Elasticsearch【文档操作、搜索操作、入门案例】(五)-全面详解(学习总结---从入门到深化)

目录
原生JAVA操作ES_文档操作
原生JAVA操作ES_搜索操作
SpringDataES_入门案例
原生JAVA操作ES_文档操作

新增&修改文档
@Test
public void addDocument() throws IOException
{
// 1.创建客户端对象,连接ES
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.0.187", 9200, "http")));
// 2.创建请求对象
IndexRequest request = new IndexRequest("student").id("1");
request.source(XContentFactory.jsonBuilder()
.startObject()
.field("id", 1)
.field("name", "i love xiaotong")
.field("age", 20)
.endObject());
// 3.发送请求
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 4.操作响应结果
System.out.println(response.status());
// 5.关闭客户端
client.close();
}根据id查询文档
// 根据id查询文档
@Test
public void findByIdDocument() throws IOException {
// 1.创建客户端对象,连接ES
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.0.187", 9200, "http")));
// 2.创建请求对象
GetRequest request = new GetRequest("student", "1");
// 3.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 4.操作响应结果
System.out.println(response.getSourceAsString());
// 5.关闭客户端
client.close();
}
删除文档
// 删除文档
@Test
public void DeleteDocument() throws IOException {
// 1.创建客户端对象,连接ES
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.0.187", 9200, "http")));
// 2.创建请求对象
DeleteRequest request = new DeleteRequest("student", "1");
// 3.发送请求
DeleteResponse response = client.delete(request,RequestOptions.DEFAULT);
// 4.操作响应结果
System.out.println(response.status());
// 5.关闭客户端
client.close();
}实时学习反馈
1. 使用原生JAVA操作ES时,删除文档的请求对象为
A DeleteRequest
B GetRequest
C IndexRequest
D SearchRequest
2. 使用原生JAVA操作ES时,新增文档的请求对象为
A DeleteRequest
B GetRequest
C IndexRequest
D SearchRequest
原生JAVA操作ES_搜索操作

搜索所有文档
@Test
public void queryAllDocument() throws IOException {
// 创建客户端对象,链接ES
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.1.58",9200,"http")));
// 创建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery());
// 创建请求对象
SearchRequest request = new SearchRequest("student").source(searchSourceBuilder);
// 发送请求
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
// 输出返回结果
for (SearchHit hit:response.getHits()) {
System.out.println(hit.getSourceAsString());
}
// 关闭客户端
client.close();
}根据关键词搜索文档
@Test
public void queryTermDocument() throws IOException {
// 创建客户端对象,链接ES
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("192.168.1.58",9200,"http")));
// 创建请求条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("info","boy"));
// 创建请求对象
SearchRequest request = new SearchRequest("student").source(searchSourceBuilder);
// 发送请求
SearchResponse response = client.search(request,RequestOptions.DEFAULT);
// 输出返回结果
for (SearchHit hit:response.getHits()) {
System.out.println(hit.getSourceAsString());
}
// 关闭客户端
client.close();
}实时学习反馈
1. 使用原生JAVA操作ES时,查询文档的请求对象为
A DeleteRequest
B GetRequest
C IndexRequest
D SearchRequest
SpringDataES_入门案例

