (quantity);
ALTER INDEX
ALTER INDEX — 更改一个索引的定义
1. 大纲
ALTER INDEX [ IF EXISTS ] name RENAME TO new_name
ALTER INDEX [ IF EXISTS ] name SET TABLESPACE tablespace_name
ALTER INDEX name ATTACH PARTITION index_name
ALTER INDEX name DEPENDS ON EXTENSION extension_name
ALTER INDEX [ IF EXISTS ] name SET ( storage_parameter [= value] [, ... ] )
ALTER INDEX [ IF EXISTS ] name RESET ( storage_parameter [, ... ] )
ALTER INDEX [ IF EXISTS ] name ALTER [ COLUMN ] column_number
SET STATISTICS integer
ALTER INDEX ALL IN TABLESPACE name [ OWNED BY role_name [, ... ] ]
SET TABLESPACE new_tablespace [ NOWAIT ]
2.描述
ALTER INDEX更改一个现有索引的定义。下面描述了几种子窗体。 注意每个子窗体所需的锁级别可能不同。除非显式说明,ACCESS EXCLUSIVE锁被持有。 列出多个子命令时,锁的持有将是任何子命令所需的最严格的子命令。
RENAME
RENAME形式更改该索引的名称。如果索引与一个表约束(UNIQUE、PRIMARY KEY或者EXCLUDE)关联,该约束也会被重命名。这对已存储的数据没有影响。
重命名索引取得一个 SHARE UPDATE EXCLUSIVE锁。
SET TABLESPACE
这种形式更改该索引的表空间为指定的表空间,并且把与该索引相关联的数据文件 移动到新的表空间中。要更改一个索引的表空间,你必须拥有该索引并且具有新表 空间上的CREATE特权。可以使用 ALL IN TABLESPACE形式把当前数据库中在一个表空间内的 所有索引全部移动到另一个表空间中,这将会锁定所有要被移动的索引然后挨个移 动它们。这种形式也支持OWNED BY,即只移动属于指定角色 的索引。如果指定了NOWAIT选项,那么当该命令无法立刻获 得所有锁时将会失败。注意这个命令不会移动系统目录,如果想要移动系统目录, 应使用ALTER DATABASE或者显式的 ALTER INDEX调用。另见 CREATE TABLESPACE。
ATTACH PARTITION
导致提到的索引变成附着于被修改的索引。提及的索引必须在包含被修改索引的表的一个分区上,并且具有一种等效的定义。一个附着索引不能被单独删除,它会在其父索引被删除时自动连带删除。
DEPENDS ON EXTENSION extension_name
NO DEPENDS ON EXTENSION extension_name
这种形式将索引标记为依赖于扩展,或者如果指定了 NO ,则不再依赖于该扩展名。标记为依赖于扩展名的索引会在删除扩展名时自动删除。
SET ( storage_parameter [= value] [, … ] )
这种形式为该索引更改一个或者多个索引方法相关的存储参数。可用的参数详见 CREATE INDEX。注意这个命令不会立刻修改索引内容, 根据参数你可能需要用REINDEX重建索引来得到想要的 效果。
RESET ( storage_parameter [, … ] )
这种形式把一个或者多个索引方法相关的存储参数重置为其默认值。正如 SET一样,可能需要一次REINDEX来完全更新 该索引。
ALTER [ COLUMN ] column_number SET STATISTICS integer
这种形式为后续的ANALYZE操作设置针对每个列的统计信息收集目标,不过只能用在被定义为表达式的索引列上。由于表达式缺少唯一的名称,我们通过该索引列的顺序号来引用它们。收集目标可以被设置为范围0到10000之间的值。另外,把它设置为-1会恢复到使用系统的默认统计信息目标(default_statistics_target)。
3.参数
IF EXISTS
如果该索引不存在不要抛出错误。这种情况下将发出一个提示。
column_number
引用该索引列的顺序(从左往右)位置的顺序号。
name
要更改的一个现有索引的名称(可能被模式限定)。
new_name
该索引的新名称。
tablespace_name
该索引将被移动到的表空间。
extension_name
该索引所依赖的扩展的名称。
storage_parameter
一个索引方法相关的存储参数的名称。
value
一个索引方法相关的存储参数的新值。根据该参数,这可能是一个数字或者一个 词。
4.示例
要重命名一个现有索引:
ALTER INDEX distributors RENAME TO suppliers;
把一个索引移动到一个不同的表空间:
ALTER INDEX distributors SET TABLESPACE fasttablespace;
更改一个索引的填充因子(假设该索引方法支持填充因子):
ALTER INDEX distributors SET (fillfactor = 75);
REINDEX INDEX distributors;
为一个表达式索引设置统计信息收集目标:
CREATE INDEX coord_idx ON measured (x, y, (z + t));
ALTER INDEX coord_idx ALTER COLUMN 3 SET STATISTICS 1000;
DROP INDEX
DROP INDEX — 移除一个索引
1. 大纲
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
2.描述
DROP INDEX从数据库系统中 移除一个已有的索引。要执行这个命令你必须是该索引的拥 有者。
3.参数
CONCURRENTLY
删除索引并且不阻塞在索引基表上的并发选择、插入、更新和删除操作。一个 普通的DROP INDEX会要求该表上的排他锁,这样会阻塞 其他访问直至索引删除完成。通过这个选项,该命令会等待直至冲突事务完成。
在使用这个选项时有一些需要注意的事情。只能指定一个索引名称,并且不支 持CASCADE选项(因此,一个支持UNIQUE或者 PRIMARY KEY约束的索引不能以这种方式删除)。还有,常规 的DROP INDEX命令可以在一个事务块内执行,而 DROP INDEX CONCURRENTLY不能。 最后,不能使用此选项删除分区表上的索引。
对于临时表,DROP INDEX始终是非并发的,因为没有其他会话可以访问它们,而且丢弃非并发索引更加便宜。
IF EXISTS
如果该索引不存在则不要抛出一个错误,而是发出一个提示。
name
要移除的索引的名称(可以是模式限定的)。
CASCADE
自动删除依赖于该索引的对象,然后删除所有 依赖于那些对象的对象(见第 5.14 节)。
RESTRICT
如果有任何对象依赖于该索引,则拒绝删除它。这是默认值。
4.示例
这个命令将移除索引title_idx:
DROP INDEX title_idx;
REINDEX
REINDEX — 重建索引
1.大纲
REINDEX [ ( option [, …] ) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } [ CONCURRENTLY ] name
其中 选项 可以是以下之一:
VERBOSE
描述
REINDEX使用索引的表里存储的数据重建一个索引, 并且替换该索引的旧拷贝。有一些场景需要使用REINDEX:
一个索引已经损坏,并且不再包含合法数据。尽管理论上这不会发生, 实际上索引会因为软件缺陷或硬件失效损坏。 REINDEX提供了一种恢复方法。
一个索引变得“臃肿”,其中包含很多空的或者近乎为空的页面。 PostgreSQL中的 B-树索引在特定的非 常规访问模式下可能会发生这种情况。REINDEX 提供了一种方法来减少索引的空间消耗,即制造一个新版本的索引,其中没有 死亡页面。详见下文 5.日常重建索引
修改了一个索引的存储参数(例如填充因子),并且希望确保这种修改完全 生效。