项目搭建
Spring Data ElasticSearch是Spring对原生JAVA操作Elasticsearch 封装之后的产物。它通过对原生API的封装,使得JAVA程序员可以简 单的对Elasticsearch进行操作。
1、创建SpringBoot项目,加入Spring Data Elasticsearch起步依赖:
org.springframework.boot
spring-boot-starter-data-elasticsearch
2、编写配置文件:
spring:
elasticsearch:
uris: http://192.168.1.58:9200此时Spring Data ElasticSearch项目已经搭建完成。
创建实体类
一个实体类的所有对象都会存入ES的一个索引中,所以我们在创建 实体类时关联ES索引。
@Document(indexName = "product",createIndex = true)
@Data
public class Product {
@Id
@Field(type = FieldType.Integer,store = true,index = true)
private Integer id;
@Field(type = FieldType.Text,store = true,index = true,analyzer = "ik_max_word",searchAnalyzer = "ik_max_word")
private String productName;
@Field(type = FieldType.Text,store = true,index = true,analyzer ="ik_max_word",searchAnalyzer = "ik_max_word")
private String productDesc;
}
@Document:标记在类上,标记实体类为文档对象,一般有如 下属性:
indexName:对应索引的名称
createIndex:是否自动创建索引
@Id:标记在成员变量上,标记一个字段为主键,该字段的值会 同步到ES该文档的id值。
@Field:标记在成员变量上,标记为文档中的域,一般有如下 属性:
type:域的类型
index:是否创建索引,默认是 true store:是否单独存储,默认是 false
analyzer:分词器
searchAnalyzer:搜索时的分词器
实时学习反馈
1. 在Spring Data ElasticSearch中,实体类上方添加的注解为
A @Entity
B @Bean
C @Document
D @Repository
2. 在Spring Data ElasticSearch中,实体类成员变量上方添加的 注解为
A @Field
B @Bean
C @Document
D @Id
复习:
Elasticsearch常用操作_域的属性
index
该域是否创建索引。只有值设置为true,才能根据该域的关键词查询文档。
// 根据关键词查询文档
GET /索引名/_search
{
"query":{
"term":{
搜索字段: 关键字
}
}
}type
域的类型
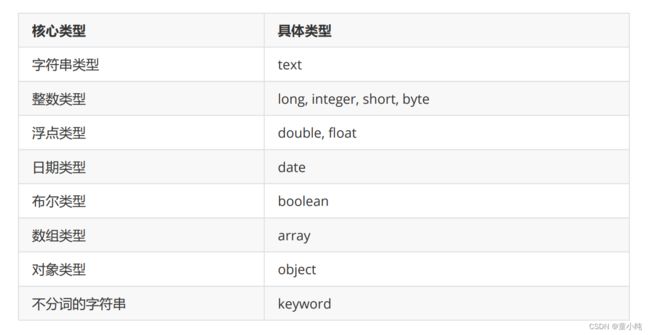
store
是否单独存储。如果设置为true,则该域能够单独查询。
// 单独查询某个域:
GET /索引名/_search
{
"stored_fields": ["域名"]
}
实时学习反馈
1. 在Elasticsearch中,只有域的属性设置为true,才能根据该域 的关键词查询文档
A type
B index
C store
D analyzer
2. 在Elasticsearch中,域的属性表示域的数据类型
A type
B index
C store
D analyzer
分词器_默认分词器

ES文档的数据拆分成一个个有完整含义的关键词,并将关键词与文 档对应,这样就可以通过关键词查询文档。要想正确的分词,需要 选择合适的分词器。
standard analyzer:Elasticsearch默认分词器,根据空格和标点 符号对英文进行分词,会进行单词的大小写转换。
默认分词器是英文分词器,对中文的分词是一字一词。
查看分词效果
GET /_analyze
{
"text":测试语句,
"analyzer":分词器
}实时学习反馈
1. 在Elasticsearch中,默认分词器为
A standard analyzer
B IKAnalyzer
C pinyin analysis
D 没有默认分词器
2. 在Elasticsearch中,默认分词器对中文的分词
A 根据标点符号分词
B 根据空格符号分词
C 根据词汇分词
D 一字一词
分词器_IK分词器

IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词 工具包。提供了两种分词算法:
1、ik_smart:最少切分
2、ik_max_word:最细粒度划分
安装IK分词器
1、关闭es服务
2 、使用rz命令将ik分词器上传至虚拟机
注:ik分词器的版本要和es版本保持一致。
3、解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-ik-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis -ik
4、启动ES服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch -d测试分词器效果
GET /_analyze
{
"text":"测试语句",
"analyzer":"ik_smart/ik_max_word"
}
IK分词器词典
IK分词器根据词典进行分词,词典文件在IK分词器的config目录中。
1、main.dic:IK中内置的词典。记录了IK统计的所有中文单词。
2、IKAnalyzer.cfg.xml:用于配置自定义词库。
IK Analyzer 扩展配置
ext_dict.dic
ext_stopwords.dic
实时学习反馈
1. IK分词器的算法分为
A ik_smart 和 ik_min_word
B ik_min_word 和 ik_max_word
C ik_smart 和 ik_max_word
D ik_smart 和 ik_max_word 和 ik_min_word
2. 在Elasticsearch中,测试分词器效果的方法为
A PUT /_analyze
B GET /_analyze
C POST /_analyze
D DELETE /_analyze
分词器_拼音分词器
拼音分词器可以将中文分成对应的全拼,全拼首字母等。
安装拼音分词器
1、 关闭es服务
2 、使用rz命令将拼音分词器上传至虚拟机
注:拼音分词器的版本要和es版本保持一致。
3、解压ik分词器到elasticsearch的plugins目录下
unzip elasticsearch-analysis-pinyin-7.17.0.zip -d /usr/local/elasticsearch1/plugins/analysis -pinyin
4、启动ES服务
su es
#进入ES安装文件夹:
cd /usr/local/elasticsearch1/bin/
#启动ES服务:
./elasticsearch
测试分词效果
GET /_analyze
{
"text":测试语句,
"analyzer":pinyin
}实时学习反馈
1. 在Elasticsearch中,分词器存放的目录为
A bin
B config
C plugins
D log