如果索引在用CONCURRENTLY选项创建失败,该索引保留为一个“invalid”。 这类索引是无用的,但是可以方便的用REINDEX来重建它们。注意,只有REINDEX INDEX可以在无效的索引上执行并发创建。
参数
INDEX
重新创建指定的索引。
TABLE
重新创建指定表的所有索引。如果该表有一个二级 “TOAST”表,它也会被重索引。
SCHEMA
重建指定方案的所有索引。如果这个方案中的一个表有次级的“TOAST”表,它也会被重建索引。共享系统目录上的索引也会被处理。这种形式的REINDEX不能在事务块内执行。
DATABASE
重新创建当前数据库内的所有索引。共享的系统目录上的索引也会被 处理。这种形式的REINDEX不能在一个 事务块内执行。
SYSTEM
重新创建当前数据库中在系统目录上的所有索引。共享系统目录上的 索引也被包括在内。用户表上的索引则不会被处理。这种形式的 REINDEX不能在一个事务块内执行。
name
要被重索引的特定索引、表或者数据库的名字。索引和表名可以被 模式限定。当前,REINDEX DATABASE和 REINDEX SYSTEM只能重索引当前数据库,因此 它们的参数必须匹配当前数据库的名称。
CONCURRENTLY
使用此选项时,PostgreSQL 将重建索引,而不在表上采取任何阻止并发插入、更新或删除的锁; 标准的索引重建将会锁定表上的写操作(而不是读操作),直到它完成。 使用此选项—时,有几个事项需要注意;请参阅下面的Rebuilding Indexes Concurrently。
对于临时表,REINDEX始终是非并发的,因为没有其他会话可以访问它们,并且非并发重新索引更便宜。
VERBOSE
在每个索引被重建时打印进度报告。
4.示例
重建单个索引:
REINDEX INDEX my_index;
重建表my_table上的所有索引:
REINDEX TABLE my_table;
重建一个特定数据库中的所有索引,且不假设系统索引已经可用:
$ export PGOPTIONS="-P"
$ psql broken_db
...
broken_db=> REINDEX DATABASE broken_db;
broken_db=> \q
重建表的索引,在重建索引过程中不阻止对相关关系进行读写操作:
REINDEX TABLE CONCURRENTLY my_broken_table;
5.日常重建索引
在某些情况下值得周期性地使用REINDEX命令或一系列独立重构步骤来重建索引。
已经完全变成空的B树索引页面被收回重用。但是,还是有一种低效的空间利用的可能性:如果一个页面上除少量索引键之外的全部键被删除,该页面仍然被分配。因此,在这种每个范围中大部分但不是全部键最终被删除的使用模式中,可以看到空间的使用是很差的。对于这样的使用模式,推荐使用定期重索引。
对于非B树索引可能的膨胀还没有很好地定量分析。在使用非B树索引时定期监控索引的物理尺寸是个好主意。
还有,对于B树索引,一个新建立的索引比更新了多次的索引访问起来要略快, 因为在新建立的索引上,逻辑上相邻的页面通常物理上也相邻(这样的考虑目前并不适用于非B树索引)。仅仅为了提高访问速度也值得定期重索引。
REINDEX在所有情况下都可以安全和容易地使用。 默认情况下,此命令需要一个ACCESS EXCLUSIVE锁,因此通常最好使用CONCURRENTLY选项执行它,该选项仅需要获取SHARE UPDATE EXCLUSIVE锁。
6. 注解
如果怀疑一个用户表上的索引损坏,可以使用 REINDEX INDEX或者 REINDEX TABLE简单地重建该索引 或者表上的所有索引。
如果你需要从一个系统表上的索引损坏中恢复,就更困难一些。在 这种情况下,对系统来说重要的是没有使用过任何可疑的索引本身( 实际上,这种场景中,你可能会发现服务器进程会在启动时立刻崩溃, 这是因为对于损坏的索引的依赖)。要安全地恢复,服务器必须用 -P选项启动,这将阻止它使用索引来进行系统 目录查找。
这样做的一种方法是关闭服务器,并且启动一个单用户的 PostgreSQL服务器,在其命令行 中包括-P选项。然后,可以发出 REINDEX DATABASE、REINDEX SYSTEM、 REINDEX TABLE或者REINDEX INDEX, 具体使用哪个命令取决于你想要重构多少东西。如果有疑问,可以使用 REINDEX SYSTEM来选择重建数据库中的所有系统索引。 然后退出单用户服务器会话并且重启常规的服务器。更多关于如何与 单用户服务器接口交互的内容请见postgres参考页。
在另一种方法中,可以开始一个常规的服务器会话,在其命令行选项 中包括-P。这样做的方法与客户端有关,但是在 所有基于libpq的客户端中都可以在开始客户端 之前设置PGOPTIONS环境变量为-P。 注意虽然这种方法不要求用锁排斥其他客户端,在修复完成之前避免 其他用户连接到受损的数据库才是更加明智的。
REINDEX类似于删除索引并且重建索引,在其中 索引内容会被从头开始建立。不过,锁定方面的考虑却相当不同。 REINDEX会用锁排斥写,但不会排斥在索引的父表上的读。 它也会在被处理的索引上取得一个排他锁,该锁将会阻塞对该索引的使用尝试。 相反,DROP INDEX 会暂时在附表上取得一个排他锁,阻塞 写和读。后续的CREATE INDEX会排斥写但不排斥读,由于 该索引不存在,所以不会有读取它的尝试,这意味着不会有阻塞但是读操作可能 被强制成昂贵的顺序扫描。
重索引单独一个索引或者表要求用户是该索引或表的拥有者。对方案或数据库重建索引要求是该方案或者数据库的拥有者。请特别注意,因此非超级用户有时无法重建其他用户拥有的表上的索引。不过,作为一种特例,当一个非超级用户发出REINDEX DATABASE、REINDEX SCHEMA或者REINDEX SYSTEM时,共享目录上的索引将被跳过,除非该用户拥有该目录(通常不会是这样)。当然,超级用户总是可以重建所有的索引。
不支持重建分区表的索引或者分区索引。不过可以单独为每个分区重建索引。
7. Rebuilding Indexes Concurrently
重建索引可能会影响数据库的常规操作。通常PostgreSQL会锁定重建的表以防止写操作,并通过单次扫描表来执行整个索引构建。 其他事务仍可以读取表,但如果它们尝试在表中插入、更新或删除行,它们将被阻止,直到索引重建完成。 如果系统是实时生产数据库,这可能会产生严重影响。非常大的表可能需要几个小时才能编制索引,即使对于较小的表,索引重建也会锁定编写器,这些时间段对于生产系统来说是不可接受的。
PostgreSQL支持以最少的写入锁定来重建索引。此方法通过指定REINDEX的CONCURRENTLY选项来调用。 使用此选项时,PostgreSQL必须对需要重新生成的每个索引执行两次表扫描,并等待可能使用索引的所有现有事务的终止。 此方法需要比标准索引重建更大的工作量,并且需要相当长的时间才能完成,因为它需要等待可能修改索引的未完成的事务。 但是,由于它允许在重建索引时继续正常操作,此方法可用于在生产环境中重建索引。当然,重建索引所需的额外 CPU、内存和 I/O 负载可能会减慢其他操作的速度。
以下步骤发生在并发重建索引中。 每个步骤在单独的事务中运行。 如果要重建多个索引,则每个步骤在进入到下一步之前都要循环遍历所有索引。
-
新的临时索引定义将添加到目录pg_index中。 此定义将用于替换旧索引。 一个SHARE UPDATE EXCLUSIVE会话级别的锁将放在要重建的索引以及其关联的表上,以防止处理时的任何模式修改。
-
为每个新索引完成生成索引的首个操作。 生成索引后,其标志pg_index.indisready切换到“true”使其准备好插入,使其在执行生成的事务完成后对其他会话可见。 此步骤在每个索引的单独事务中完成。
-
然后执行第二个操作以添加在第一个操作运行时添加的元组。此步骤也在每个索引的单独事务中完成。
-
引用索引的所有约束都已更改以引用新的索引定义,并且索引名称也已经更改。 此时,pg_index.indisvalid会为新索引切换到“true”,以及为旧索引切换到“false”,并且缓存无效会导致引用旧索引的所有会话失效。
-
旧索引有pg_index.indisready切换到“false”以防止任何新的元组插入,在等待可能引用旧索引的查询之后完成。
-
旧索引被丢弃。索引和表的SHARE UPDATE EXCLUSIVE会话锁被释放。
如果在重建索引时出现问题,例如唯一索引中的唯一性冲突, REINDEX命令将失败,但会留下一个 “invalid”新索引,在已经存在的索引之外。 出于查询目的此索引将被忽略,因为它可能不完整;但是它仍将消耗更新开销。psql \d命令将此类索引报告为 INVALID:
postgres=# \d tab
Table "public.tab"
Column | Type | Modifiers
--------+---------+-----------
col | integer |
Indexes:
"idx" btree (col)
"idx_ccnew" btree (col) INVALID
如果标记为INVALID的索引后缀为ccnew,那么它对应的是并发操作时创建的临时索引,推荐的恢复方法是使用DROP INDEX删除,然后再次尝试 REINDEX CONCURRENTLY。 如果无效索引改为后缀ccold,则对应于无法删除的原始索引; 推荐的恢复方法是删除所述索引,因为正确的重建已经成功。
常规索引创建允许在同一表上的其他常规索引创建同时发生,但在一个表上一次只能发生一个并发索引创建。在这两种情况下,不允许同时对表上其他类型的模式进行修改。 另一个区别是,常规REINDEX TABLE或REINDEX INDEX命令可以在事务块中执行,但REINDEX CONCURRENTLY不能执行。
REINDEX SYSTEM 不支持 CONCURRENTLY 因为系统目录不能并发重新索引。
此外,排除约束的索引不能并发重新编制索引。 如果此命令中直接命名了这样的索引,则会引发错误。 如果并发重新编制具有排除约束索引的表或数据库,将跳过这些索引。 (它可以不使用CONCURRENTLY选项来重新编制这样的索引)。
reindexdb
reindexdb — 重索引一个PostgreSQL数据库
大纲
reindexdb [connection-option...] [option...] [ --schema | -S schema ] ... [ --table | -t table ] ... [ --index | -i index ] ... [dbname]
reindexdb [connection-option...] [option...] --all | -a
reindexdb [connection-option...] [option...] --system | -s [dbname]
描述
reindexdb是用于重建一个PostgreSQL数据库中索引的工具。
reindexdb是 SQL 命令REINDEX的一个包装器。在通过这个工具和其他方法访问服务器来重索引数据库之间没有实质性的区别。
参数
reindexdb接受下列命令行参数:
-a
–all
重索引所有数据库。
–concurrently
使用 CONCURRENTLY 选项。 请参阅 REINDEX,其中详细解释了此选项的所有注意事项。
[-d] dbname
[–dbname=]dbname
当 -a/–all 未使用时,指定要重新索引的数据库的名称。 如果未指定,则从环境变量 PGDATABASE 中读取数据库名称。 如果未设置,则使用为连接指定的用户名。 dbname 可以是 连接字符串。 如果是这样,连接字符串参数将覆盖任何冲突的命令行选项。
-e
–echo
回显reindexdb生成并发送到服务器的命令。
-i index
–index=index
只是重建index。可以通过写多个-i开关来重建多个索引。
-j njobs
–jobs=njobs
通过同时运行 njobs 命令并行执行 reindex 命令。 此选项可能会减少处理时间,但也会增加数据库服务器上的负载。
reindexdb将打开到数据库的njobs连接,因此请确保max_connections设置足够高,可以容纳所有连接。
请注意,此选项与 --index 和 --system 选项不兼容。
-q
–quiet
不显示进度消息。
-s
–system
索引数据库的系统目录。
-S schema
–schema=schema
只对schema重建索引。 通过写多个-S开关可以指定多个要重建索引的模式。
-t table
–table=table
只索引table。可以通过写多个-t开关来重索引多个表。
-v
–verbose
在处理时打印详细信息。
-V
–version
打印reindexdb版本并退出。
-?
–help
显示有关reindexdb命令行参数的帮助并退出。
reindexdb也接受下列命令行参数用于连接参数:
-h host
–host=host
指定运行服务器的机器的主机名。如果该值以一个斜线开始,它被用作 Unix 域套接字的目录。
-p port
–port=port
指定服务器正在监听连接的 TCP 端口或本地 Unix 域套接字文件扩展。
-U username
–username=username
要作为哪个用户连接。
-w
–no-password
从不发出一个口令提示。如果服务器要求口令认证并且没有其他方式提供口令(例如一个.pgpass文件),那儿连接尝试将失败。这个选项对于批处理任务和脚本有用,因为在其中没有一个用户来输入口令。
-W
–password
强制reindexdb在连接到一个数据库之前提示要求一个口令。
这个选项不是必不可少的,因为如果服务器要求口令认证,reindexdb将自动提示要求一个口令。但是,reindexdb将浪费一次连接尝试来发现服务器想要一个口令。在某些情况下值得用-W来避免额外的连接尝试。
–maintenance-db=dbname
当使用 -a/–all 时,指定要连接到的数据库名称以发现应重新索引哪些数据库。 如果未指定,将使用 postgres 数据库, 如果不存在,将使用 template1。 这可以是连接字符串。 如果是这样,连接字符串参数将覆盖任何冲突的命令行选项。 此外,在连接到其他数据库时,将重新使用除数据库名称本身之外的连接字符串参数。
[root@localhost ~]# reindexdb --help
reindexdb 对一个PostgreSQL 数据库重新创建索引.
使用方法:
reindexdb [选项]... [数据库名字]
选项:
-a, --all 对所有数据库进行重建索引操作
--concurrently 同时重新索引
-d, --dbname=DBNAME 对数据库中的索引进行重建
-e, --echo 显示发送到服务端的命令
-i, --index=INDEX 仅重新创建指定的索引
-j, --jobs=NUM 使用这么多并发连接来重新创建索引
-q, --quiet 不写任何信息
-s, --system reindex system catalogs only
-S, --schema=SCHEMA 只对指定模式重建索引
-t, --table=TABLE 只对指定的表重新创建索引
--tablespace=TABLESPACE 重建索引的表空间
-v, --verbose 写大量的输出
-V, --version 输出版本信息, 然后退出
-?, --help 显示此帮助, 然后退出
联接选项:
-h, --host=HOSTNAME 数据库服务器所在机器的主机名或套接字目录
-p, --port=PORT 数据库服务器端口号
-U, --username=USERNAME 联接的用户名
-w, --no-password 永远不提示输入口令
-W, --password 强制提示输入口令
--maintenance-db=DBNAME 更改维护数据库
阅读SQL命令REINDEX的描述信息, 以便获得更详细的信息.
臭虫报告至<pgsql-bugs@lists.postgresql.org>.
PostgreSQL 主页: <https://www.postgresql.org/>
示例
要重索引数据库test:
$ reindexdb test
要重索引名为abcd的数据库中的表foo和索引bar:
$ reindexdb --table foo --index bar abcd
九 索引的优缺点
索引的负面影响和相关成本
- 一个系统,单个表有400多个字段,表上面有40多个索引,并且大量的索引是组合索引,日积月累就造成很多无效索引,对于维护重建索引非常耗时
- 索引通常被认为是SQL性能调优的灵丹妙药,且PG数据库支持各种各样的索引来满足不同的场景。我们经常看到许多关于调优的文章和讨论,讨论如何创建索引来加速SQL,但是很少有人讨论删除它们。偶然看到一篇文章发现正是说出了心中想要说的,便记录下来
- 创建越来越多的索引正在对许多系统造成严重损害,很多时候为了系统的稳定性,在考虑任何新索引之前,我们应该首先分析系统已有的索引,删除那些没用的索引,了解索引的后果和开销有助于做出明智的决定,并有可能是系统免于许多潜在的问题。
- 索引不是免费的,这些好处伴随着性能和资源消耗方面的成本,以下是过渡使用索引可能导致的问题,这篇文章是关于PostgreSQL的,但大多数问题也适用于其他数据库系统
危害
指数级的开销
添加索引后,我们可能会看到select 语句的性能有所提高。但性能的提升伴随着同一张表上事务的成本。从概念上讲表上的每个DML都需要更新表的所有索引。尽管有很多优化来减少写放大,但是这是一个相当大的开销。
例如,加入有一张表有五个索引,对表的每个insert都会导致对着5个索引的索引记录的insert。逻辑上,五个索引页面也将被更新,开销是5倍
内存使用
索引必须在内存中,无论是否有任何查询使用它们,因为它们需要由事务更新。实际上,可用于表页的内存变小了。索引越多,有效缓存所需要的内存就越大。如果我们不增加可用内存,就会开始损害系统的整体性能。
随机写:更新索引成本高
与将新记录插入表不同,行不太可能被插入到同一页中。众所周知,像b-tree索引这样的索引会导致更多的随机写入。
索引比表需要更多的缓存
由于随机写入和读取,索引需要更多的页面在缓存中。索引的缓存要求通常比关联表高得多
WAL生成
除了表更新的WAL记录外,还会有索引的WAL记录。这是因为有助于崩溃恢复和复制,如果我们使用pg_gather工具进行分析,WAL生成的开销将清晰可见,实际影响屈居于索引类型
越来越多的I/O
不仅生成WAL记录,也会有更多的页被弄脏,随着索引页变脏,必须要将其写会文件,从而再次导致了更多的I/O,——“ DataFileWrite ”等待事件。
另一个副作用是索引增加了活动数据集的总大小。“活动数据集”是指经常查询和使用的表和索引。随着活动数据集大小的增加,缓存的效率也越来越低。缓存效率低会导致读取更多的数据文件,因此读取I/O会增加。这是为特定查询从存储中获取额外的索引页所需要的读取I/O的补充。
另一个主要是选择查询的系统的 pg_gather 报告再次显示了这个问题。随着活动数据集的增加,PostgreSQL 别无选择,只能从存储中取出页面。
持续时间较长的 DataFileRead 百分比越大,表明活动数据集越大,不可缓存。
对VACUUM/AUTOVACUUM的影响
开销不仅用于插入或更新索引页。维护也会产生开销,因为索引还需要清理旧的元组引用
由于表的大小,而且最重要的是,表上的索引数量过多,单个表上的 autovacuum worker 运行时间很长。事实上,用户经常看到他们的 autovacuum worker 被“卡住”数小时而没有在更长的时间内显示任何进展。
autovacuum操作也会读索引进行清理,可以通过pg_stat_progress_vacuum观察:https://www.postgresql.org/docs/current/progress-reporting.html#VACUUM-PROGRESS-REPORTING
随着时间的推移,索引会变得臃肿并且效率降低。许多系统可能需要定期索引维护 (REINDEX)。
因小失大
- 有时候我们发现局部有问题,解决局部的问题实际上对整体带来了更大的问题
用户可能专注于特定的SQL语句,试图调整并决定创建索引。通过创建用于调整查询的索引,我们将更多的系统资源转移到该查询。然后可能会引起整体性能下降
随着我们不断创建越来越多的索引来调整其他查询,资源将再次转向其他查询。最终整体的性能逐渐下降,最终每个使用系统的人都会受到伤害。尝试调整的人应该考虑系统的每个部分如何共存(最大化业务价值)而不是特定查询的绝对性能
更大的存储需求
总数据库的大小比实际大,备份需要耗费更多的时间,存储和网络资源,同样的备份会给主机带来更多的负载。这也会增加还原备份和恢复备份的时间。更大的数据库也就需要更多的时间来构建备用实例
索引更容易膨胀
PostgreSQL 14 的静默索引损坏或由于glibc 排序规则更改导致的索引损坏,这些错误时不时地出现并影响许多环境,即使在今天。在使用数据库数十年的时间里,我观察到索引损坏的报告更加频繁。(我希望任何参与 PostgreSQL 多年并见过数百个案例的人都会同意我的看法)。随着索引数量的增加,损坏的概率也在增加
改进的
需要思考的点:
- 是否必须有这个索引或者是否有必要以更多索引为代价来加快速度
- 有没有办法重写查询以获取更好的性能
- 当新增一个索引,是否其他索引就可以删除?
- 对于现有的索引:检查无用的索引,并定期删除(pg_stat_user_indexes中idx_scan为0的索引)。类似pgexperts的脚本可以帮助进行更多分析
即将发布的 PostgreSQL 16 在pg_stat_user_indexes / pg_stat_all_indexes中多了一列, 名称为last_idx_scan,它可以告诉我们最后一次使用索引的时间(时间戳)。这将帮助我们全面了解系统中的所有索引。
总结
用简单的话总结:索引并不便宜,索引是有代价的,而且代价是多方面的,索引并不总是好的,顺序扫描也不总是坏的。避免改进因为改进单个查询而影响到整体性能下降。从调整主机、操作系统、PostgreSQL参数等开始调整系统的自上而下方法会产生更好的结果。再创建索引前进行客观的“成本效益分析”很重要
查询未使用索引:
SELECT
schemaname || '.' || relname AS table,
indexrelname AS index,
pg_size_pretty(pg_relation_size(i.indexrelid)) AS index_size,
idx_scan as index_scans
FROM pg_stat_user_indexes ui
JOIN pg_index i ON ui.indexrelid = i.indexrelid
WHERE NOT indisunique AND idx_scan < 50
AND pg_relation_size(relid) > 5 * 8192
ORDER BY pg_relation_size(i.indexrelid) / nullif(idx_scan, 0) DESC NULLS FIRST,
pg_relation_size(i.indexrelid) DESC;
在 PostgreSQL 中,WAL(Write-Ahead Logging)是一种机制,用于确保数据的持久性和一致性。WALWrite 和 WALSync 都是与 WAL 相关的操作,但它们的作用和含义略有不同。
1、WALWrite
WALWrite 是指将 WAL 缓冲区中的数据写入到 WAL 文件中的操作。当 PostgreSQL 执行写入操作时,数据首先会被写入到 WAL 缓冲区中,然后再由 WALWriter 进程将数据写入到 WAL 文件中。WALWrite 操作的目的是将数据从内存中写入到磁盘中,以确保数据的持久性。
2、WALSync
WALSync 是指将 WAL 文件中的数据同步到磁盘上的操作。当 PostgreSQL 执行 WALWrite 操作时,数据会被写入到 WAL 文件中,但并不一定会立即同步到磁盘上。WALSync 操作的目的是将 WAL 文件中的数据同步到磁盘上,以确保数据的一致性和可靠性。
因此,WALWrite 和 WALSync 的区别在于它们的作用和含义不同。WALWrite 是将数据从内存中写入到 WAL 文件中,而 WALSync 是将 WAL 文件中的数据同步到磁盘上。
WALWrite 操作通常比 WALSync 操作更频繁,因为 WAL 缓冲区中的数据需要定期写入到 WAL 文件中,而 WAL 文件中的数据则需要在适当的时候同步到磁盘上。
需要注意的是,WALWrite 和 WALSync 操作都会对系统的性能产生影响,因为它们都需要进行磁盘 I/O 操作。为了提高系统的性能和稳定性,可以采取一些措施,例如调整 WAL 缓冲区的大小、调整 WALSync 的频率、使用更快的磁盘等